- Pandas DataFrame update() Method
- Definition and Usage
- Syntax
- Parameters
- Return Value
- pandas.DataFrame.update#
- pandas.DataFrame.update#
- How to Update Dataframe in Pandas with Examples
- Examples of how to update dataframe in Pandas
- Example 1: Updating an Entire Column
- Example 2: Updating Dataframe with different data length
- Example 3: Update Dataframe at a specific Location
- Conclusion
- Join our list
- How to modify values in a Pandas DataFrame?
- Replace specific data in Pandas DataFrames
- Creating example data
- 1. Set cell values in the entire DF using replace()
- 2. Change value of cell content by index
- 3. Modify multiple cells in a DataFrame row
- 4. Update cells based on conditions
- 5. Set and Replace values for an entire Pandas column / Series.
- 6. Replace string in Pandas DataFrame column
Pandas DataFrame update() Method
Update the DataFrame with the data from another DataFrame, Emil is 17 not 16:
df1 = pd.DataFrame([[«Emil», «Tobias», «Linus»], [16, 14, 10]])
df2 = pd.DataFrame([[«Emil»], [17]])
Definition and Usage
The update() method updates a DataFrame with elements from another similar object (like another DataFrame).
Note: this method does NOT return a new DataFrame.
The updating is done to the original DataFrame.
Syntax
Parameters
The join , overwrite , filter_func , errors parameters are keyword arguments.
| Parameter | Value | Description |
|---|---|---|
| other | Required. A DataFrame. | |
| join | ‘left’ | Optional. Default ‘left’. Specifies which of the two objects to update. Note: only ‘left’ is allowed (for now) |
| overwrite | True False | Optional. Default True. Specifies whether to overwrite NULL values or not |
| filter_func | Function | Optional. Specifies a function to execute for each replaced element. The function should return True for elements that should be updated |
| errors | ‘raise’ ‘ignore’ | Optional. Default ‘ignore’. If ‘raise’: an error will be raised both DataFrames has a NULL value for the same element |
Return Value
This method returns None. The updating is done to the original DataFrame.
pandas.DataFrame.update#
Modify in place using non-NA values from another DataFrame.
Aligns on indices. There is no return value.
Parameters : other DataFrame, or object coercible into a DataFrame
Should have at least one matching index/column label with the original DataFrame. If a Series is passed, its name attribute must be set, and that will be used as the column name to align with the original DataFrame.
join , default ‘left’
Only left join is implemented, keeping the index and columns of the original object.
overwrite bool, default True
How to handle non-NA values for overlapping keys:
- True: overwrite original DataFrame’s values with values from other .
- False: only update values that are NA in the original DataFrame.
Can choose to replace values other than NA. Return True for values that should be updated.
errors , default ‘ignore’
If ‘raise’, will raise a ValueError if the DataFrame and other both contain non-NA data in the same place.
This method directly changes calling object.
- When errors=’raise’ and there’s overlapping non-NA data.
- When errors is not either ‘ignore’ or ‘raise’
- If join != ‘left’
Similar method for dictionaries.
For column(s)-on-column(s) operations.
>>> df = pd.DataFrame('A': [1, 2, 3], . 'B': [400, 500, 600]>) >>> new_df = pd.DataFrame('B': [4, 5, 6], . 'C': [7, 8, 9]>) >>> df.update(new_df) >>> df A B 0 1 4 1 2 5 2 3 6
The DataFrame’s length does not increase as a result of the update, only values at matching index/column labels are updated.
>>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_df = pd.DataFrame('B': ['d', 'e', 'f', 'g', 'h', 'i']>) >>> df.update(new_df) >>> df A B 0 a d 1 b e 2 c f
For Series, its name attribute must be set.
>>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_column = pd.Series(['d', 'e'], name='B', index=[0, 2]) >>> df.update(new_column) >>> df A B 0 a d 1 b y 2 c e >>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_df = pd.DataFrame('B': ['d', 'e']>, index=[1, 2]) >>> df.update(new_df) >>> df A B 0 a x 1 b d 2 c e
If other contains NaNs the corresponding values are not updated in the original dataframe.
>>> df = pd.DataFrame('A': [1, 2, 3], . 'B': [400, 500, 600]>) >>> new_df = pd.DataFrame('B': [4, np.nan, 6]>) >>> df.update(new_df) >>> df A B 0 1 4 1 2 500 2 3 6
pandas.DataFrame.update#
Modify in place using non-NA values from another DataFrame.
Aligns on indices. There is no return value.
Parameters : other DataFrame, or object coercible into a DataFrame
Should have at least one matching index/column label with the original DataFrame. If a Series is passed, its name attribute must be set, and that will be used as the column name to align with the original DataFrame.
join , default ‘left’
Only left join is implemented, keeping the index and columns of the original object.
overwrite bool, default True
How to handle non-NA values for overlapping keys:
- True: overwrite original DataFrame’s values with values from other .
- False: only update values that are NA in the original DataFrame.
Can choose to replace values other than NA. Return True for values that should be updated.
errors , default ‘ignore’
If ‘raise’, will raise a ValueError if the DataFrame and other both contain non-NA data in the same place.
This method directly changes calling object.
- When errors=’raise’ and there’s overlapping non-NA data.
- When errors is not either ‘ignore’ or ‘raise’
- If join != ‘left’
Similar method for dictionaries.
For column(s)-on-column(s) operations.
>>> df = pd.DataFrame('A': [1, 2, 3], . 'B': [400, 500, 600]>) >>> new_df = pd.DataFrame('B': [4, 5, 6], . 'C': [7, 8, 9]>) >>> df.update(new_df) >>> df A B 0 1 4 1 2 5 2 3 6
The DataFrame’s length does not increase as a result of the update, only values at matching index/column labels are updated.
>>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_df = pd.DataFrame('B': ['d', 'e', 'f', 'g', 'h', 'i']>) >>> df.update(new_df) >>> df A B 0 a d 1 b e 2 c f
For Series, its name attribute must be set.
>>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_column = pd.Series(['d', 'e'], name='B', index=[0, 2]) >>> df.update(new_column) >>> df A B 0 a d 1 b y 2 c e >>> df = pd.DataFrame('A': ['a', 'b', 'c'], . 'B': ['x', 'y', 'z']>) >>> new_df = pd.DataFrame('B': ['d', 'e']>, index=[1, 2]) >>> df.update(new_df) >>> df A B 0 a x 1 b d 2 c e
If other contains NaNs the corresponding values are not updated in the original dataframe.
>>> df = pd.DataFrame('A': [1, 2, 3], . 'B': [400, 500, 600]>) >>> new_df = pd.DataFrame('B': [4, np.nan, 6]>) >>> df.update(new_df) >>> df A B 0 1 4 1 2 500 2 3 6
How to Update Dataframe in Pandas with Examples

Sometimes you want to change or update the column data in the pandas dataframe. Then there is a function in pandas that allows you to update the records of the column. The function is pandas.DataFrame.update(). It easily updates the columns or the column records. In the entire tutorial, you will know how to update dataframe in pandas with examples.
Examples of how to update dataframe in Pandas
In this section, you will know how to apply pandas.DataFrame.update() function on dataframe to update the records.
Example 1: Updating an Entire Column
In this example, I will update the entire column of a dafarame with the other dataframe. You have to use the dot operator on the existing dataframe with the second dataframe as the argument inside the update() method. Run the below lines of code and see the output.
) print("Original Dataframe\n",df1) print("###########################") df2 = pd.DataFrame() df1.update(df2) print("Changed Dataframe \n",df1)
Output
Example 2: Updating Dataframe with different data length
Now, let’s take a case when I have to update dataframe that has a record length greater than the original dataframe. If I will apply the update() method then records will be updated till the length equals the original dataframe. Execute the below lines of code and see the output.
) print("Original Dataframe\n",df1) print("###########################") df2 = pd.DataFrame() df1.update(df2) print("Changed Dataframe \n",df1) 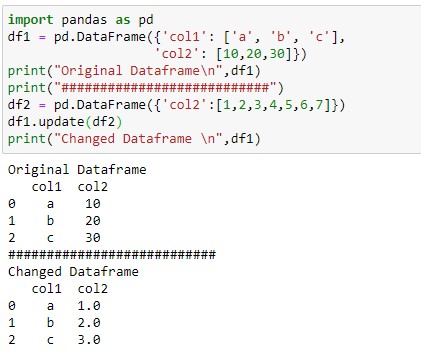
You can see this in the above output. I have 3 records in the df1 for the col2 and df2 has seven records. But when I applied df1.update(df2) the first three rows of the df1 are only updated.
Example 3: Update Dataframe at a specific Location
In this example, I will update the values of a particular specific location. To do so you have to create a dataframe with the index argument and then apply the update method.
Execute the below lines of code and see the output.
) print("Original Dataframe\n",df1) print("###########################") df2 = pd.DataFrame(,index=[0,2]) df1.update(df2) print("Changed Dataframe \n",df1) 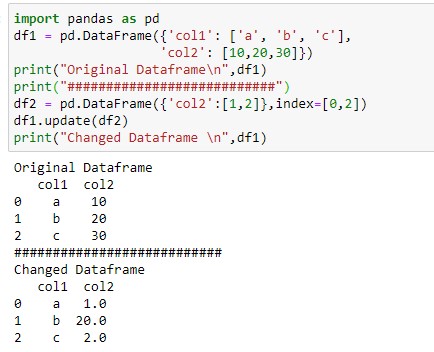
In the above output, you can see only the zero and third rows are only updated. The second row’s value is the same.
Conclusion
Pandas Dataframe update is one of the best functions provided by pandas packages. It saves you time to make a new dataset every time some values changes in the existing dataset. These are examples of how to update dataframe in Pandas. I hope you have liked this tutorial and it has solved your queries on updating dataframe. Even if you have any doubt then you can contact us for more help.
Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox.
We respect your privacy and take protecting it seriously
Thank you for signup. A Confirmation Email has been sent to your Email Address.
How to modify values in a Pandas DataFrame?

As part of our data wrangling process, we are often required to modify data previously acquired from a csv, text, json, API, database or other data source.
In this short tutorial we would like to discuss the basics of replacing/changing/updating manipulation inside Pandas DataFrames.
Replace specific data in Pandas DataFrames
In this tutorial we will look into several cases:
- Replacing values in an entire DataFrame
- Updating values in specific cells by index
- Changing values in an entire DF row
- Replace cells content according to condition
- Modify values in a Pandas column / series.
Creating example data
Let’s define a simple survey DataFrame:
# Import DA packages import pandas as pd import numpy as np # Create test Data survey_dict = < 'language': ['Python', 'Java', 'Haskell', 'Go', 'C++'], 'salary': [120,85,95,80,90], 'num_candidates': [18,22,34,10, np.nan] ># Initialize the survey DataFrame survey_df = pd.DataFrame(survey_dict) # Review our DF 1. Set cell values in the entire DF using replace()
We’ll use the DataFrame replace method to modify DF sales according to their value. In the example we’ll replace the empty cell in the last row with the value 17.
survey_df.replace(to_replace= np.nan, value = 17, inplace=True ) survey_df.head()Note: The replace method is pretty self explanatory, note the usage of the inplace=True to persist the updates in the DataFrame going forward.
Here’s the output we will get:
| language | salary | num_candidates | |
|---|---|---|---|
| 0 | Python | 120 | 18.0 |
| 1 | Java | 90 | 22.0 |
| 2 | Haskell | 95 | 34.0 |
| 3 | Go | 90 | 10.0 |
| 4 | C++ | 90 | 17.0 |
Note: that we could accomplish the same result with the more elegant fillna() method.
survey_df.fillna(value = 17, axis = 1)2. Change value of cell content by index
To pick a specific row index to be modified, we’ll use the iloc indexer.
survey_df.iloc[0].replace(to_replace=120, value = 130)Our output will look as following:
language Python salary 130 num_candidates 18.0 Name: 0, dtype: object
Note: We could also use the loc indexer to update one or multiple cells by row/column label. The code below sets the value 130 the first three cells or the salary column.
survey_df.loc[[0,1,2],'salary'] = 1303. Modify multiple cells in a DataFrame row
Similar to before, but this time we’ll pass a list of values to replace and their respective replacements:
survey_df.loc[0].replace(to_replace=(130,18), value=(120, 20)) 4. Update cells based on conditions
In reality, we’ll update our data based on specific conditions. Here’s an example on how to update cells with conditions. Let’s assume that we would like to update the salary figures in our data so that the minimal salary will be $90/hour.
We’ll first slide the DataFrame and find the relevant rows to update:
We’ll then pass the rows and columns labels to be updated into the loc indexer:
survey_df.loc[cond,'salary'] = 90 survey_df | language | salary | num_candidates | |
|---|---|---|---|
| 0 | Python | 120 | 18.0 |
| 1 | Java | 90 | 22.0 |
| 2 | Haskell | 95 | 34.0 |
| 3 | Go | 90 | 10.0 |
| 4 | C++ | 90 | 17.0 |
Important note: We can obviously write more complex conditions as needed. Below if an example with multiple conditions.
5. Set and Replace values for an entire Pandas column / Series.
Let’s now assume that we would like to modify the num_candidates figure for all observations in our DataFrame. That’s fairly easy to accomplish.
survey_df['num_candidates'] = 25Let’s now assume that management has decided that all candidates will be offered an 20% raise. We can easily change the salary column using the following Python code:
survey_df['salary'] = survey_df['salary'] * 1.26. Replace string in Pandas DataFrame column
We can also replace specific strings in a DataFrame column / series using the syntx below:
survey_df['language'] = survey_df['language'].replace(to_replace = 'Java', value= 'Go')