- Python: TypeError: Unicode-objects must be encoded before hashing
- 2 Answers 2
- Python TypeError: Unicode-objects must be encoded before hashing
- How to reproduce the error
- How to fix the error
- Calling the update() method
- Take your skills to the next level ⚡️
- About
- Search
- Tags
- Python strings must be encoded before hashing
- # TypeError: Strings must be encoded before hashing (Python)
- # Pass a bytes object to the hashing algorithm
- # Prefix the string with b» to encode it to a bytes object
- # Using the digest() and hexdigest() methods
- # Checking what type of object a variable stores
Python: TypeError: Unicode-objects must be encoded before hashing
I am trying to read in a file of passwords. Then I am trying to compute the hash for each password and compare it to a hash I already have to determine if I have discovered the password. However the error message I keep getting is «TypeError: Unicode-objects must be encoded before hashing». Here is my code:
from hashlib import sha256 with open('words','r') as f: for line in f: hashedWord = sha256(line.rstrip()).hexdigest() if hashedWord == 'ca52258a43795ab5c89513f9984b8f3d3d0aa61fb7792ecefe8d90010ee39f2': print(line + "is one of the words!") You should probably fix your indents, as people are more willing to help people with code they can cut and paste into their interpreter.
2 Answers 2
The error message means exactly what it says: You have a Unicode string. You can’t SHA-256-hash a Unicode string, you can only hash bytes.
But why do you have a Unicode string? Because you’re opening a file in text mode, which means you’re implicitly asking Python to decode the bytes in that file (using your default encoding) to Unicode. If you want to get the raw bytes, you have to use binary mode.
In other words, just change this line:
You may notice that, once you fix this, the print line raises an exception. Why? because you’re trying to add a bytes to a str . You’re also missing a space, and you’re printing the un-stripped line. You could fix all of those by using two arguments to print (as in print(line.rstrip(), «is one of the words») ).
But then you’ll get output like b’\xc3\x85rhus’ is one of the words when you wanted it to print out Århus is one of the words . That’s because you now have bytes, not strings. Since Python is no longer decoding for you, you’ll need to do that manually. To use the same default encoding that sometimes works when you don’t specify an encoding to open , just call decode without an argument. So:
print(line.rstrip().decode(), "is one of the words") Python TypeError: Unicode-objects must be encoded before hashing
One error that you might encounter when running Python code is:
Or if you’re using the latest Python version:
These two errors usually occur when you use the hashlib module to hash strings.
The following examples show how you can fix this error in your code.
How to reproduce the error
Suppose you want to create an md5 hash from a string in Python.
You may pass a string variable to the hashlib.md5() method as follows:
But because hashlib hashing methods require an encoded string, it responds with an error:
If you’re using Python version 3.9 or above, the error message has been changed slightly to:
But because strings in Python 3 use Unicode encoding by default, the meaning of both errors is the same.
How to fix the error
To fix this error, you need to encode the string passed to the hashing method.
This is easy to do with the string.encode() method:
Unless you have specific requirements, using UTF-8 should be okay because it’s the most common character encoding method. By default, the encode() method will use UTF-8 encoding when you don’t pass any argument. I’m just showing you how to pass one if you need it.
If you’re passing a literal string to the hashing method, you can use the byte string format.
As you can see from the hexdigest() output, the hashing results are identical.
You need to encode the string no matter if you use sha256 , sha512 , or md5 hash algorithm.
Calling the update() method
Note that you also need to encode the string passed to the hashlib.update() method like this:
If you don’t encode() the string, then Python will raise the same error.
Now you’ve learned how to fix Python ‘Unicode-objects or Strings must be encoded before hashing’ error.
I hope this article was helpful. See you in other articles! 🍻
Take your skills to the next level ⚡️
I’m sending out an occasional email with the latest tutorials on programming, web development, and statistics. Drop your email in the box below and I’ll send new stuff straight into your inbox!
About
Hello! This website is dedicated to help you learn tech and data science skills with its step-by-step, beginner-friendly tutorials.
Learn statistics, JavaScript and other programming languages using clear examples written for people.
Search
Type the keyword below and hit enter
Tags
Click to see all tutorials tagged with:
Python strings must be encoded before hashing
Last updated: Feb 16, 2023
Reading time · 3 min
# TypeError: Strings must be encoded before hashing (Python)
The Python «TypeError: Strings must be encoded before hashing» occurs when we pass a string to a hashing algorithm.
To solve the error, use the encode() method to encode the string to a bytes object, e.g. my_str.encode(‘utf-8’) .

Here is an example of how the error occurs.
Copied!import hashlib my_str = 'bobbyhadz.com' # ⛔️ TypeError: Strings must be encoded before hashing my_hash = hashlib.sha256(my_str).hexdigest()
Your error message might also be the following (depending on your version of Python).
Copied!TypeError: Unicode-objects must be encoded before hashing
We used sha256() to create a SHA-256 hash object and passed a string to it, which caused the error.
# Pass a bytes object to the hashing algorithm
To solve the error, pass a bytes object to the method instead, e.g. my_str.encode(‘utf-8’) .
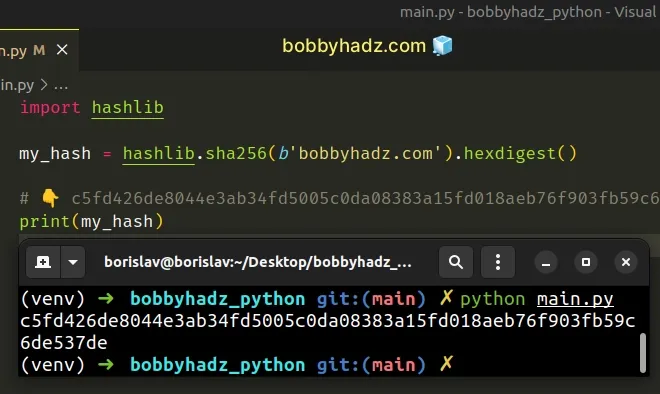
Copied!import hashlib my_str = 'bobbyhadz.com' # ✅ encode str to bytes my_hash = hashlib.sha256(my_str.encode('utf-8')).hexdigest() # 👇️ c5fd426de8044e3ab34fd5005c0da08383a15fd018aeb76f903fb59c6de537de print(my_hash)

The str.encode method returns an encoded version of the string as a bytes object. The default encoding is utf-8 .
# Prefix the string with b» to encode it to a bytes object
If you have a string literal, and not a string stored in a variable, you can prefix the string with b to encode it to a bytes object.
Copied!import hashlib my_hash = hashlib.sha256(b'bobbyhadz.com').hexdigest() # 👇️ c5fd426de8044e3ab34fd5005c0da08383a15fd018aeb76f903fb59c6de537de print(my_hash)
Prefixing the string with b achieves the same result as calling the encode() method on it, but can only be used if you have a string literal, and not a string stored in a variable.
Notice that we don’t have to use the str.encode() method when we have a bytes object.
Copied!import hashlib # ✅ with a String my_str = 'bobbyhadz.com' my_hash = hashlib.sha256(my_str.encode('utf-8')).hexdigest() # 👇️ c5fd426de8044e3ab34fd5005c0da08383a15fd018aeb76f903fb59c6de537de print(my_hash) # ---------------------------------------------- # ✅ with a Bytes object my_bytes = b'bobbyhadz.com' my_hash = hashlib.sha256(my_bytes).hexdigest() # 👇️ c5fd426de8044e3ab34fd5005c0da08383a15fd018aeb76f903fb59c6de537de print(my_hash)
The first example uses a string, so we had to call the str.encode() method to convert the string to bytes in the call to the sha256() method.
The second example uses a bytes object (the b» prefix), so it can directly get passed to the sha256() method.
# Using the digest() and hexdigest() methods
You can get the digest of the concatenation of the data fed to the hash object by using the digest() or hexdigest() methods.
Here is an example that uses the digest() method instead.
Copied!import hashlib str_1 = 'first' str_2 = 'second' m = hashlib.sha256() m.update(str_1.encode('utf-8')) m.update(str_2.encode('utf-8')) # 👇️ b'\xda\x83\xf6>\x1aG0\x03q,\x18\xf5\xaf\xc5\xa7\x90D"\x19C\xd1\x08 <|Zz\xc7#m\x85\xe8\xd2'print(m.digest()) # 👇️ da83f63e1a473003712c18f5afc5a79044221943d1083c7c5a7ac7236d85e8d2 print(m.hexdigest())
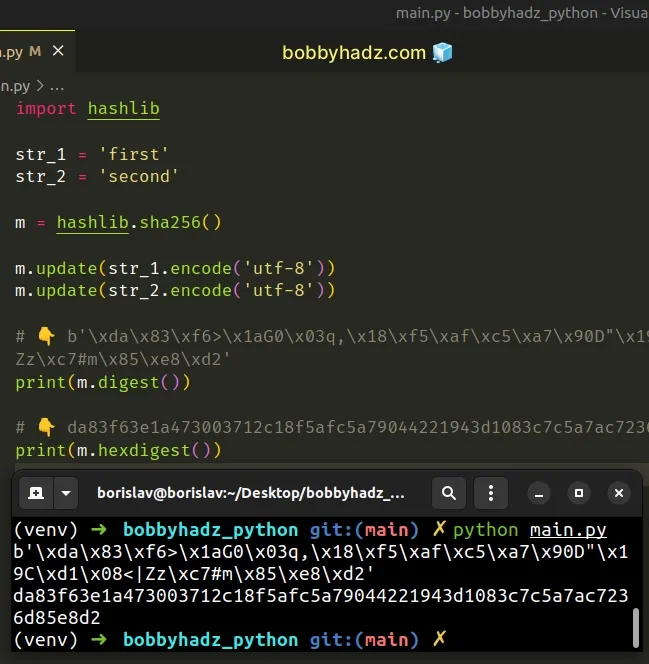
We used the str.encode() method to convert the strings to bytes objects before passing them to the hash.update method.
The hash.update() method updates the hash object with the supplied bytes-like object.
We could have also prefixed the string literals with b to convert them to bytes.
Copied!import hashlib # ✅ declare bytes objects bytes_1 = b'first' bytes_2 = b'second' m = hashlib.sha256() m.update(bytes_1) m.update(bytes_2) # 👇️ b'\xda\x83\xf6>\x1aG0\x03q,\x18\xf5\xaf\xc5\xa7\x90D"\x19C\xd1\x08 <|Zz\xc7#m\x85\xe8\xd2'print(m.digest()) # 👇️ da83f63e1a473003712c18f5afc5a79044221943d1083c7c5a7ac7236d85e8d2 print(m.hexdigest())
The code sample declares bytes objects directly, so we can pass them to the hash.update() method without using encode.
The hash.hexdigest method is an alternative to using hash.digest.
Here is a more condensed version of the previous code sample.
Copied!import hashlib my_bytes = b'first second' my_str = hashlib.sha256(my_bytes).hexdigest() # 👇️ 92088ec140fc553e4b1ede202edccb65a807bbf8a38d765a3ad38013c0f13688 print(my_str)
The hash.digest method returns the digest of the data passed to the update() method. The method returns a bytes object which may contain bytes in the whole range from 0 to 255 .
The hash.hexdigest method is like digest but the digest is returned as a string object of double length and contains only hexadecimal digits.
The method is often used when you need to safely send the value over the network, e.g. via email.
# Checking what type of object a variable stores
If you aren’t sure what type of object a variable stores, use the built-in type() class.
Copied!my_bytes = 'hello'.encode('utf-8') print(type(my_bytes)) # 👉️ print(isinstance(my_bytes, bytes)) # 👉️ True my_str = 'hello' print(type(my_str)) # 👉️ print(isinstance(my_str, str)) # 👉️ True
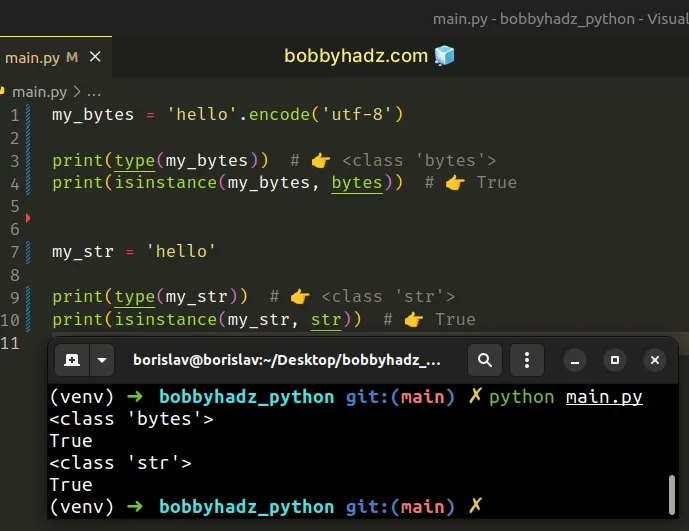
The type class returns the type of an object.
The isinstance function returns True if the passed-in object is an instance or a subclass of the passed-in class.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.