- Логическое ИЛИ/побитовое ИЛИ в кадре данных pandas
- Как использовать оператор «ИЛИ» в Pandas (с примерами)
- Пример 1: Используйте оператор «ИЛИ» для фильтрации строк на основе числовых значений в Pandas
- Пример 2: Используйте оператор «ИЛИ» для фильтрации строк на основе строковых значений в Pandas
- Дополнительные ресурсы
- Filter a pandas dataframe – OR, AND, NOT
- Prepare a dataframe for demo
- Combination of things
- Intersection of things
- Opposite of things
- 8 способов фильтрации фреймов данных Pandas
- 1. Логические операторы
- 2. Несколько логических операторов
- 3. Исин
- 4. Аксессуар Str.
- 5. Тильда (~)
- 6. Запрос
- 7. Наибольший или наименьший
- 8. Loc и iloc
- Заключение
Логическое ИЛИ/побитовое ИЛИ в кадре данных pandas
Однако, используя побитовый оператор OR, результаты возвращаются успешно.
x = df[(df['A'].isin(df2['B'])) | df['A'].isin(df2['C'])] Output: x Есть ли разница в обоих и побитовое ИЛИ будет лучшим вариантом здесь? Почему логическое ИЛИ не работает?
Насколько я понял эту проблему (начиная с фона C++ и в настоящее время изучая Python для наук о данных), я наткнулся на несколько сообщений, предполагающих, что побитовые операторы (&, |) могут быть перегружены в классах, подобно [CN10 ] делает.
Таким образом, в основном, хотя вы можете использовать такие побитовые операторы на числах, они будут сравнивать биты и дать вам результат. Например, если у вас есть следующее:
На самом деле Python будет сравнивать бит этих чисел:
00000011 (потому что 0 | 0 – False, ergo 0 и 0 | 1 – True, ergo 1)
В качестве целого числа: 3
Он сравнивает каждый бит чисел и выплевывает результат этих восьми последовательных операций. Это нормальное поведение этих операторов.
Введите Pandas. Поскольку вы можете перегружать этих операторов, Pandas воспользовался этим. Итак, какие побитовые операторы делают, когда приходят в pandas dataframes, следующее:
(dataframe1 [‘column’] == “выражение”) & (dataframe1 [‘column’]! = “другое выражение)
В этом случае первые панды создадут серию истин или фальсов в зависимости от результата операций == и! = (Будьте осторожны: вам нужно поместить фигурные скобки вокруг внешних выражений, потому что python всегда будет пытаться разрешить первые побитовые операторы и ТОГДА другие сравнительные операторы !!). Поэтому он сравнивает каждое значение в столбце с выражением и выводит значение true или false.
Тогда у вас будет две одинаковые серии истин и фальши. То, что он делает, это взять эти две серии и в основном сравнить их с “и” (&) или “или” (|), и, наконец, выплюнуть одну серию, выполнив или не выполнив все три операции сравнения.
Чтобы пойти еще дальше, я думаю, что это происходит под капотом, так это то, что & -operator на самом деле называет функцию панд, дает им как предварительно оцененные операции (поэтому два ряда слева и справа от оператора), так и панды сравнивает два разных значения за раз, возвращая значение True или False в зависимости от внутреннего механизма для определения этого.
Это в основном тот же принцип, который они использовали и для всех других операторов (>, =,
Зачем бороться и использовать разные и -expression, когда вы получили красивое и аккуратное “и”? Это похоже на то, что “и” просто закодировано и не может быть изменено вручную.
Как использовать оператор «ИЛИ» в Pandas (с примерами)
Вы можете использовать | символ как оператор «ИЛИ» в pandas.
Например, вы можете использовать следующий базовый синтаксис для фильтрации строк в кадре данных pandas, которые удовлетворяют условию 1 или условию 2:
В следующих примерах показано, как использовать этот оператор «ИЛИ» в различных сценариях.
Пример 1: Используйте оператор «ИЛИ» для фильтрации строк на основе числовых значений в Pandas
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team points assists rebounds 0 A 25 5 11 1 A 12 7 8 2 B 15 7 10 3 B 14 9 6 4 B 19 12 6 5 B 23 9 5 6 C 25 9 9 7 C 29 4 12 Мы можем использовать следующий синтаксис для фильтрации строк в DataFrame, где значение в столбце точек больше 20 или значение в столбце помощи равно 9:
#filter rows where points > 20 or assists = 9 df[(df.points > 20) | (df.assists == 9)] team points assists rebounds 0 A 25 5 11 3 B 14 9 6 5 B 23 9 5 6 C 25 9 9 7 C 29 4 12 Возвращаются только строки, в которых значение очков больше 20 или значение помощи равно 9.
Пример 2: Используйте оператор «ИЛИ» для фильтрации строк на основе строковых значений в Pandas
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team position conference points 0 A G W 11 1 B G W 8 2 C F W 10 3 D F W 6 4 E C E 6 5 F F E 5 6 G C E 9 7 H C E 12 Мы можем использовать следующий синтаксис для фильтрации строк в DataFrame, где значение в столбце position равно G или значение в столбце position равно F или значение в столбце team равно H:
#filter rows based on string values df[(df.team == 'H') | (df.position == 'G') | (df.position == 'F')] team position conference points 0 A G W 11 1 B G W 8 2 C F W 10 3 D F W 6 5 F F E 5 7 H C E 12 Возвращаются только те строки, которые соответствуют хотя бы одному из трех указанных условий.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Filter a pandas dataframe – OR, AND, NOT
This is the second part of the Filter a pandas dataframe tutorial. Today we’ll be talking about advanced filter in pandas dataframe, involving OR, AND, NOT logic.
This tutorial is part of the “Integrate Python with Excel” series, you can find the table of content here for easier navigation.
Prepare a dataframe for demo
We’ll be using the S&P 500 company dataset for this tutorial. First, we’ll fire up pandas and load the data from Wikipedia. Also attached below a screenshot of the data table for easy reference.
import pandas as pd df = pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies')[0]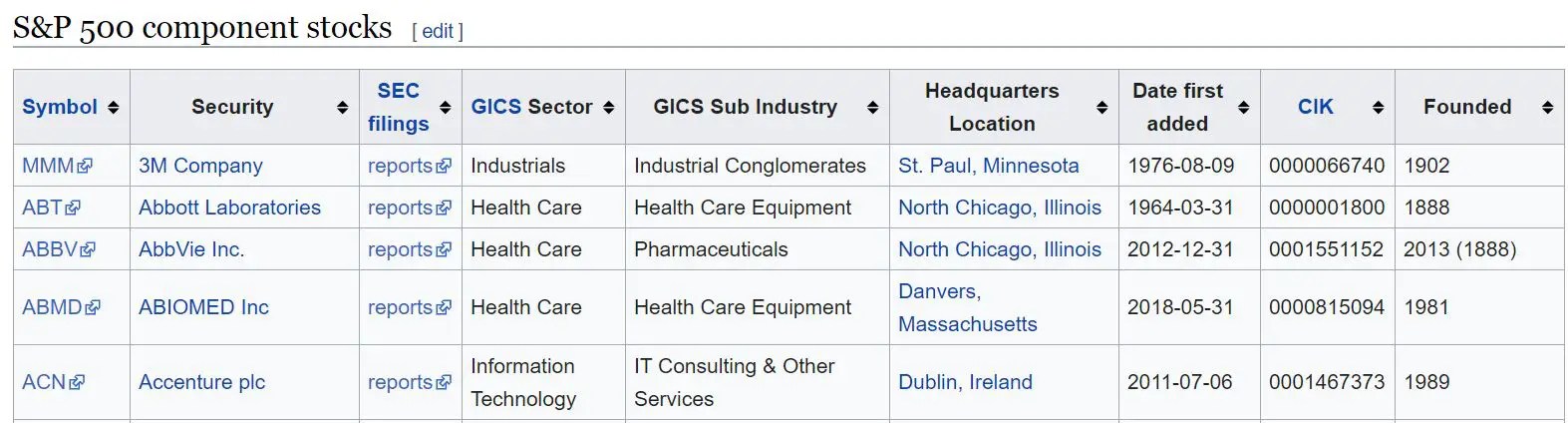
Combination of things
- The regular or logic operator does not work in this case, and we have to use the bitwise logic operator “ | “, which means “or”.
- Each criteria needs to be wrapped with a pair of parentheses.
df_1 = df.loc[(df['GICS Sector'] == 'Health Care') | (df['GICS Sector'] == 'Information Technology')] >>> df_1['Symbol'].count() 133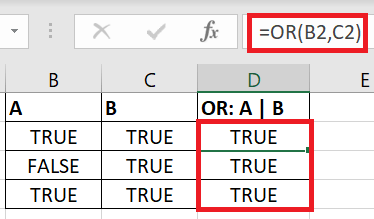
In the above code, we have two boolean index in the .loc[] . The below is a simplified Excel example to demonstrate what the | operator means.
Intersection of things
We use AND logic when both (or more) conditions need to be satisfied. For example, We can find out how many companies are in “Health Care” sector and also operate in “Health Care Equipment” sub-sector.
df_2 = df.loc[(df['GICS Sector'] == 'Health Care') & (df['GICS Sub Industry'] == 'Health Care Equipment')] >>> df_2['Symbol'].count() 20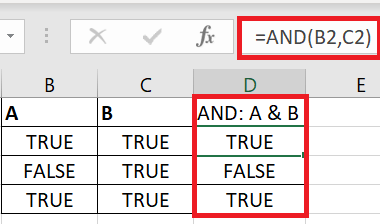
Again, we need to use the bitwise AND operator “ & “, and wrap around the conditions with a pair of parentheses. An Excel example below shows what the & operator means.
Opposite of things
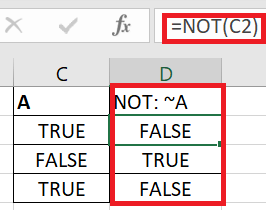
To select the opposite of something, we need to use the NOT logic operator. The bitwise NOT is “ ~ “. An Excel example is below.
To select all companies other than “Information Technology”. We can do the following:
df_3 = df.loc[ ~(df['Symbol'] == 'Information Technology')] #an equivalent way is: df_3 = df.loc[df['Symbol'] != 'Information Technology']8 способов фильтрации фреймов данных Pandas

Pandas — популярная библиотека анализа и обработки данных для Python. Основная структура данных Pandas — это фрейм данных, который хранит данные в табличной форме с помеченными строками и столбцами.
Распространенной операцией при анализе данных является фильтрация значений на основе условия или нескольких условий. Pandas предоставляет множество способов фильтрации точек данных (то есть строк). В этой статье мы рассмотрим 8 различных способов фильтрации фрейма данных.
Начнем с импорта библиотек.
import numpy as np import pandas as pd
Давайте создадим образец фрейма данных для примеров.

1. Логические операторы
Мы можем использовать логические операторы для значений столбцов для фильтрации строк.
df[df.val > 0.5] name ctg val val2 ------------------------------------------- 1 John A 0.67 1 3 Mike B 0.91 5 4 Emily B 0.99 8 6 Catlin B 1.00 3
Мы выбрали строки, в которых значение в столбце «val» больше 0,5.
Логические операторы также работают со строками.
df[df.name > 'Jane'] name ctg val val2 ------------------------------------------- 1 John A 0.67 1 3 Mike B 0.91 5
Выбираются только имена, которые идут после слова «Джейн» в алфавитном порядке.
2. Несколько логических операторов
Pandas позволяет комбинировать несколько логических операторов. Например, мы можем применить условия к столбцам val и val2, как показано ниже.
df[(df.val > 0.5) & (df.val2 == 1)] name ctg val val2 ------------------------------------------- 1 John A 0.67 1
Знаки «&» обозначают «и», «|» означает «или».
3. Исин
Метод isin — это еще один способ применения множественных условий для фильтрации. Например, мы можем фильтровать имена, которые существуют в данном списке.
names = ['John','Catlin','Mike'] df[df.name.isin(names)] name ctg val val2 ------------------------------------------- 1 John A 0.67 1 3 Mike B 0.91 5 6 Catlin B 1.00 3
4. Аксессуар Str.
Pandas также является высокоэффективной библиотекой текстовых данных. Функции и методы метода доступа str предоставляют гибкие способы фильтрации строк на основе строк.
Например, мы можем выбрать имена, начинающиеся с буквы «J».
df[df.name.str.startswith('J')] name ctg val val2 ------------------------------------------- 0 Jane A 0.43 1 1 John A 0.67 1 5 Jack C 0.02 7 Функция contains под аксессором str возвращает значения, содержащие заданный набор символов.
df[df.name.str.contains('y')] name ctg val val2 ------------------------------------------- 2 Ashley C 0.40 7 4 Emily B 0.99 8 Мы можем передать более длинный набор символов в функцию contains в зависимости от строк в данных.
5. Тильда (~)
Оператор тильды используется для логики «не» при фильтрации. Если мы добавим оператор тильды перед выражением фильтра, будут возвращены строки, не соответствующие условию.
df[~df.name.str.startswith('J')] name ctg val val2 ------------------------------------------- 2 Ashley C 0.40 7 3 Mike B 0.91 5 4 Emily B 0.99 8 6 Catlin B 1.00 3 Получаются имена, не начинающиеся с буквы «J».
6. Запрос
Функция запроса предлагает немного больше гибкости при написании условий фильтрации. Мы можем передать условия в виде строки.
Например, следующий код возвращает строки, которые принадлежат категории B и имеют значение выше 0,5 в столбце val.
df.query('ctg == "B" and val > 0.5') name ctg val val2 ------------------------------------------- 3 Mike B 0.91 5 4 Emily B 0.99 8 6 Catlin B 1.00 3 7. Наибольший или наименьший
В некоторых случаях у нас нет определенного диапазона для фильтрации, а нужны только самые большие или самые маленькие значения. Функции nlargest и nsmallest позволяют выбирать строки, которые имеют наибольшее или наименьшее значение в столбце соответственно.
df.nlargest(3, 'val') name ctg val val2 ------------------------------------------- 6 Catlin B 1.00 3 4 Emily B 0.99 8 3 Mike B 0.91 5
Мы указываем количество наибольших или наименьших значений для выбора и имя столбца.
df.nsmallest(2, 'val2') name ctg val val2 ------------------------------------------- 0 Jane A 0.43 1 1 John A 0.67 1
8. Loc и iloc
Методы loc и iloc используются для выбора строк или столбцов на основе индекса или метки.
- loc: выберите строки или столбцы с помощью меток
- iloc: выберите строки или столбцы с помощью индексов
Таким образом, их можно использовать для фильтрации. Однако мы можем выбрать только определенную часть фрейма данных без указания условия.
df.iloc[3:5, :] #rows 3 and 4, all columns name ctg val val2 ------------------------------------------- 3 Mike B 0.91 5 4 Emily B 0.99 8
Если фрейм данных имеет целочисленный индекс, индексы и метки строк совпадают. Таким образом, и loc, и iloc выполнили одно и то же в строках.
df.loc[3:5, :] #rows 3 and 4, all columns name ctg val val2 ------------------------------------------- 3 Mike B 0.91 5 4 Emily B 0.99 8
Давайте обновим индекс фрейма данных, чтобы лучше продемонстрировать разницу между loc и iloc.

Сейчас мы не можем передавать целые числа в метод loc, потому что метки индексов представляют собой буквы.
df.loc['b':'d', :] name ctg val val2 ------------------------------------------- b John A 0.67 1 c Ashley C 0.40 7 d Mike B 0.91 5
Заключение
Мы рассмотрели 8 различных способов фильтрации строк во фрейме данных. Все они полезны и пригодятся в определенных случаях.
Pandas — мощная библиотека для анализа и обработки данных. Он предоставляет множество функций и методов для обработки данных в табличной форме. Как и в случае с любым другим инструментом, лучший способ выучить Pandas — это практиковаться.
Спасибо за чтение. Пожалуйста, дайте мне знать, если у вас есть какие-либо отзывы.