- Парсинг на Python с Beautiful Soup
- Установка библиотек для парсинга
- Поиск сайта для скрапинга
- Python парсинг получить ссылку
- Парсинг полученных данных
- Методы строк
- Задание 6
- Задание 7
- Задание 8
- Задание 9
- Задание 10
- Заключение
- Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
- И так, рассмотрим первый этап парсинга — Поиск данных.
- Второй этап парсинга — Извлечение информации.
- И последний этап парсинга — Сохранение данных.
Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
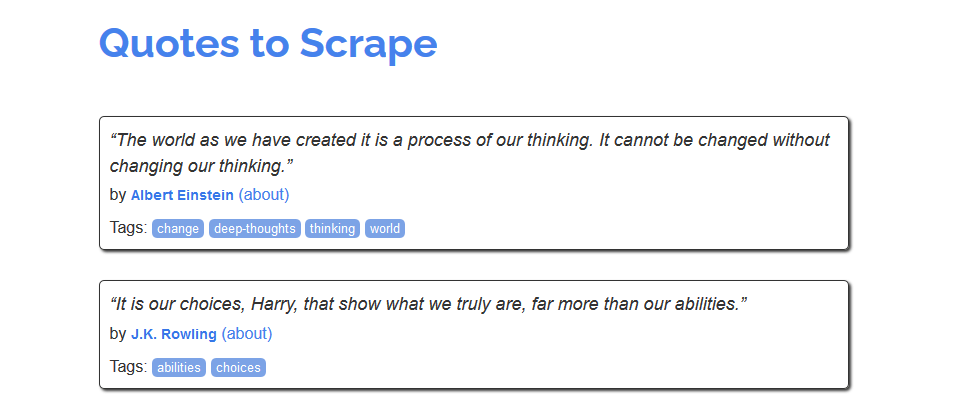
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
Python парсинг получить ссылку

Парсинг полученных данных
Извлечь адрес ссылки можно 4 разными способами – с помощью:
- Методов строк.
- Регулярного выражения.
- Запроса XPath.
- Обработки BeautifulSoup.
Рассмотрим все эти способы по порядку.
Методы строк
Это самый трудоемкий способ – для извлечения каждого элемента нужно определить 2 индекса – начало и конец вхождения. При этом к индексу вхождения надо добавить длину стартового фрагмента:
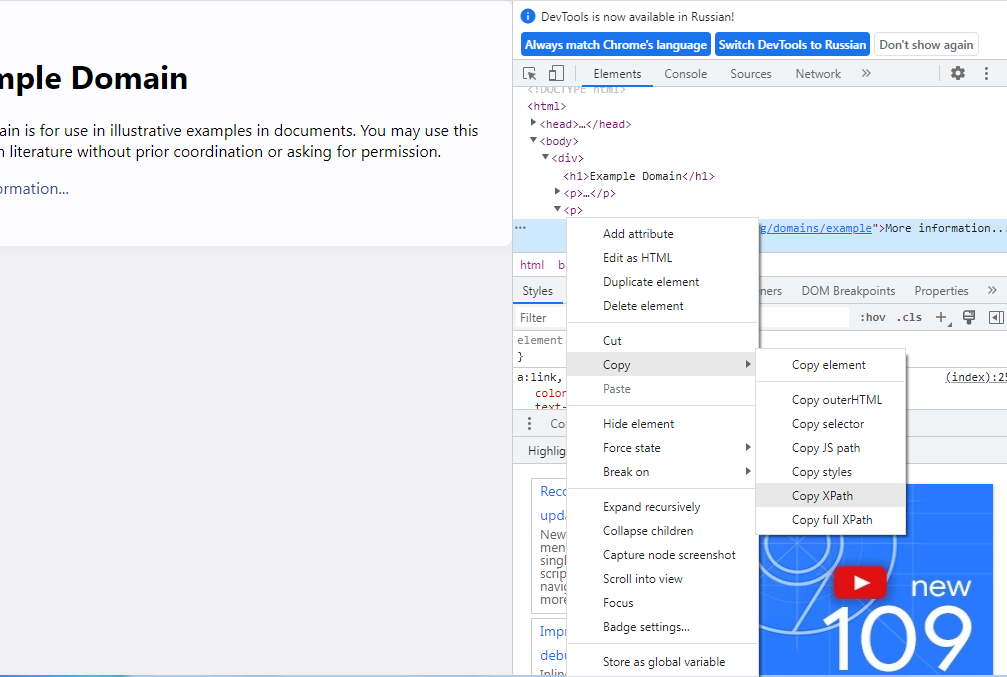
В приведенном выше примере для извлечения ссылки к пути /html/body/div/p[2]/a/ мы добавили указание для получения значения ссылки @href , и индекс [0] , поскольку результат возвращается в виде списка. Если @href заменить на text() , программа вернет текст ссылки, а не сам URL :
Пока страница не прокручена, полный HTML -код с информацией о планшетах получить невозможно. Для имитации прокрутки мы воспользуемся скриптом ‘window.scrollTo(0, document.body.scrollHeight);’ . Цены планшетов находятся в тегах h 4 класса pull-right price, а названия моделей – в тексте ссылок a класса title. Готовый код выглядит так :
from bs4 import BeautifulSoup import requests import re url = 'https://www.livelib.ru/book/1002978643-ohotnik-za-tenyu-donato-karrizi' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,'html.parser') sp = soup.find('div', class_='bc-menu__image-wrapper') img_url = re.findall(r'(?:https\:)?//.*\.(?:jpeg)', str(sp))[0] response = requests.get(img_url, headers=headers) if response.status_code == 200: file_name = url.split('-', 1)[1] with open(file_name + '.jpeg', 'wb') as file: file.write(response.content) Задание 6
Напишите программу, которая составляет рейтинг топ-100 лучших триллеров на основе этого списка.
1. "Побег из Шоушенка", Стивен Кинг - 4.60 2. "Заживо в темноте", Майк Омер - 4.50 3. "Молчание ягнят", Томас Харрис - 4.47 4. "Девушка с татуировкой дракона", Стиг Ларссон - 4.42 5. "Внутри убийцы", Майк Омер - 4.38 . 98. "Абсолютная память", Дэвид Болдаччи - 4.22 99. "Сломанные девочки", Симона Сент-Джеймс - 4.11 100. "Цифровая крепость", Дэн Браун - 3.98 from bs4 import BeautifulSoup import requests url = 'https://www.livelib.ru/genre/%D0%A2%D1%80%D0%B8%D0%BB%D0%BB%D0%B5%D1%80%D1%8B/top' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.content,'html.parser') titles = soup.find_all('a', class_='brow-book-name with-cycle') authors = soup.find_all('a', class_='brow-book-author') rating = soup.find_all('span', class_='rating-value stars-color-orange') i = 1 for t, a, r in zip(titles, authors, rating): print(f'. "", - ') i += 1 Задание 7
Напишите программу, которая составляет топ-20 языков программирования на основе рейтинга популярности TIOBE .
1. Python: 14.83% 2. C: 14.73% 3. Java: 13.56% 4. C++: 13.29% 5. C#: 7.17% 6. Visual Basic: 4.75% 7. JavaScript: 2.17% 8. SQL: 1.95% 9. PHP: 1.61% 10. Go: 1.24% 11. Assembly language: 1.11% 12. MATLAB: 1.08% 13. Delphi/Object Pascal: 1.06% 14. Scratch: 1.00% 15. Classic Visual Basic: 0.98% 16. R: 0.93% 17. Fortran: 0.79% 18. Ruby: 0.76% 19. Rust: 0.73% 20. Swift: 0.71% import requests from lxml import html url = 'https://www.tiobe.com/tiobe-index/' headers = page = requests.get(url, headers=headers) tree = html.fromstring(page.content) languages, rating = [], [] for i in range(1, 21): languages.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[]/td[5]/text()')[0]) rating.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[]/td[6]/text()')[0]) i = 1 for l, r in zip(languages, rating): print(f'. : ') i += 1 Задание 8
Напишите программу для получения рейтинга 250 лучших фильмов по версии IMDb. Названия должны быть на русском языке.
1. Побег из Шоушенка, (1994), 9,2 2. Крестный отец, (1972), 9,2 3. Темный рыцарь, (2008), 9,0 . 248. Аладдин, (1992), 8,0 249. Ганди, (1982), 8,0 250. Танцующий с волками, (1990), 8,0 import requests from lxml import html url = 'https://www.imdb.com/chart/top/' headers = page = requests.get(url, headers=headers) tree = html.fromstring(page.content) movies, year, rating = [], [], [] for i in range(1, 251): movies.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[2]/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[2]/span/text()')[0]) rating.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[3]/strong/text()')[0]) i = 1 for m, y, r in zip(movies, year, rating): print(f'. , , ') i += 1 Задание 9
Напишите программу, которая сохраняет в текстовый файл данные о фэнтези фильмах с 10 первых страниц соответствующего раздела IMDb . Если у фильма/сериала еще нет рейтинга, следует указать N / A .
Ожидаемый результат в файле fantasy . txt – 500 записей:
Мандалорец, (2019– ), 8,7 Всё везде и сразу, (2022), 8,0 Атака титанов, (2013–2023), 9,0 Peter Pan & Wendy, (2023), N/A Игра престолов, (2011–2019), 9,2 . Шрэк 3, (2007), 6,1 Кунг-фу Панда 3, (2016), 7,1 Смерть ей к лицу, (1992), 6,6 Исход: Цари и боги, (2014), 6,0 Кошмар на улице Вязов 3: Воины сна, (1987), 6,6 import requests import mechanicalsoup from lxml import html import time url = 'https://www.imdb.com/search/title/?genres=fantasy' headers = browser = mechanicalsoup.StatefulBrowser() j = 51 for _ in range(10): browser.open(url) page = requests.get(url, headers=headers) tree = html.fromstring(page.content) titles, year, rating = [], [], [] for i in range(1, 51): if tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/p[1]/b/text()') != []: titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/span[2]/text()')[0]) rating.append('N/A') else: titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/span[2]/text()')[0]) rating.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/div/div[1]/strong/text()')[0]) with open('fantasy.txt', 'a', encoding='utf-8') as file: for t, y, r in zip(titles, year, rating): file.write(f', , \n') time.sleep(2) lnk = browser.follow_link('start=' + str(j)) url = browser.url j += 50 Задание 10
Напишите программу для получения главных новостей (на русском) с портала Habr. Каждый заголовок должен сопровождаться ссылкой на полный текст новости.
Bethesda назвала дату релиза Starfield на ПК, Xbox Series и Xbox Game Pass — 6 сентября 2023 года https://habr.com/ru/news/t/721148/ Honda запатентовала съёмные подушки безопасности для мотоциклистов https://habr.com/ru/news/t/721142/ . Microsoft увольняет 689 сотрудников из своих офисов в Сиэтле https://habr.com/ru/news/t/721010/ «Ъ»: в России образовались большие запасы бытовой техники из-за низкого спроса https://habr.com/ru/news/t/721006/ from bs4 import BeautifulSoup import requests url = 'https://habr.com/ru/news/' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.content,'html.parser') articles = soup.find_all('a', class_='tm-article-snippet__title-link') for a in articles: print(f'\nhttps://habr.com') Заключение
Мы рассмотрели основные приемы работы с главными Python -инструментами для скрапинга и парсинга. Способы извлечения и обработки данных варьируются от сайта к сайту – в некоторых случаях эффективнее использование XPath , в других – разбор с BeautifulSoup , а иногда может потребоваться применение регулярных выражений.
В следующей главе приступим к изучению основ ООП (объектно-ориентированного программирования).
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП – инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
- Основы разработки игр на Pygame
- Основы работы с SQLite
- Основы веб-разработки на Flask
- Основы работы с NumPy
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests from bs4 import BeautifulSoup as bs import pandas as pd И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" r = requests.get(URL_TEMPLATE) print(r.status_code) Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') for name in vacancies_names: print(name.a['title']) Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Some information about vacancy.
vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: print('https://www.work.ua'+name.a['href']) for info in vacancies_info: print(info.text) И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests from bs4 import BeautifulSoup as bs import pandas as pd URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" FILE_NAME = "test.csv" def parse(url = URL_TEMPLATE): result_list = r = requests.get(url) soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: result_list['href'].append('https://www.work.ua'+name.a['href']) result_list['title'].append(name.a['title']) for info in vacancies_info: result_list['about'].append(info.text) return result_list df = pd.DataFrame(data=parse()) df.to_csv(FILE_NAME) После запуска появится файл test.csv — с результатами поиска.