Индексы, срезы и итерация / np 4
В прошлых разделах вы узнали, как создавать массив и выполнять операции с ним. В этом — речь пойдет о манипуляции массивами: о выборе элементов по индексам и срезам, а также о присваивании для изменения отдельных значений. Наконец, узнаете, как перебирать их.
Индексы
При работе с индексами массивов всегда используются квадратные скобки ( [ ] ). С помощью индексирования можно ссылаться на отдельные элементы, выделяя их или даже меняя значения.
При создании нового массива шкала с индексами создается автоматически.
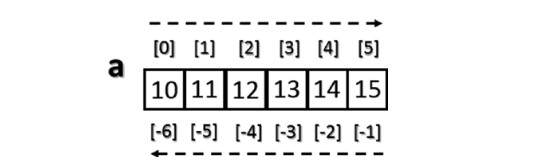
Для получения доступа к одному элементу на него нужно сослаться через его индекс.
>>> a = np.arange(10, 16) >>> a array([10, 11, 12, 13, 14, 15]) >>> a[4] 14 NumPy также принимает отрицательные значения. Такие индексы представляют собой аналогичную последовательность, где первым элемент будет представлен самым большим отрицательным значением.
Для выбора нескольких элементов в квадратных скобках можно передать массив индексов.
Двухмерные массивы, матрицы, представлены в виде прямоугольного массива, состоящего из строк и колонок, определенных двумя осями, где ось 0 представлена строками, а ось 1 — колонками. Таким образом индексация происходит через пару значений; первое — это значение ряда, а второе — колонки. И если нужно получить доступ к определенному элементу матрицы, необходимо все еще использовать квадратные скобки, но уже с двумя значениями.
>>> A = np.arange(10, 19).reshape((3, 3)) >>> A array([[10, 11, 12], [13, 14, 15], [16, 17, 18]]) Если нужно удалить элемент третьей колонки во второй строке, необходимо ввести пару [1, 2].
Срезы
Срезы позволяют извлекать части массива для создания новых массивов. Когда вы используете срезы для списков Python, результирующие массивы — это копии, но в NumPy они являются представлениями одного и того же лежащего в основе буфера.
В зависимости от части массива, которую необходимо извлечь, нужно использовать синтаксис среза; это последовательность числовых значений, разделенная двоеточием ( : ) в квадратных скобках.
Чтобы получить, например, часть массива от второго до шестого элемента, необходимо ввести индекс первого элемента — 1 и индекса последнего — 5, разделив их : .
>>> a = np.arange(10, 16) >>> a array([10, 11, 12, 13, 14, 15]) >>> a[1:5] array([11, 12, 13, 14]) Если нужно извлечь элемент из предыдущего отрезка и пропустить один или несколько элементов, можно использовать третье число, которое представляет собой интервал последовательности. Например, со значением 2 результат будет такой.
Чтобы лучше понять синтаксис среза, необходимо рассматривать и случаи, когда явные числовые значения не используются. Если не ввести первое число, NumPy неявно интерпретирует его как 0 (то есть, первый элемент массива). Если пропустить второй — он будет заменен на максимальный индекс, а если последний — представлен как 1. То есть, все элементы будут перебираться без интервалов.
>>> a[::2] array([10, 12, 14]) >>> a[:5:2] array([10, 12, 14]) >>> a[:5:] array([10, 11, 12, 13, 14] В случае с двухмерными массивами срезы тоже работают, но их нужно определять отдельно для рядов и колонок. Например, если нужно получить только первую строку:
>>> A = np.arange(10, 19).reshape((3, 3)) >>> A array([[10, 11, 12], [13, 14, 15], [16, 17, 18]]) >>> A[0,:] array([10, 11, 12]) Как видно по второму индексу, если оставить только двоеточие без числа, будут выбраны все колонки. А если нужно выбрать все значения первой колонки, то необходимо писать обратное.
Если же необходимо извлечь матрицу меньшего размера, то нужно явно указать все интервалы с соответствующими индексами.
Если индексы рядов или колонок не последовательны, нужно указывать массив индексов.
Итерация по массиву
В Python для перебора по элементам массива достаточно использовать такую конструкцию.
>>> for i in a: ... print(i) ... 10 11 12 13 14 15 Но даже здесь в случае с двухмерным массивом можно использовать вложенные циклы внутри for . Первый цикл будет сканировать ряды массива, а второй — колонки. Если применить цикл for к матрице, она всегда будет перебирать в первую очередь по строкам.
>>> for row in A: ... print(row) ... [10 11 12] [13 14 15] [16 17 18] Если необходимо перебирать элемент за элементом можно использовать следующую конструкцию, применив цикл for для A.flat :
>>> for item in A.flat: ... print(item) ... 10 11 12 13 14 15 68 16 17 18 Но NumPy предлагает и альтернативный, более элегантный способ. Как правило, требуется использовать перебор для применения функции для конкретных рядов, колонок или отдельных элементов. Можно запустить функцию агрегации, которая вернет значение для каждой колонки или даже каждой строки, но есть оптимальный способ, когда NumPy перебирает процесс итерации на себя: функция apply_along_axis() .
Она принимает три аргумента: функцию, ось, для которой нужно применить перебор и сам массив. Если ось равна 0, тогда функция будет применена к элементам по колонкам, а если 1 — то по рядам. Например, можно посчитать среднее значение сперва по колонкам, а потом и по рядам.
>>> np.apply_along_axis(np.mean, axis=0, arr=A) array([ 13., 14., 15.]) >>> np.apply_along_axis(np.mean, axis=1, arr=A) array([ 11., 14., 17.]) В прошлом примере использовались функции из библиотеки NumPy, но ничто не мешает определять собственные. Можно использовать и ufunc . В таком случае перебор по колонкам и по рядам выдает один и тот же результат. На самом деле, ufunc выполняет перебор элемент за элементом.
>>> def foo(x): ... return x/2 ... >>> np.apply_along_axis(foo, axis=1, arr=A) array([[5., 5.5, 6. ], [6.5, 7., 7.5], [8., 8.5, 9. ]]) >>> np.apply_along_axis(foo, axis=0, arr=A) array([[5., 5.5, 6.], [6.5, 7., 7.5], [8., 8.5, 9.]]) В этом случае функция ufunct делит значение каждого элемента надвое вне зависимости от того, был ли применен перебор к ряду или колонке.
Срезы#
Списки, строки, кортежи и другие последовательности python кроме обычной индексации поддерживают индексацию срезами (slices). Рассмотрим на примере строк.
import string s = string.ascii_lowercase print(s)
abcdefghijklmnopqrstuvwxyz
Итак, у нас есть строка a , состоящая из строчных символов английского алфавита.
Если мы хотим извлечь подстроку, начиная с позиции start включая и заканчивая позицией stop не включая, то применяется синтаксис
Например, если нас часть строки с 1-го по 5-ый символ (нумерация с нуля), мы запишем
Если нас интересует подстрока с самого начала строки до какого-то символа с индексом stop (не включая), то можно опускать первый параметр среза, т.е. допускается синтаксис
Следующие два среза синонимичны и оба возвращают первые три символа.
То же самое справедливо и про второй параметр: если нас интересует подстрока до самого конца исходной строки, начиная с символа с индексом start (включая), то можно опустить второй параметр, т.е. допускается синтаксис
Следующие два среза синонимичны и оба возвращают символы с 23-го по конце.
Допускается даже опустить оба параметра. Тогда возвращается копия строки.
abcdefghijklmnopqrstuvwxyz
Если один или оба параметра выходят за пределы последовательности, то это не является формальной ошибкой. Результатом будет та часть строки, что пересекается с выбранным срезом, которая может оказаться пустой, если индексы среза не пересекаются с допустимыми индексами строки.
# символы '|' по бокам, чтобы наглядно показать края строки print(f"|s[-100:100]>|") print(f"|s[90:100]>|") print(f"|s[5:2]>|")
|abcdefghijklmnopqrstuvwxyz| || ||
Срезы с шагом#
Для разнообразия теперь будем брать срезы от списков.
Итак, у нас есть список L чисел от 0 до 9.
Срезы с шагом позволяют извлекать элементы не подряд, а, например, с прореживанием. Для этого предыдущий синтаксис расширяется третьим параметром, который как раз и отвечает за шаг.
Например, чтобы вырезать каждый второй элемент списка L , начиная с 1-го и заканчивая 8-м (не включая), необходимо записать.
Как и прежде, первые два параметра можно опускать, если start и stop совпадают с началом и концом списка соответственно.
Ниже берется каждый второй элемент всего списка.
Шаг может быть отрицательным, но тогда start должен быть больше step , чтобы вернулась не пустая подпоследовательность. При этом, как и до этого, start попадает в срез, а stop нет.
Получить последовательность в обратном порядке (обратить последовательность) можно синтаксисом
zyxwvutsrqponmlkjihgfedcba [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
Присваивание по срезам#
Если последовательность изменяемая (список, например), то допускается присваивание по срезу.
Если шаг не указан, то можно заменить элементы среза в списке элементами коллекции справа от оператора “ = ” вне зависимости от того, совпадает ли количество элементов в коллекции справа от оператора “ = ” с размером среза слева от оператора “ = ”.
Например, код в ячейке ниже заменяет первые два элемента списка L на новые два элемента (0 заменяется на 3.14, 1 заменяется на 42).
Код в ячейке ниже заменяет первые два элемента (3.14 и 42 после предыдущей замены) на сразу три новых элемента, тем самым расширяя список.
Следующим синтаксисом можно удалить первых два элемента.
Хотя для этого предпочтительнее воспользоваться синтаксисом
Если шаг указан, то количество элементов в коллекции справа от “ = : должно совпадать с количеством элементов в срезе
L = list(range(10)) # Oк print(L[::2]) L[::2] = L[1::2] # Ошибка print(L) L[::2] = []
[0, 2, 4, 6, 8] [1, 1, 3, 3, 5, 5, 7, 7, 9, 9]
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Input In [16], in () 7 # Ошибка 8 print(L) ----> 9 L[::2] = [] ValueError: attempt to assign sequence of size 0 to extended slice of size 5
Срезы массивов NumPy #
Срезы массивов NumPy введут себя очень похоже с двумя основными отличиями (документация NumPy про срезы):
- при присваивании по срезу размер массива не может измениться вне зависимости от того, указан шаг или нет;
- допускается делать многомерные срезы.
Срезы одномерных массивов#
Если массив одномерный, то роль играет только первое отличие.
import numpy as np array = np.arange(10) print(array)
array[::2] = [9, 7, 5, 3, 1] print(array)
Многомерные срезы#
Но если массив многомерный, то можно делать срезы сразу вдоль нескольких осей. Рассмотрим на примере двухмерных массивов.
matrix = np.arange(1, 26).reshape(5, 5) print(matrix)
[[ 1 2 3 4 5] [ 6 7 8 9 10] [11 12 13 14 15] [16 17 18 19 20] [21 22 23 24 25]]
Обратим внимание, что выражением matrix[i, j] мы получаем элемент массива matrix на пересечении i -й строки и j -й строки.
Такая же логика обобщается и на срезы. Например, получить j -й столбец двухмерного массива matrix можно выражением
То есть указать вдоль первой оси ( axis=0 ) указывается полный срез (все строки), а вдоль второй оси ( axis=1 ) указывается число j (только j -й столбец). Получим таким образом нулевой столбец.
Итого, процесс получения двухмерного среза можно мысленно представить в следующем виде:
- срез, указанный до запятой, вырезает строки из массива;
- срез, указанный после запятой, вырезает столбцы из массива;
- результирующий срез представляет собой все элементы, что располагаются на пересечении этих строк и столбцов.
Одну i -ю строку можно получить как выражением matrix[i, :] , так и выражением matrix[i] . Рассмотрим более содержательные примеры.
Так, например, чтобы получить элементы на пересечении первых двух строк и столбцов с первого (включая) по четвертый (не включая), необходимо применить следующий срез.
Если требуется получить каждый второй столбец, то вдоль первой оси ( axis=0 ) указывается полный срез (все строки), а вдоль второй оси ( axis=1 ) указывается полный срез с шагом 2 (каждый второй столбец).
array([[ 1, 3, 5], [ 6, 8, 10], [11, 13, 15], [16, 18, 20], [21, 23, 25]])
В качестве последнего примера рассмотрим получение срезом элементов из каждой второй строки и каждого второго столбца.
array([[ 1, 3, 5], [11, 13, 15], [21, 23, 25]])
Присваивание по срезу#
Срезы ссылаются на данные исходного массива. По ним можно производить присваивание. Например, можно целиком заменить столбец матрицы.
matrix[:, 0] = np.arange(-5, 0) print(matrix)
[[-5 2 3 4 5] [-4 7 8 9 10] [-3 12 13 14 15] [-2 17 18 19 20] [-1 22 23 24 25]]
В примере выше формы среза слева от “ = ” и массива справа от “ = ” совпадают. Это необязательное условие: работают правила броадкастинга, т.е. массив справа от оператора “ = ” может быть расширен до размера среза слева от оператора “ = ”, если их формы совместимы и срез сможет поместить в себе массив по всем измерениям. Например, прибавим к всем элемента первой строки 100, а каждый второй элемент последней строки сделаем равными 42.
matrix[0, :] += 100 matrix[-1, ::2] = 42 print(matrix)
[[ 95 102 103 104 105] [ -4 7 8 9 10] [ -3 12 13 14 15] [ -2 17 18 19 20] [ 42 22 42 24 42]]