Use Python to launch Excel file
when i try os.system(«open » + ‘myfile.xlsx’)
i get the output ‘0’ similarly, trying
os.system(«start excel.exe myfilepath»)
gives the result 32512 I have imported os and system, and I’m on mac. How can I change this so it does actually launch that excel file? And out of curiosity, what do the numbers it prints out mean? Thanks!
Those are exit codes. 0 means success, and any other number means failure. Often the man page for a program will tell you a list of the failure codes and what they mean.
7 Answers 7
import os os.system("start EXCEL.EXE file.xlsx") Provided that file.xlsx is in the current directory.
A tweak: for filenames with embedded blanks enclose the entire parameter with SINGLE quotes and put DOUBLE quotes around the file name (e.g. ‘ start EXCEL.EXE » C:/temp/new file.csv » ‘. The extra spaces don’t hurt and can prevent parameters from being «merged» when the command is run. BTW on Python 3.x (and possibly 2.x) you should use ‘/’ as the file separator, never «\» — even on Windows. Python will do the conversion so you don’t need to use double backslashes in paths (necessary to prevent the first character from being interpreted as a control character, e.g «\n» = line feed).
Worth noting os.system(‘start excel.exe file.xlsx’) will open file with same name from your documents folder and os.system(‘start «excel.exe» «file.xlsx»‘) (note the extra quotes) will open file from same folder as code is in. Testing this on my end I am not sure y this happens but probably an important distinction.
Как запустить файл excel из python?
Не открыть для чтения или записи, а просто открыть файл xlsx в экселе.
Или например любой другой файл: docx, jpg, mp3 в программе по умолчанию для этого типа расширения.
В итоге нашел четыре способа для запуска любых файлов (правда у всех общая проблема — не запускаются файлы, если есть пробелы в имени или пути):
1. Самый простой и правильный, через subprocess:
import subprocess subprocess.call("d:\\2014.xlsx", shell=True)import subprocess subprocess.Popen("d:\\2014.xlsx", shell=True)Для запуска команд системы используется две функции subprocess.call() и subprocess.Popen(). Основное отличие этих функций между собой: функция subprocess.call() блокирует выполнение сценария до получения ответа, в то время как функция subprocess.Popen() — нет.
subprocess.call() — используется, если нужно просто запустить команду, а вывод от нее сохранять не требуется.
subprocess.Popen() — используется, если требуется захватить вывод команды
Все ОК, просто и четко.
2. Другой отличный вариант:
os.startfile(‘recomendations.log’)
Эта функция открывает файл с помощью программы, указанной в реестре Windows для файлов этого типа.
3. Через win32com.client и WScript.Shell:
import win32com.client shell = win32com.client.Dispatch("WScript.Shell") shell.Run('d:\meridian.jpg')import os os.system(r'd:\2014.xlsx')Чтение и запись файлов Excel (XLSX) в Python
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip .
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame . А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas . Потом используем словарь для заполнения DataFrame :
import pandas as pd
df = pd.DataFrame( 'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]>)Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
А вот и созданный файл Excel:
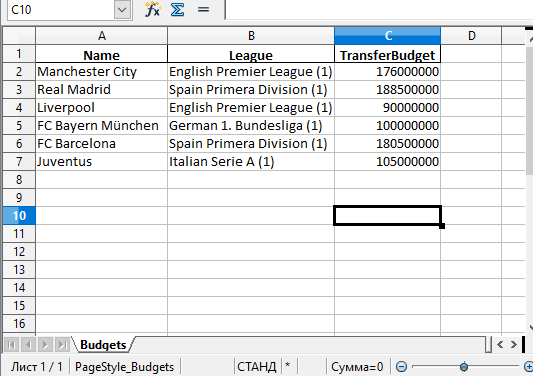
Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel() :
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)Также можно добавили параметр index со значением False , чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame( 'Salary': [560000, 220000, 125000]>)
salaries2 = pd.DataFrame( 'Salary': [370000, 270000, 240000]>)
salaries3 = pd.DataFrame( 'Salary': [160000, 260000, 250000]>)
salary_sheets =
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets , где каждый ключ будет названием листа, а значение — объектом DataFrame .
Дальше используем движок xlsxwriter для создания объекта writer . Он и передается функции to_excel() .
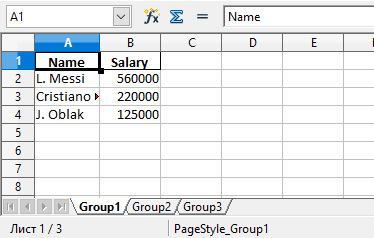
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter , который нужен для работы с классом ExcelWriter . Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save() , которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame . Для этого достаточно воспользоваться функцией read_excel() :