How to Sort DataFrame by Column in Pandas?
To sort the rows of a DataFrame by a column, use pandas.DataFrame.sort_values() method with the argument by=column_name. The sort_values() method does not modify the original DataFrame, but returns the sorted DataFrame.
You can sort the DataFrame in ascending or descending order of the column values.
In this tutorial, we shall go through some example programs, where we shall sort DataFrame in ascending or descending order.
Examples
1. Sort DataFrame by a column in ascending order
The default sorting order of sort_values() function is ascending order. In this example, we will create a dataframe and sort the rows by a specific column in ascending order.
Python Program
import pandas as pd data = #create dataframe df_marks = pd.DataFrame(data) #sort dataframe sorted_df = df_marks.sort_values(by='algebra') print(sorted_df) name physics chemistry algebra 0 Somu 68 84 78 2 Amol 77 73 82 3 Lini 78 69 87 1 Kiku 74 56 88 You can see that the rows are sorted based on the increasing order of the column algebra.
2. Sort DataFrame by a column in descending order
To sort the dataframe in descending order a column, pass ascending=False argument to the sort_values() method. . In this example, we will create a dataframe and sort the rows by a specific column in descending order.
Python Program
import pandas as pd data = #create dataframe df_marks = pd.DataFrame(data) #sort dataframe sorted_df = df_marks.sort_values(by='algebra', ascending=False) print(sorted_df) name physics chemistry algebra 1 Kiku 74 56 88 3 Lini 78 69 87 2 Amol 77 73 82 0 Somu 68 84 78 You can see that the rows are sorted based on the decreasing order of the column algebra.
Summary
In this Pandas Tutorial, we learned to sort DataFrame in ascending and descending orders, using sort_values(), with the help of well detailed Python example programs.
pandas.DataFrame.sort_values#
Sort ascending vs. descending. Specify list for multiple sort orders. If this is a list of bools, must match the length of the by.
inplace bool, default False
If True, perform operation in-place.
Choice of sorting algorithm. See also numpy.sort() for more information. mergesort and stable are the only stable algorithms. For DataFrames, this option is only applied when sorting on a single column or label.
na_position , default ‘last’
Puts NaNs at the beginning if first ; last puts NaNs at the end.
ignore_index bool, default False
If True, the resulting axis will be labeled 0, 1, …, n — 1.
key callable, optional
Apply the key function to the values before sorting. This is similar to the key argument in the builtin sorted() function, with the notable difference that this key function should be vectorized. It should expect a Series and return a Series with the same shape as the input. It will be applied to each column in by independently.
DataFrame with sorted values or None if inplace=True .
Sort a DataFrame by the index.
Similar method for a Series.
>>> df = pd.DataFrame( . 'col1': ['A', 'A', 'B', np.nan, 'D', 'C'], . 'col2': [2, 1, 9, 8, 7, 4], . 'col3': [0, 1, 9, 4, 2, 3], . 'col4': ['a', 'B', 'c', 'D', 'e', 'F'] . >) >>> df col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F
>>> df.sort_values(by=['col1']) col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 5 C 4 3 F 4 D 7 2 e 3 NaN 8 4 D
>>> df.sort_values(by=['col1', 'col2']) col1 col2 col3 col4 1 A 1 1 B 0 A 2 0 a 2 B 9 9 c 5 C 4 3 F 4 D 7 2 e 3 NaN 8 4 D
>>> df.sort_values(by='col1', ascending=False) col1 col2 col3 col4 4 D 7 2 e 5 C 4 3 F 2 B 9 9 c 0 A 2 0 a 1 A 1 1 B 3 NaN 8 4 D
>>> df.sort_values(by='col1', ascending=False, na_position='first') col1 col2 col3 col4 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F 2 B 9 9 c 0 A 2 0 a 1 A 1 1 B
Sorting with a key function
>>> df.sort_values(by='col4', key=lambda col: col.str.lower()) col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F
Natural sort with the key argument, using the natsort package.
>>> df = pd.DataFrame( . "time": ['0hr', '128hr', '72hr', '48hr', '96hr'], . "value": [10, 20, 30, 40, 50] . >) >>> df time value 0 0hr 10 1 128hr 20 2 72hr 30 3 48hr 40 4 96hr 50 >>> from natsort import index_natsorted >>> df.sort_values( . by="time", . key=lambda x: np.argsort(index_natsorted(df["time"])) . ) time value 0 0hr 10 3 48hr 40 2 72hr 30 4 96hr 50 1 128hr 20
pandas.DataFrame.sort_values#
Sort ascending vs. descending. Specify list for multiple sort orders. If this is a list of bools, must match the length of the by.
inplace bool, default False
If True, perform operation in-place.
Choice of sorting algorithm. See also numpy.sort() for more information. mergesort and stable are the only stable algorithms. For DataFrames, this option is only applied when sorting on a single column or label.
na_position , default ‘last’
Puts NaNs at the beginning if first ; last puts NaNs at the end.
ignore_index bool, default False
If True, the resulting axis will be labeled 0, 1, …, n — 1.
key callable, optional
Apply the key function to the values before sorting. This is similar to the key argument in the builtin sorted() function, with the notable difference that this key function should be vectorized. It should expect a Series and return a Series with the same shape as the input. It will be applied to each column in by independently.
Returns : DataFrame or None
DataFrame with sorted values or None if inplace=True .
Sort a DataFrame by the index.
Similar method for a Series.
>>> df = pd.DataFrame( . 'col1': ['A', 'A', 'B', np.nan, 'D', 'C'], . 'col2': [2, 1, 9, 8, 7, 4], . 'col3': [0, 1, 9, 4, 2, 3], . 'col4': ['a', 'B', 'c', 'D', 'e', 'F'] . >) >>> df col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F
>>> df.sort_values(by=['col1']) col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 5 C 4 3 F 4 D 7 2 e 3 NaN 8 4 D
>>> df.sort_values(by=['col1', 'col2']) col1 col2 col3 col4 1 A 1 1 B 0 A 2 0 a 2 B 9 9 c 5 C 4 3 F 4 D 7 2 e 3 NaN 8 4 D
>>> df.sort_values(by='col1', ascending=False) col1 col2 col3 col4 4 D 7 2 e 5 C 4 3 F 2 B 9 9 c 0 A 2 0 a 1 A 1 1 B 3 NaN 8 4 D
>>> df.sort_values(by='col1', ascending=False, na_position='first') col1 col2 col3 col4 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F 2 B 9 9 c 0 A 2 0 a 1 A 1 1 B
Sorting with a key function
>>> df.sort_values(by='col4', key=lambda col: col.str.lower()) col1 col2 col3 col4 0 A 2 0 a 1 A 1 1 B 2 B 9 9 c 3 NaN 8 4 D 4 D 7 2 e 5 C 4 3 F
Natural sort with the key argument, using the natsort package.
>>> df = pd.DataFrame( . "time": ['0hr', '128hr', '72hr', '48hr', '96hr'], . "value": [10, 20, 30, 40, 50] . >) >>> df time value 0 0hr 10 1 128hr 20 2 72hr 30 3 48hr 40 4 96hr 50 >>> from natsort import index_natsorted >>> df.sort_values( . by="time", . key=lambda x: np.argsort(index_natsorted(df["time"])) . ) time value 0 0hr 10 3 48hr 40 2 72hr 30 4 96hr 50 1 128hr 20
Python pandas sort by column

Датафрейм включает следующие столбцы:

Метод sort_values применяется для сортировки датафрейма и выглядит следующим образом:
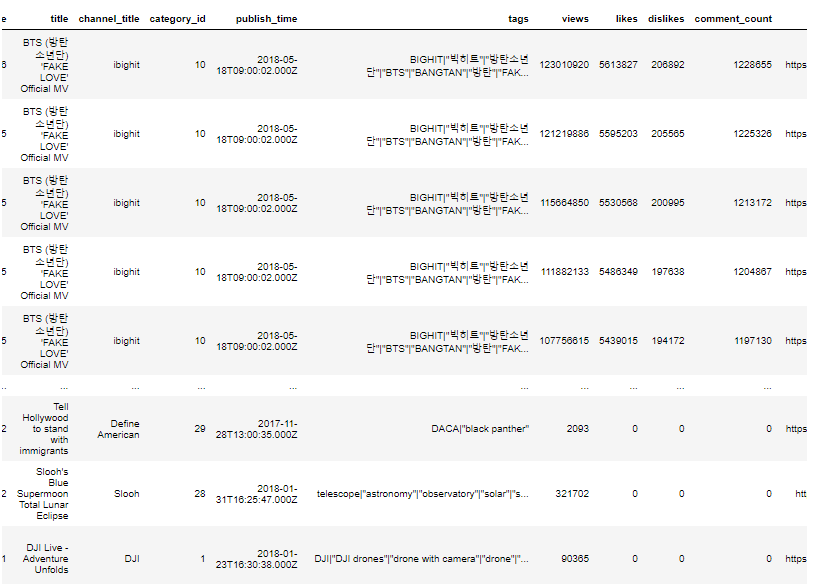
Сортировка по нескольким столбцам
Чтобы отсортировать датафрейм по нескольким столбцам, методу sort_values нужно через запятую указать имена столбцов, которые мы собираемся использовать.
Давайте отсортируем датафрейм по показателям likes и dislikes , то есть найдем видео с наибольшим числом лайков и дизлайков.
В параметре ascending порядок сортировки для столбцов также указывается через запятую, что позволяет задавать разный порядок сортировки для разных столбцов в датафрейме.
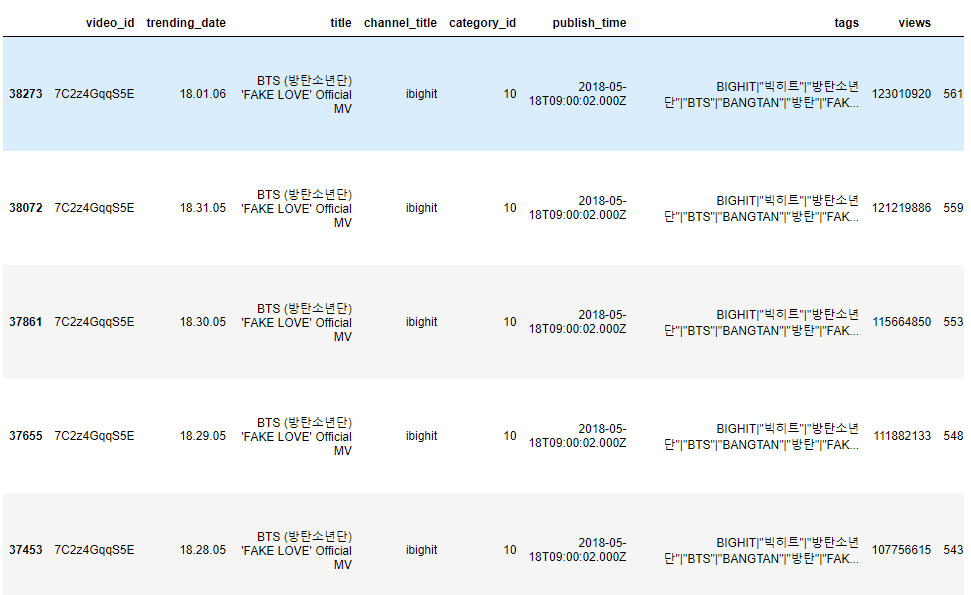
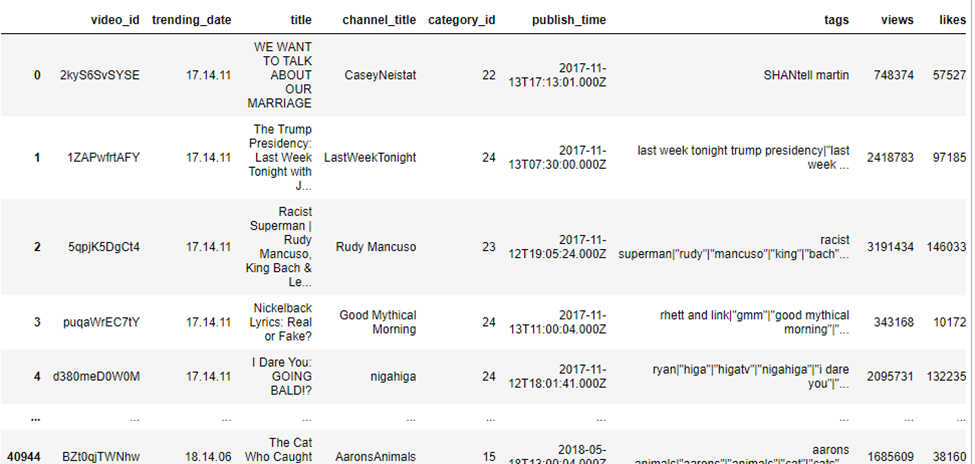
Когда мы сортируем датафрейм, используя метод sort_values , Pandas учитывает столбец, ответственный за сортировку. Чтобы отсортировать датафрейм sdf по индексу строк, воспользуемся методом sort_index :
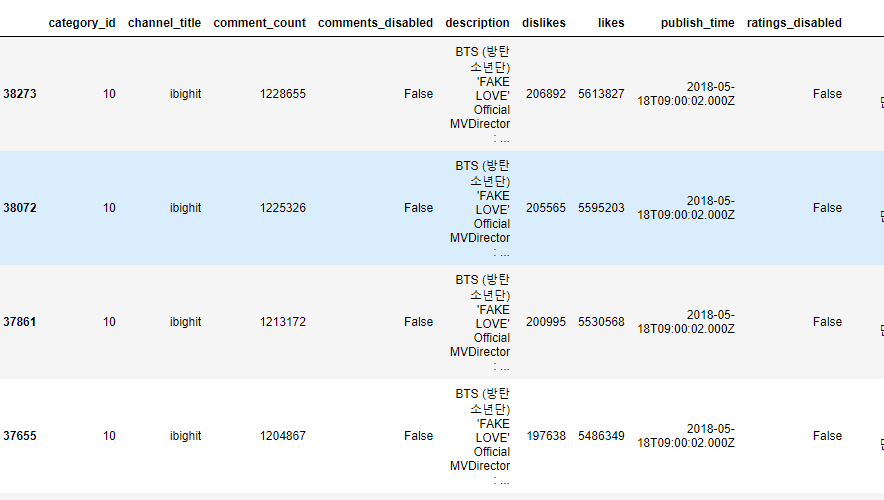
Чтобы отсортировать датафрейм по меткам столбцов, присвоим параметру axis значение 1 :
- научились сортировать датафрейм по одному и нескольким значениям;
- узнали, как работают методы sort_values() и sort_index() .