- Сводные таблицы в Pandas — швейцарский нож для аналитиков
- Агрегирование
- Groupby
- Pivot table
- Pivot
- Вывод
- pandas.pivot_table#
- How to sum in a Pandas pivot table?
- Pandas Pivot table sum example
- Creating the example DataFrame
- Pandas pivot table with sum aggfunc
- Add a Summary / Total row & column to Pandas pivot table
- Pivot table count and sum
- Sum multiple columns
- Pivot table without aggregation
- Pivot columns to rows in Pandas
- Export pivot table to csv
- Additional Learning
- Recent Posts
Сводные таблицы в Pandas — швейцарский нож для аналитиков
Привет, Хабр! Меня зовут Панчин Денис, это мой первый пост и я хочу Вам рассказать о работе с сводными таблицами в Pandas. Сводные таблицы хорошо известны всем аналитикам по Excel. Это прекрасный инструмент, который помогает быстро получить различную информацию по массиву данных. Рассмотрим реализацию и тонкости сводных таблиц в Pandas.
Использовать будем только столбцы ‘region’ (субъект РФ), ‘municipality’ (муниципальное образование), ‘year’ (год), ‘birth’ (число родившихся на 1000 человек населения), ‘wage’ (cреднемесячная номинальная начисленная заработная плата, руб.). Сразу оговорюсь, что Москва и Санкт-Петербург являются отдельными субъектами Российской Федерации и в этом датафрейме отсутствуют.
import pandas as pd import numpy as np df = pd.read_csv('Krupnie_goroda-RF_1985-2019_187_09.12.21/data.csv', sep=';') df = df[['region', 'municipality', 'year', 'birth', 'wage']] df.sample(7)Минимальную статистику можно получить использовав метод describe(include = ‘all’). Мы видим что у нас 4109 строки, по 81 региону и 202 городам. Средняя рождаемость на 1000 человек 11,39, минимальная — 3,4, максимальная — 36,1.
Агрегирование
Если объяснять простыми словами, то агрегирование — это процесс приведения некого большого массива значений к некому сжатому по определенному параметру массиву значений. Например, среднее, медиана, количество, сумма.
df[['birth', 'wage']].agg(['mean', 'median', 'min', 'max'])Groupby
Но средняя температура по больнице нам не интересна, мы хотим знать победителей в лицо. Допустим нам нужно посмотреть средние значения с группировкой по городам и субъектам РФ. Для этого закономерно используем метод groupby([‘region’, ‘municipality’]).agg(‘mean’).
df_groupby = df.groupby(['region', 'municipality']).agg('mean') df_groupby.head(7)Обратите внимание, что колонки region и municipality стали индексами.
На этом мы не успокаиваемся и пытаемся выжать больше стат.данных: среднее, медиану, минимум, максимум.
agg_func_math = < 'birth': ['mean', 'median', 'min', 'max'], 'wage': ['mean', 'median', 'min', 'max'] >df.groupby(['region', 'municipality']).agg(agg_func_math).head(7)Посмотрим топ городов по зарплатам.
df.groupby(['region', 'municipality']).agg('mean').sort_values(by='wage', ascending=False).head(7)А что если посмотреть данные в разрезе по годам.
Pivot table
Ответим на этот вопрос чуть позже, а пока создадим сводную таблицу аналогичную той, что мы уже делали ранее.
df_pivot_table = df.pivot_table(index=['region', 'municipality']) df_pivot_table.head(7)Уже на этом этапе видно, что сводная таблица достаточно умная и сама агрегировала данные и посчитала средние значения.
Но если мы захотим расширить таблицу новыми значениями — медианой, то увидим, что конечный результат по структуре будет отличаться от того, что мы делали при использовании метода groupby.
df_pivot_table = df.pivot_table(index=['region', 'municipality'], values=['birth', 'wage'], aggfunc=[np.mean, np.median]) df_pivot_table.head(7)Так мы плавно подошли к тем преимуществам, которые делает сводные таблицы швейцарским ножом для аналитиков. Если используя groupby мы «укрупняли» строки по городам, то сейчас мы можем «развернуть» столбец, например, ‘year’ (год) и посмотреть данные в разрезе по годам.
df_pivot_table = df.pivot_table(index=['region', 'municipality'], values='birth', columns='year') df_pivot_table.head(7)И, конечно, данные в сводной таблице можно фильтровать. Создадим сводную таблицу и оставим в ней данные по городам, в которых рождаемость на 1000 человек превышает 12, зарплата выше 40.000 и отсортируем всё по убыванию рождаемости.
df2 = df.pivot_table(index=['region', 'municipality']) df2.query("`birth`>12 and `wage`>40000").sort_values(by='birth', ascending=False)Pivot
Всё было замечательно, но в Pandas кроме pivot_table есть ещё просто pivot. Посмотрим что это за зверь и чем они отличаются.
Создадим pivot: рождаемость в разрезе по регионам и годам.
df_pivot = df.pivot(index='region', values='birth', columns='year') df_pivot.head(7)Мы получили ошибку «Index contains duplicate entries, cannot reshape«. Что-то не так с индексами, попробуем создать pivot с индексами по городам, а не регионам.
df_pivot = df.pivot(index='municipality', values='birth', columns='year') df_pivot.head(7)Всё получилось. Как мы уже заметили всё дело в индексах. На самом деле всё в повторяющихся индексах. Как мы видели ранее в датафрейме есть позиции с несколькими городами в рамках одного субъекта, так получаются дублированные данные индексов с которыми не умеет работать pivot.
Вывод
Groupby, pivot и pivot_table удобные и привычные инструменты для работы с данными. Groupby позволяет кодом в одну строку получить агрегированные и сортированные данные, а pivot и pivot_table работать в более глубоком разрезе. Pivot_table предпочтителен, т.к. не ограничивает вас в уникальности значений в столбце индекса. И, конечно, все эти данные можно фильтровать под ваши запросы.
pandas.pivot_table#
pandas. pivot_table ( data , values = None , index = None , columns = None , aggfunc = ‘mean’ , fill_value = None , margins = False , dropna = True , margins_name = ‘All’ , observed = False , sort = True ) [source] #
Create a spreadsheet-style pivot table as a DataFrame.
The levels in the pivot table will be stored in MultiIndex objects (hierarchical indexes) on the index and columns of the result DataFrame.
Parameters data DataFrame values list-like or scalar, optional
Column or columns to aggregate.
index column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list can contain any of the other types (except list). Keys to group by on the pivot table index. If an array is passed, it is being used as the same manner as column values.
columns column, Grouper, array, or list of the previous
If an array is passed, it must be the same length as the data. The list can contain any of the other types (except list). Keys to group by on the pivot table column. If an array is passed, it is being used as the same manner as column values.
aggfunc function, list of functions, dict, default numpy.mean
If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names (inferred from the function objects themselves) If dict is passed, the key is column to aggregate and value is function or list of functions. If margin=True , aggfunc will be used to calculate the partial aggregates.
fill_value scalar, default None
Value to replace missing values with (in the resulting pivot table, after aggregation).
margins bool, default False
If margins=True , special All columns and rows will be added with partial group aggregates across the categories on the rows and columns.
dropna bool, default True
Do not include columns whose entries are all NaN. If True, rows with a NaN value in any column will be omitted before computing margins.
margins_name str, default ‘All’
Name of the row / column that will contain the totals when margins is True.
observed bool, default False
This only applies if any of the groupers are Categoricals. If True: only show observed values for categorical groupers. If False: show all values for categorical groupers.
sort bool, default True
Specifies if the result should be sorted.
An Excel style pivot table.
Pivot without aggregation that can handle non-numeric data.
Unpivot a DataFrame from wide to long format, optionally leaving identifiers set.
Wide panel to long format. Less flexible but more user-friendly than melt.
Reference the user guide for more examples.
>>> df = pd.DataFrame("A": ["foo", "foo", "foo", "foo", "foo", . "bar", "bar", "bar", "bar"], . "B": ["one", "one", "one", "two", "two", . "one", "one", "two", "two"], . "C": ["small", "large", "large", "small", . "small", "large", "small", "small", . "large"], . "D": [1, 2, 2, 3, 3, 4, 5, 6, 7], . "E": [2, 4, 5, 5, 6, 6, 8, 9, 9]>) >>> df A B C D E 0 foo one small 1 2 1 foo one large 2 4 2 foo one large 2 5 3 foo two small 3 5 4 foo two small 3 6 5 bar one large 4 6 6 bar one small 5 8 7 bar two small 6 9 8 bar two large 7 9
This first example aggregates values by taking the sum.
>>> table = pd.pivot_table(df, values='D', index=['A', 'B'], . columns=['C'], aggfunc=np.sum) >>> table C large small A B bar one 4.0 5.0 two 7.0 6.0 foo one 4.0 1.0 two NaN 6.0
We can also fill missing values using the fill_value parameter.
>>> table = pd.pivot_table(df, values='D', index=['A', 'B'], . columns=['C'], aggfunc=np.sum, fill_value=0) >>> table C large small A B bar one 4 5 two 7 6 foo one 4 1 two 0 6
The next example aggregates by taking the mean across multiple columns.
>>> table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'], . aggfunc='D': np.mean, 'E': np.mean>) >>> table D E A C bar large 5.500000 7.500000 small 5.500000 8.500000 foo large 2.000000 4.500000 small 2.333333 4.333333
We can also calculate multiple types of aggregations for any given value column.
>>> table = pd.pivot_table(df, values=['D', 'E'], index=['A', 'C'], . aggfunc='D': np.mean, . 'E': [min, max, np.mean]>) >>> table D E mean max mean min A C bar large 5.500000 9 7.500000 6 small 5.500000 9 8.500000 8 foo large 2.000000 5 4.500000 4 small 2.333333 6 4.333333 2
How to sum in a Pandas pivot table?

When working with pivot tables, you are able to aggregate the data as needed for your analysis. In today’s tutorial we’ll learn how to use Pandas to sum up aggregated pivot table values. Below you’ll find a step-by-step example that you are welcome to follow along.
Pandas Pivot table sum example
Creating the example DataFrame
We’ll first go ahead and create a DataFrame that we’ll use throughout our example.
import pandas as pd month = ['May', 'February', 'May', 'April', 'April', 'January', 'April', 'March'] language = ['Java', 'Java', 'Java', 'C#', 'Java', 'Java', 'C#', 'C#'] office = ['Atlanta', 'New York', 'New York', 'New York', 'Atlanta', 'New York', 'Atlanta', 'Atlanta'] salary = [124.0, 119.0, 117.0, 119.0, 124.0, 124.0, 129.0, 117.0] salaries = dict(month=month, language=language, office=office,salary = salary) salarydf = pd.DataFrame(data=salaries) salarydf.head() 
Pandas pivot table with sum aggfunc
Pandas delivers a pivot_table method for DataFrames. For every pivot table you can specify the table index (rows), columns and values. The aggfunc parameter allows you to summarize your pivot table values according to specific logic. Below is a short snippet that creates the pivot and summarizes using sum:
salarydf.pivot_table(values='salary', index = 'month', \ columns= 'language', aggfunc= 'sum')Here’s the initial pivot table that we have created:
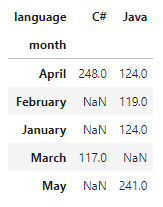
Add a Summary / Total row & column to Pandas pivot table
We can easily insert a total / sum row to our Python pivot table by using the margins and margin_names parameters. The margins parameters insets the summary row and columns. THe margin_names parameters, allows us to rename the pivot table summary columns.
salarydf.pivot_table(values='salary', index = 'month', \ columns= 'language', aggfunc= 'sum', \ margins = True, margins_name='Total')Pivot table count and sum
Next example will be to use multiple aggregation functions for our Pivot table calculated field values. In this example, we’ll use both count and sum. To do that, we’ll pass a list to the aggfunc parameter.
salarydf.pivot_table(values='salary', index = 'month', \ columns= 'language', \ aggfunc= ['count','sum'], \ margins = True, margins_name='Total')
Sum multiple columns
In this next section, we will aggregate and summarize our pivot data by multiple columns. In this example we’ll first group the data by the office and then by the language column. For that, we’ll pass a list to the columns parameter.
salarydf.pivot_table(values='salary', index = 'month', \ columns= ['office','language'], \ aggfunc= 'sum', \ margins = True, margins_name='Total') 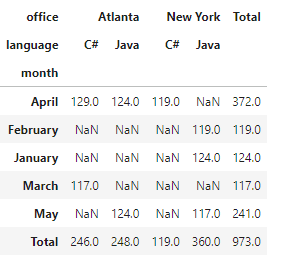
Pivot table without aggregation
We can create a pivot table without specifically specifying an aggregation method. Pandas will use ‘mean’ as the default aggregation method.
salarydf.pivot_table(values='salary', index = 'month', \ columns= 'language')Pivot columns to rows in Pandas
It’s relatively simple to transpose a pivot table by using the the T (transpose) DataFrame method as shown in the snippet below:
salarydf.pivot_table(values='salary', index = 'month', \ columns= 'language', aggfunc= 'sum').T Export pivot table to csv
Once done with defining the layout of our pivot table, we are able to very easily export it to an external format, such as a comma separated value (.csv) file.
As the Python pivot table is a DataFrame, we can simply use the to_csv() DataFrame method. Here’s a very simple example:
my_pivot = salarydf.pivot_table(values='salary', index = 'month', \ columns= ['office','language'], \ aggfunc= 'sum', \ margins = True, margins_name='Total') my_pivot.to_csv('salaries.csv', sep = ',')