- Как рассчитать скорость выполнения Java-программ
- 13 ответов
- Замеряй и ускоряй: как мы сократили время вызова метода в Java-коде в 16 раз
- Зачем вообще измерять производительность кода…
- Как замерить производительность: методы и сложности
- JMH: чем так хороши и почему не подошли нам
- Тестирование оптимальности кода в «боевых условиях»
- Выводы
Как рассчитать скорость выполнения Java-программ
Как вы оцениваете время выполнения Java-программы? Я не уверен, какой класс я должен использовать, чтобы сделать это. Я вроде ищу что-то вроде:
// Some timer starts here for (int i = 0; i < length; i++) < // Do something >// End timer here System.out.println("Total execution time: " + totalExecutionTime); 13 ответов
final long startTime = System.currentTimeMillis(); for (int i = 0; i < length; i++) < // Do something >final long endTime = System.currentTimeMillis(); System.out.println("Total execution time: " + (endTime - startTime)); Есть ли какая-то конкретная причина, по которой вы использовали «финал» здесь? Что было бы иначе, если бы вы опустили это ключевое слово?
Преимущество @dijxtra при использовании final заключается в том, что вы не можете случайно назначить ему (а также в других преимуществах, таких как анонимный доступ к классам и т. д.). В этом коде это не будет иметь значения. Это довольно распространенная практика, чтобы сделать все final и только не final если нужно.
Тестируемый код, наряду с измерениями времени, должен запускаться несколько раз, а первый результат должен быть отброшен. Первый, скорее всего, будет включать время загрузки класса и т. Д. При запуске умножается на несколько раз, и, конечно, вы получите среднее значение, которое будет более полезным и надежным.
Имейте в System#nanoTime() что есть некоторые проблемы, когда System#nanoTime() не может надежно использоваться на многоядерном процессоре для записи истекшего времени. каждое ядро поддерживает свой собственный TSC (счетчик меток времени): этот счетчик используется для получения нано время (на самом деле это количество тактов с момента загрузки процессора).
Следовательно, если ОС не выполняет некоторую деформацию времени TSC для синхронизации ядер, то, если поток будет запланирован на одном ядре при начальном считывании времени, а затем переключен на другое ядро, относительное время может время от времени казаться скачкообразным и вперед.
Я наблюдал это некоторое время назад на AMD/Solaris, где прошедшие времена между двумя временными точками иногда возвращались либо как отрицательные значения, либо как неожиданно большие положительные числа. Был патч ядра Solaris и настройка BIOS, необходимая для принудительного включения AMD PowerNow! выкл, который, казалось, решил это.
Кроме того, существует (AFAIK) еще не исправленная ошибка при использовании java System#nanoTime() в среде VirtualBox; вызывая у нас всевозможные странные проблемы с многопоточностью, так как большая часть пакета java.util.concurrency зависит от времени nano.
Замеряй и ускоряй: как мы сократили время вызова метода в Java-коде в 16 раз

Привет, Хабр! Замер производительности кода — не самое простое упражнение для разработчика. Приходится решать кучу сложностей: разбираться с методом, создавать правильные условия. И всё равно можно получить результат с погрешностью, потому что любой метод «не бесплатный» и требует ресурсов процессора.
Меня зовут Александр Певненко, я Java-разработчик в СберТехе. Вместе с командой мы развиваем Platform V DataSpace. Это облачный сервис, который упрощает и ускоряет разработку приложений, используя концепцию Backend-as-a-Service (BaaS) для хранения и управления данными. Я расскажу про наш способ замера производительности кода с помощью бенчмарков. Рассматривать метод будем на примере оптимизации кода в Platform V Dataspace, которая помогла сократить время вызова метода в 16 раз.
В статье я буду пользоваться языком Java, Python для построения графиков и набором библиотек JMH — они также адаптированы для Kotlin, Scala и т.д.
Зачем вообще измерять производительность кода…
…если вроде бы всё и так работает нормально? На самом деле, помимо очевидных выгод в виде скорости или стабильности есть ещё одна причина: оптимизацию можно рассматривать как важную часть культуры CI/CD. В небольших проектах эти параметры могут и не быть критичными. Зато практически все Agile-команды сегодня работают с DevOps-практиками и осознают ценность непрерывной поставки.
Пока проект «молодой», развёртывание и тестирование может быть относительно простым. Но как только модуль вырастает за рамки агента, выполняющего сборку, или на локальную сборку тестов начинает уходить по два часа, в головы разработчиков приходят светлые мысли: «А может, стоит уменьшить код? Заняться производительностью? Вдруг какие-то методы раздуты до небывалых размеров?» Именно здесь на помощь приходит оптимизация кода. Она становится частью непрерывной интеграции и следующим шагом в развитии DevOps.
В нашем случае важны все аспекты. Скорость — потому что Platform V DataSpace поставляется в составе облачной платформы Platform V, которая лежит в основе большинства продуктов Сбера. Оптимизация DevOps — из-за того, что продукт быстро растёт и важно обеспечивать непрерывную поставку функциональности в промышленную эксплуатацию.
Как замерить производительность: методы и сложности
Вёрнемся к нашему примеру. В одном из проектов Platform V DataSpace вызов метода занимал очень много времени. При этом алгоритм построен так, что избежать сложностей и вызывать метод «малой кровью» не получалось.
При пристальном рассмотрении выяснилось, что код вызывал один и тот же метод несколько раз, из-за чего растягивался timestamp. Для оптимизации нужно было оценить точную длительность работы метода.
Классический подход к замеру оптимальности кода — нотация «О» большое, О(). Но с этим методом есть одна сложность: он не позволяет замерять код «в боевых условиях». Даже если приложить максимум усилий, провести оценку с помощью нотации и обеспечить видимую оптимальность всех блоков кода по отдельности, можно получить неоптимальное решение (вспоминаем про «жадные алгоритмы», когда производительность не композируется). На результат могут повлиять разные факторы: стили программирования, типы используемых данных, особенности процессора. Тогда мы решили обратиться к альтернативному решению — бенчмаркам.
Бенчмарк — тест для оценки длительности работы метода. Он хорош тем, что позволяет замерять скорость работы алгоритма с учетом всех внешних факторов и на реальном оборудовании. В основе любого бенчмарка лежит системное время работы процессора и расчёт длительности выполнения блока кода. Чаще всего для этого используется метод System.nanoTime() , у которого, как оказалось, тоже есть свои особенности. Дело в том, что сам по себе метод системного взятия времени неизбежно даёт погрешность, даже если мы сделаем так:
Погрешность связана с тем, что сам по себе метод не «бесплатный»: его стоимость равна стоимости ресурсов машины, которые она затрачивает на расчёт. Избежать этого не получится, тут как в квантовой механике: если наблюдатель влезает в квантовый мир, он уже вносит погрешность самим фактом наблюдения.
- Получается, мы никак не избежим погрешности при вычислении «стоимости» метода work() ?
- Что считать baseline и на основе чего его строить?
- Как «сжечь» время при замере?
Но после подробного изучения метода оказалось: нет, погрешности избежать можно. Для этого есть несколько вариантов. Самый простой — использовать библиотеки JMH для Java.
JMH: чем так хороши и почему не подошли нам
JMH — это набор библиотек для тестирования производительности небольших функций. Если использовать библиотеки, то можно избежать погрешности благодаря тому, что мы:
- узнаём латентность — время на вызов System.nanoTime() ,
- измеряем гранулярность метода — разрешающую способность, минимальную ненулевую разницу между вызовами метода System.nanoTime() .
Это позволит нам получить значение, которое будет коррелировать с длительностью исполнения метода взятия времени. Вроде бы всё просто: JMH сама вычисляет латентность и гранулярность. Но расслабляться всё равно не стоит. На разных ОС измерение времени с помощью латентности и гранулярности может быть разным, поэтому, вызывая этот метод при большом количестве потоков, нужно быть осторожным.
В нашем случае использовать только бенчмарки JMH было невозможно из-за внутренних ограничений и требований к процессу. Поэтому пришлось искать третий вариант — измерять производительность кода и писать бенчмарки самостоятельно.
Тестирование оптимальности кода в «боевых условиях»
Ещё один способ избежать погрешности — измерить «стоимость» System.nanoTime() . Это позволит нам получить значение, которое будет коррелировать с длительностью исполнения метода взятия времени.
Для решения проблемы с повторным вызовом метода я подготовил самописный бенчмарк и попробовал вычесть baseline до оптимизации и после. Затем сравнил, сколько времени требовалось на исполнение кода до и после доработок. Чтобы работать было проще, собрал графический интерфейс для визуализации на Python. Вот что получилось:
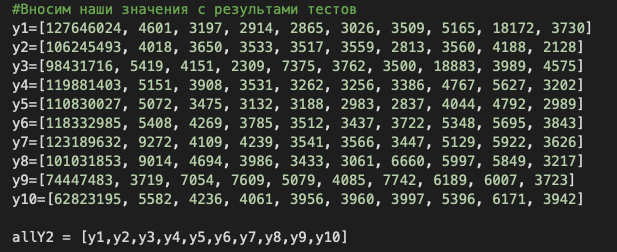

Аналогичные измерения после оптимизации давали видимый результат. На графике ниже — измерения до оптимизации (верхние линии) и после (нижние):

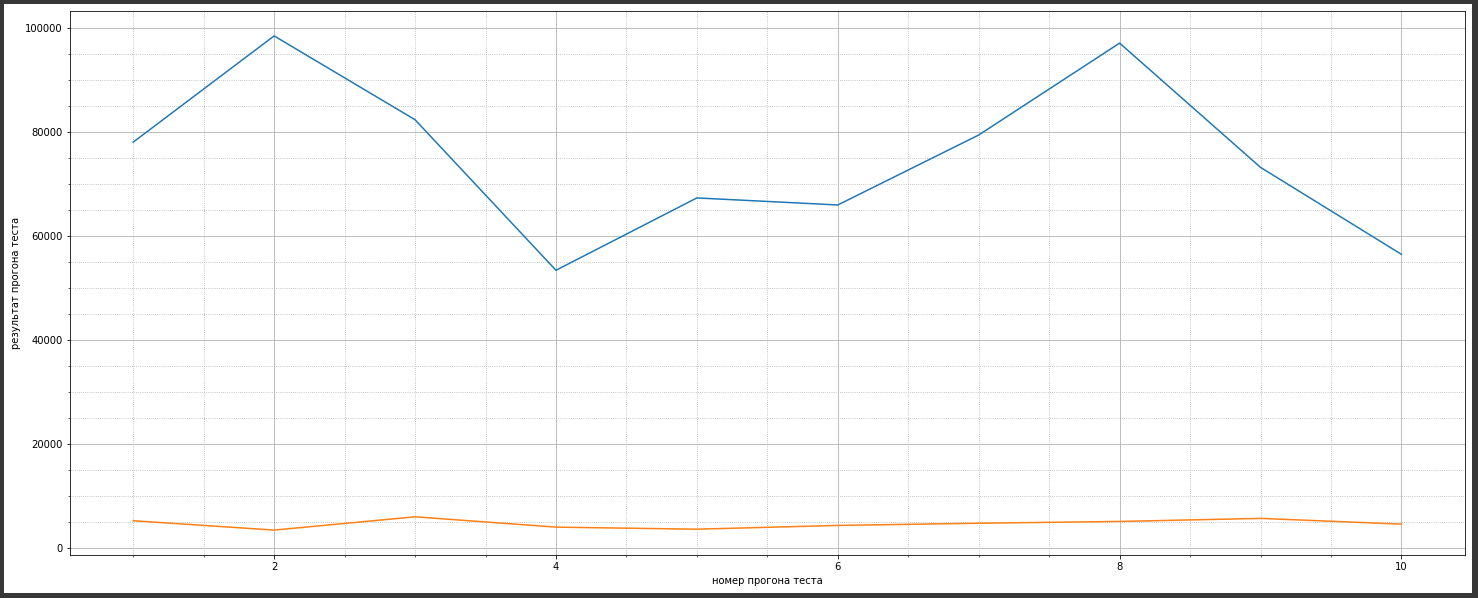
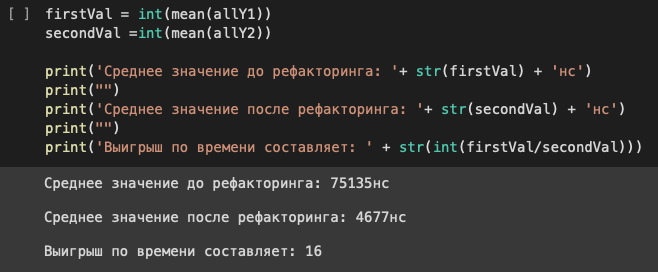
В итоге длительность вызова метода сократилась в 16 раз. На графиках это значение может отображаться с погрешностью, которая допустима при визуализации замеров, проводимых в «боевых условиях». Но само значение выигрыша действительное, так как погрешность двух замеров вычитается сама из себя, а нам необходимо относительное значение, а не абсолютное.
Выводы
Измерять производительность кода стоит хотя бы из любопытства, а лучше для того, чтобы повысить скорость продукта и упростить развёртывание. Бенчмарки — отличное решение для этого. В нашем случае самописные бенчмарки помогли серьёзно сократить длительность вызова System.nanoTime() . Сейчас работаем над тем, чтобы в большинстве проектов тестировать оптимальность всей системы ради снижения количества потенциальных проблем.
Писать собственные бенчмарки и устранять погрешности с помощью вычитания «стоимости» метода — удел не для каждого. Тем более, что в JMH все эти проблемы решаются автоматически, измерением латентности и гранулярности. Так что вполне можно пользоваться такими решениями: работы намного меньше, а польза очевидна.