- Decode HTML entities into Python String
- Example: Use HTML Parser to decode HTML Entities
- Example: Use Beautiful Soup to decode HTML Entities
- Example: Use w3lib.html Library to decode HTML Entities
- Conclusion
- How to Convert HTML to Text with Python and Pandas
- 2. Setup
- Step 1: Install Beautiful Soup library
- Step 2: Extract text from HTML tags by Python
- Step 3: HTML to raw text in Pandas
- Conclusion
Decode HTML entities into Python String
In this article, we will learn to decode HTML entities into Python String. We will use some built-in functions and some custom code as well.
Let us discuss decode HTML scripts or entities into Python String. It increases the readability of the script. A programmer who does not know about HTML script can decode it and read it using Strings. So, these three methods will decode the ASCII characters in an HTML script into a Special Character.
Example: Use HTML Parser to decode HTML Entities
It imports html library of Python. It has html.unescape() function to remove and decode HTML entities and returns a Python String. It replaces ASCII characters with their original character.
import html print(html.unescape('£682m')) print(html.unescape('© 2010'))Example: Use Beautiful Soup to decode HTML Entities
It uses BeautifulSoup for decoding HTML entities.This represents Beautiful Soup 4 as it works in Python 3.x. For versions below this, use Beautiful Soup 3. For Python 2.x, you will need to specify the convertEntities argument to the BeautifulSoup constructor. But in the case of Beautiful Soup 4, entities get decoded automatically. html.parser is passed as an argument along with the HTML script to BeautifulSoup because it removes all the extraneous HTML that wasn’t part of the original string (i.e. and ).
# Beautiful Soup 4 from bs4 import BeautifulSoup print(BeautifulSoup("£682m", "html.parser"))Example: Use w3lib.html Library to decode HTML Entities
This method uses w3lib.html module. In order to avoid «ModuleNotFoundError«, install w3lib using pip install using the given command. It provides replace_entities to replace HTML script with Python String.

from w3lib.html import replace_entities print(replace_entities("£682m"))Conclusion
In this article, we learned to decode HTML entities into Python String using three built-in libraries of Python such as html , w3lib.html , and BeautifulSoup . We saw how HTML script is removed and replaced with ASCII characters. Install your packages correctly if you are getting «ModuleNot FoundError«.
How to Convert HTML to Text with Python and Pandas
In this short guide, we’ll see how to convert HTML to raw text with Python and Pandas. It is also known as text extraction from HTML tags.
2. Setup
In this Python guide, we’ll use the following DataFrame, which consists of two columns. Column html contains HTML tags and text inside the tags:
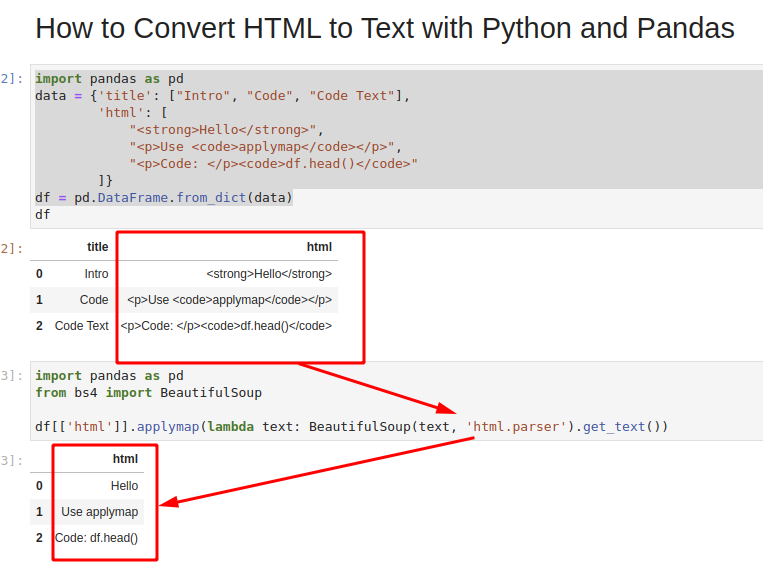
import pandas as pd data = Hello", "Use applymap
", "Code:
df.head()" ]> df = pd.DataFrame.from_dict(data) | title | html | |
|---|---|---|
| 0 | Intro | Hello |
| 1 | Code | Use |
| 2 | Code Text | Code: |
We would like to extract the raw text from the column without the HTML tags with Python:
| html | |
|---|---|
| 0 | Hello |
| 1 | Use applymap |
| 2 | Code: df.head() |
Step 1: Install Beautiful Soup library
First we will need to install Python library — beautifulsoup4 by:
pip install beautifulsoup4 The official documentation of the library is available on this link: Beautiful Soup Documentation.
The Beautiful Soup is described as:
Beautiful Soup is a Python library for pulling data out of HTML and XML files.
Step 2: Extract text from HTML tags by Python
Now let’s check how we can extract the text from HTML code or tags in Python. We will demonstrate the extraction in simple example.
Suppose we have the following HTML document:
html_doc = """
We can extract the raw text from the HTML tags by:
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'html.parser') print(soup.get_text()) The Dormouse's story The Dormouse's story Once upon a time there were three little sisters; and their names were Or we can pretty print the HTML code by:
Step 3: HTML to raw text in Pandas
In order to convert HTML to raw text we will apply BeautifulSoup library to Pandas column.
To apply the BeautifulSoup function soup.get_text() to Pandas column we can use the following code:
df[['html']].applymap(lambda text: BeautifulSoup(text, 'html.parser').get_text()) | html | |
|---|---|
| 0 | Hello |
| 1 | Use applymap |
| 2 | Code: df.head() |
How does it work? We are applying the function .get_text() with html.parser to each row from the DataFrame — df[[‘html’]] — in this case it has only a single column.
If we pass non HTML column or NaNs we will get errors.
Conclusion
In this post, we saw how to convert HTML tags or document into raw text with Python and Pandas.
We’ve learn also how to apply BeautifulSoup library function to Pandas DataFrame.
The image below shows all the steps which we covered:
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.