Заполнение пропусков по ближайшим соседям
Заполнение пропущенных значений является во многом творческой задачей. Наиболее популярными кандидатами, как правило, являются среднее, медиана, ноль. Однако в этой статья расскажу про более продвинутый и в то же время такой же легкий способ — заполнение по среднему среди наиболее похожих точек. Рассмотрим датафрейм:
import numpy as np import pandas as pd df = pd.DataFrame([[12, np.nan, 24], [1, 2, 3], [6, 3, np.nan], [1, 6, 8]]) df
Для заполнения воспользуемся классом KNNImputer из модуля sklearn.impute:
from sklearn.impute import KNNImputer imp = KNNImputer(n_neighbors=2) imp.fit_transform(df)
В качестве метрики для вычисления ближайших точек используется nan_euclidean ( подробнее описывал здесь ). Первое значение заполнено 4.5, так как это среднее между вторыми координатами для второй и третьей точек:
from sklearn.metrics.pairwise import nan_euclidean_distances nan_euclidean_distances(X=[df.iloc[0]], Y=df.iloc[1:])
А 5.5 — это среднее между третьими координатами первой и третьей точек:
nan_euclidean_distances(X=[df.iloc[2]], Y=df.drop(2))
Не забывайте, что корректное определение ближайших соседей напрямую зависит от предобработки данных, поступающих в евклидову метрику. В частности, требуется преобразование категориальных переменных и шкалирование числовых. О том, как это делать писал ранее:
Восстановление (импутация) данных с помощью Python

На данный момент Python является самым популярным языком программирования, который применяется для анализа данных или в машинном обучении. Сильными сторонами Python являются его модульность и возможность интегрироваться с другими языками программирования.
В науке о данных разведочный анализ данных (exploratory data analysis, EDA) является самым важным этапом в проекте и занимает около 70-80% времени всего проекта. Такой анализ позволяет изучить какие-то свойства данных, найти в них закономерности, аномалии, очистить их, подготовить и построить начальные модели для дальнейшей работы. На этом этапе можно определить вид распределения, оценить основные его параметры, обнаружить выбросы, построить матрицу корреляции признаков и т.д.
И в предварительном анализе достаточно серьезной проблемой является обнаружение недостающих (пропущенных) значений и самым сложным является то, что здесь нет какого-то универсального алгоритма. Для каждой конкретной задачи приходится искать наиболее подходящие методы или их комбинации.
Так как большинство моделей машинного обучения не могут обрабатывать пропущенные значения, значит их нельзя игнорировать в данных и эту проблему необходимо решать во время предобработки. Самым простым решением является удаление каждого наблюдения, содержащего одно или несколько пропущенных значений. Эта задача быстро и легко выполняется с помощью библиотек Numpy или pandas.
Вместе с этим необходимо стараться воздерживаться от удаления наблюдений с отсутствующими значениями. Их удаление является крайним средством, поскольку тогда алгоритм теряет доступ к полезной информации, содержащейся в непропущенных значениях наблюдений.
Можно выделить следующие основные стратегии замены пропущенных данных подстановочными значениями.
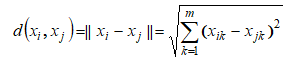
- Заменить пропущенные значения средним/медианой. В данном случае необходимо вычислить среднее/медиану имеющихся значений для каждого столбца и вставить то, что получилось в пропущенные ячейки. Данный метод является простым и быстрым, но не работает с качественными переменными. Также невозможно оценить погрешность импутации.
- Замена самым часто встречающимся значением или константой. Также является еще одним простым методом импутации. Можно использовать для качественных переменных
- Замена данных, используя метод k ближайших соседей или kNN. Является самым популярным методом машинного обучения для решения задач классификации. Основан на оценивании сходства объектов. Используется функция расстояния Евклида
где x_ и x_ — к-е элементы векторов x_ и x_ соответственно
У какого класса выше значение близости, тот класс и присваивается новому объекту.
Тогда с помощью данного метода можно вычислить значения пропущенных атрибутов на основании дистанций от попавших в область объектов и соответствующих значений этого же атрибута у объектов
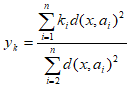
где a_ — i-ый объект, попавший в область, k_ — значение атрибута k у заданного объекта a_, x — новый объект, x_ — ый атрибут нового объекта.
Иным словами, выбирается k-точек, которые больше всего похожи на рассматриваемую, и уже на их основании выбирается значение для пустой ячейки.
Данный метод на некоторых наборах данных может быть точнее среднего/медианы или константы, учитывает корреляцию между параметрами. Главным недостатком данного метода является то, что он является вычислительно дорогим, так как требует держать весь набор данных в памяти, чтобы вычислить расстояние между пропущенным значением и каждым отдельным значением.
- Множественная импутация данных (MICE). Суть данного метода заключается в том, что импутация каждого значения проводится не один раз, а много. Такой тип замены пропущенных значений позволяет понять насколько надежно или ненадежно предложенное значений. Также, MICE, позволяет работать с переменным разных типов.
- Импутация данных с помощью глубоко обучения. Библиотека datawig позволяет восстанавливать недостающие значения за счет тренировки нейронной сети на тех точках, для которых есть все параметры.
Теперь попробуем разобрать некоторые возможности библиотек Phyton, которые помогут нам решить проблему недостающих значений. Для исследования необходимо выбрать набор данных (DataSet). Разнообразные наборы данных можно скачать с сайта (kaggle.com). Для демонстрации возможностей исследуем набор данных с информацией о диабете, где пациентами являются женщины не моложе 21 года индейского происхождения Пима.
Загружаем необходимые библиотеки и датасет
import pandas as pd import numpy as np data_diabetes = pd.read_csv('. /datasets/diabetes.csv') data_diabetes
Данный набор содержит следующие поля: Pregnancies (количество беременностей), Glucose (уровень глюкозы), BloodPressure (давление), SkinThickness (толщина кожной складки трицепса в мм), Insulin (уровень инсулина), BMI (индекс массы тела), DiabetesPedigree (функция наличия диабета у родственников), Age (возраст), Outcome (наличие диабета).
Посмотрим на основные характеристики, каждого признака.
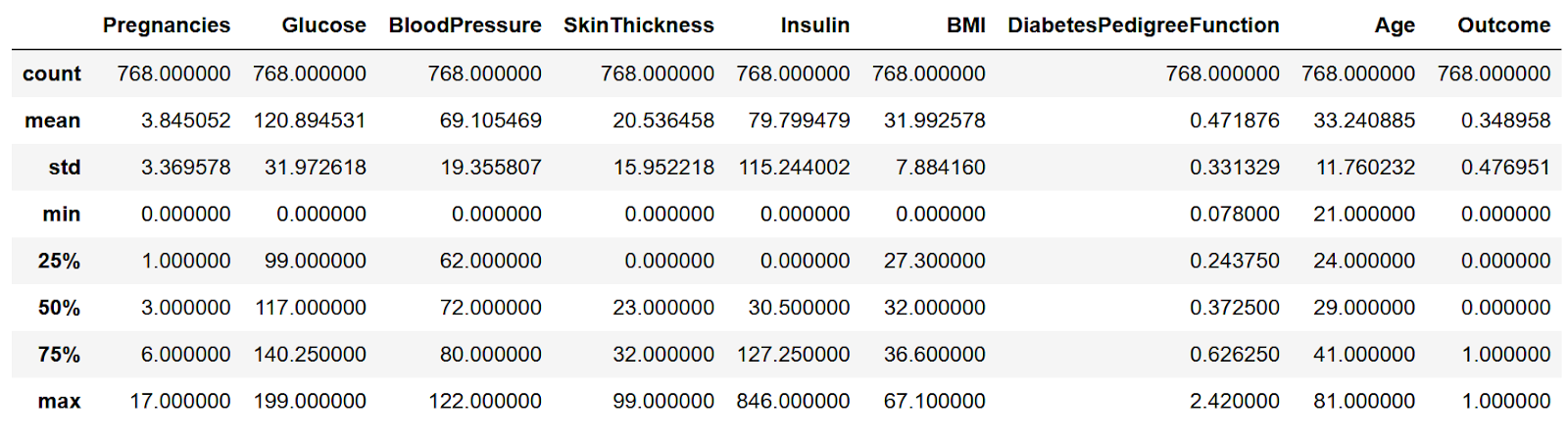
Можно увидеть, почти в каждом столбце есть нулевые значения. Посчитаем их количество
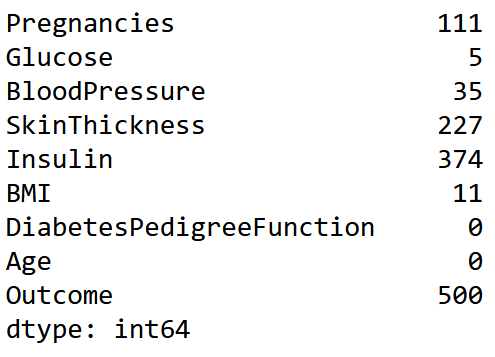
Можно предположить, что это пропущенные значения, где неизвестное значение было заменено нулем. Преобразуем все нули в значениях ‘Glucose’,’BloodPressure’,’SkinThickness’,’Insulin’,’BMI’ на значения NaN и еще раз посчитаем их количество, предварительно сделав копию нашего датасета.
new_data = data_diabetes.copy(deep = True) colsFix = ['Glucose','BloodPressure','SkinThickness','Insulin','BMI'] new_data [colsFix] = new_data[colsFix].replace(0, np.NaN) new_data.isnull().sum()
И еще раз посмотрим на характеристики датасета
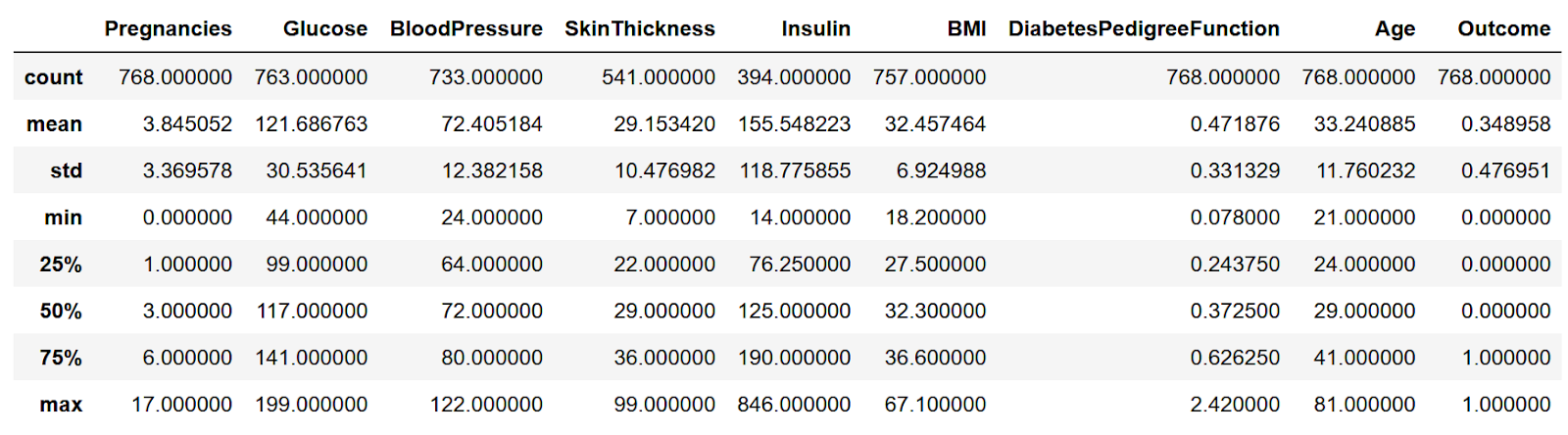
Почти в каждом столбце, кроме max произошли какие-то изменения.
Каким же образом можно проводить импутацию данных? Будем работать только со столбцами SkinThickness и Insulin, так как они имеют больше всего пропущенных значений.
1. В библиотеке Pandas (которая была уже загружена ранее) есть метод fillna(), который как раз позволяет заполнить пропущенные значения.
Синтаксис метода следующий
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)Наверное, нет смысла описывать все параметры этого метода. Описание можно посмотреть здесь.
Важно, что данный метод возвращает объект, в котором заполняются все пропущенные значения. Можно заменить пропущенные значения, например, средним, медианой, самым часто встречающимся значением, константой.
Вычисли эти значения, а затем заменим пропущенные значения медианой используя метод fillna.
Самое часто встречающееся значение