- Selenium для Python. Глава 4. Поиск элементов
- 4. Поиск элементов
- 4.1. Поиск по Id
- 4.2. Поиск по Name
- 4.3. Поиск по XPath
- 4.4. Поиск гиперссылок по тексту гиперссылки
- 4.5. Поиск элементов по тэгу
- Welcome
- 4.6. Поиск элементов по классу
- 4.7. Поиск элементов по CSS-селектору
- Поиск HTML элементов
- Запуск браузера
- Поиск элемента по ID
- Поиск элемента по имени
- Поиск элемента по тексту ссылки
- Поиск элемента по частичному тексту ссылки
- Поиск элемента по XPath
- Избегайте XPath из Developer Tool
Selenium для Python. Глава 4. Поиск элементов
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
4. Поиск элементов
Существует ряд способов поиска элементов на странице. Вы вправе использовать наиболее уместные для конкретных задач. Selenium предоставляет следующие методы поиска элементов на странице:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Помимо общедоступных (public) методов, перечисленных выше, существует два приватных (private) метода, которые при знании указателей объектов страницы могут быть очень полезны: find_element and find_elements.
from selenium.webdriver.common.by import By driver.find_element(By.XPATH, '//button[text()="Some text"]') driver.find_elements(By.XPATH, '//button') Для класса By доступны следующие атрибуты:
ID = "id" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" NAME = "name" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector" 4.1. Поиск по Id
Используйте этот способ, когда известен id элемента. Если ни один элемент не удовлетворяет заданному значению id, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент form может быть определен следующим образом:
login_form = driver.find_element_by_id('loginForm') 4.2. Поиск по Name
Используйте этот способ, когда известен атрибут name элемента. Результатом будет первый элемент с искомым значением атрибута name. Если ни один элемент не удовлетворяет заданному значению name, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элементы с именами username и password могут быть определены следующим образом:
username = driver.find_element_by_name('username') password = driver.find_element_by_name('password') Следующий код получит кнопку “Login”, находящуюся перед кнопкой “Clear”:
continue = driver.find_element_by_name('continue') 4.3. Поиск по XPath
XPath – это язык, использующийся для поиска узлов дерева XML-документа. Поскольку в основе HTML может лежать структура XML (XHTML), пользователям Selenium предоставляется возможность посредоством этого мощного языка отыскивать элементы в их веб-приложениях. XPath выходит за рамки простых методов поиска по атрибутам id или name (и в то же время поддерживает их), и открывает спектр новых возможностей, таких как поиск третьего чекбокса (checkbox) на странице, к примеру.
Одно из веских оснований использовать XPath заключено в наличии ситуаций, когда вы не можете похвастать пригодными в качестве указателей атрибутами, такими как id или name, для элемента, который вы хотите получить. Вы можете использовать XPath для поиска элемента как по абсолютному пути (не рекомендуется), так и по относительному (для элементов с заданными id или name). XPath указатели в том числе могут быть использованы для определения элементов с помощью атрибутов отличных от id и name.
Абсолютный путь XPath содержит в себе все узлы дерева от корня (html) до необходимого элемента, и, как следствие, подвержен ошибкам в результате малейших корректировок исходного кода страницы. Если найти ближайщий элемент с атрибутами id или name (в идеале один из элементов-родителей), можно определить искомый элемент, используя связь «родитель-подчиненный». Эти связи будут куда стабильнее и сделают ваши тесты устойчивыми к изменениям в исходном коде страницы.
Для примера, рассмотрим следующий исходный код страницы:
Элемент form может быть определен следующими способами:
login_form = driver.find_element_by_xpath("/html/body/form[1]") login_form = driver.find_element_by_xpath("//form[1]") login_form = driver.find_element_by_xpath("//form[@id='loginForm']") - Абсолютный путь (поломается при малейшем изменении структуры HTML страницы)
- Первый элемент form в странице HTML
- Элемент form, для которого определен атрибут с именем id и значением loginForm
username = driver.find_element_by_xpath("//form[input/@name='username']") username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]") username = driver.find_element_by_xpath("//input[@name='username']") - Первый элемент form с дочерним элементом input, для которого определен атрибут с именем name и значением username
- Первый дочерний элемент input элемента form, для которого определен атрибут с именем id и значением loginForm
- Первый элемент input, для которого определен атрибут с именем name и значением username
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']") clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]") - Элемент input, для которого заданы атрибут с именем name и значением continue и атрибут с именем type и значением button
- Четвертый дочерний элемент input элемента form, для которого задан атрибут с именем id и значением loginForm
- XPath Checker — получает пути XPath и может использоваться для проверки результатов пути XPath
- Firebug — получение пути XPath — лишь одно из многих мощных средств, поддерживаемых этим очень полезным плагином
- XPath Helper — для Google Chrome
4.4. Поиск гиперссылок по тексту гиперссылки
Используйте этот способ, когда известен текст внутри анкер-тэга [anchor tag, анкер-тэг, тег «якорь» — тэг — Прим. пер.]. С помощью такого способа вы получите первый элемент с искомым значением текста тэга. Если никакой элемент не удовлетворяет искомому значению, будет вызвано исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Are you sure you want to do this?
Continue Cancel
Элемент-гиперссылка с адресом «continue.html» может быть получен следующим образом:
continue_link = driver.find_element_by_link_text('Continue') continue_link = driver.find_element_by_partial_link_text('Conti') 4.5. Поиск элементов по тэгу
Используйте этот способ, когда вы хотите найти элемент по его тэгу. Таким способом вы получите первый элемент с указанным именем тега. Если поиск не даст результатов, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Welcome
Site content goes here.
Элемент заголовка h1 может быть найден следующим образом:
heading1 = driver.find_element_by_tag_name('h1') 4.6. Поиск элементов по классу
Используйте этот способ в случаях, когда хотите найти элемент по значению атрибута class. Таким способом вы получите первый элемент с искомым именем класса. Если поиск не даст результата, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент “p” может быть найден следующим образом:
content = driver.find_element_by_class_name('content') 4.7. Поиск элементов по CSS-селектору
Используйте этот способ, когда хотите получить элемент с использованием синтаксиса CSS-селекторов [CSS-селектор — это формальное описание относительного пути до элемента/элементов HTML. Классически, селекторы используются для задания правил стиля. В случае с WebDriver, существование самих правил не обязательно, веб-драйвер использует синтаксис CSS только для поиска — Прим. пер.]. Этим способом вы получите первый элемент удовлетворяющий CSS-селектору. Если ни один элемент не удовлетворяют селектору CSS, будет возбуждено исключение NoSuchElementException.
Для примера, рассмотрим следующий исходный код страницы:
Элемент “p” может быть определен следующим образом:
content = driver.find_element_by_css_selector('p.content') - 31 CSS селектор — это будет полезно знать! — краткая выжимка по CSS-селекторам
- CSS селекторы, свойства, значения — отличный учебник параллельного изучения HTML и CSS
Поиск HTML элементов

Как вы, возможно, уже поняли, чтобы управлять элементами страницы, нам нужно сначала найти их. Selenium использует так называемые локаторы, чтобы находить элементы на веб-странице.
В Selenium есть 8 методов которые помогут в поиске HTML элементов:
Вы можете использовать любой из них, чтобы сузить поиск элемента, который вам нужен.
Запуск браузера
Тестирование веб-сайтов начинается с браузера. В приведенном ниже тестовом скрипте запускается окно браузера Firefox, и осуществляется переход на сайт.
Используйте webdriver.Chrome и webdriver.Ie() для тестирования в Chrome и IE соответственно. Новичкам рекомендуется закрыть окно браузера в конце тестового примера.
Поиск элемента по ID
Использование идентификаторов — самый простой и безопасный способ поиска элемента в HTML. Если страница соответствует W3C HTML, идентификаторы должны быть уникальными и идентифицироваться в веб-элементах управления. По сравнению с текстами тестовые сценарии, использующие идентификаторы, менее склонны к изменениям приложений (например, разработчики могут принять решение об изменении метки, но с меньшей вероятностью изменить идентификатор).
Поиск элемента по имени
Атрибут имени используются в элементах управления формой, такой как текстовые поля и переключатели (radio кнопки). Значения имени передаются на сервер при отправке формы. С точки зрения вероятности будущих изменений, атрибут name, второй по отношению к ID.
Поиск элемента по тексту ссылки
Только для гиперссылок. Использование текста ссылки — это, пожалуй, самый прямой способ щелкнуть ссылку, так как это то, что мы видим на странице.
HTML для которого будет работать
Поиск элемента по частичному тексту ссылки
Selenium позволяет идентифицировать элемент управления гиперссылкой с частичным текстом. Это может быть полезно, если текст генерируется динамически. Другими словами, текст на одной веб-странице может отличаться при следующем посещении. Мы могли бы использовать общий текст, общий для этих динамически создаваемых текстов ссылок, для их идентификации.
HTML для которого будет работать
Поиск элемента по XPath
XPath, XML Path Language, является языком запросов для выбора узлов из XML документа. Когда браузер отображает веб-страницу, он анализирует его в дереве DOM. XPath может использоваться для ссылки на определенный узел в дереве DOM. Если это звучит слишком сложно для вас, не волнуйтесь, просто помните, что XPath — это самый мощный способ найти определенный веб-элемент.
HTML для которого будет работать
Некоторые тестеры чувствуют себя «запуганными» сложностью XPath. Тем не менее, на практике существует только ограниченная область для использования XPath.
Избегайте XPath из Developer Tool
Избегайте использования скопированного XPath из инструмента Developer Tool.
Инструмент разработчика браузера (щелкните правой кнопкой мыши, чтобы выбрать «Проверить элемент», чтобы увидеть) очень полезен для определения веб-элемента на веб-странице. Вы можете получить XPath веб-элемента там, как показано ниже (в Chrome):
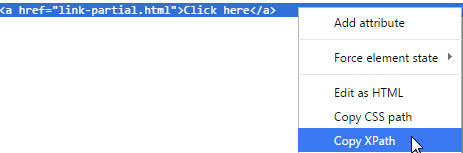
Скопированный XPath для второй ссылки «Нажмите здесь» в примере: