- Pandas Iterate Over Rows with Examples
- 1. Using DataFrame.iterrows() to Iterate Over Rows
- 2. Using DataFrame.itertuples() to Iterate Over Rows
- 4. DataFrame.apply() to Iterate
- 5. Iterating using for & DataFrame.index
- 6. Using for & DataFrame.loc
- 7. Using For & DataFrame.iloc
- 8. Using DataFrame.items() to Iterate Over Columns
- 9. Performance of Iterating DataFrame
- 10. Complete Example of pandas Iterate over Rows
- Conclusion
- Related Articles
- References
- You may also like reading:
- pandas.DataFrame.iterrows#
- How to Iterate Over Rows with Pandas – Loop Through a Dataframe
- What is Pandas?
- What is a Pandas Dataframe?
- How to Loop Through Rows in a Dataframe
- How to Loop Through Columns in a Dataframe
- Use Cases for Looping Through a Dataframe
- Conclusion
Pandas Iterate Over Rows with Examples
Like any other data structure, Pandas DataFrame also has a way to iterate (loop through row by row) over rows and access columns/elements of each row. DataFrame provides methods iterrows() , itertuples() to iterate over each Row.
1. Using DataFrame.iterrows() to Iterate Over Rows
pandas DataFrame.iterrows() is used to iterate over DataFrame rows. This returns (index, Series) where the index is an index of the Row and Series is data or content of each row. To get the data from the series, you should use the column name like row[«Fee»] . To learn more about the Series access How to use Series with Examples.
First, let’s create a DataFrame.
import pandas as pd technologies = (< 'Courses':["Spark","PySpark","Hadoop","Python","pandas","Oracle","Java"], 'Fee' :[20000,25000,26000,22000,24000,21000,22000], 'Duration':['30day', '40days' ,'35days', '40days', '60days', '50days', '55days'] >) df = pd.DataFrame(technologies) print(df) Yields below result. As you see the DataFrame has 3 columns Courses , Fee and Duration .
# Output: Courses Fee Duration 0 Spark 20000 30day 1 PySpark 25000 40days 2 Hadoop 26000 35days 3 Python 22000 40days` 4 pandas 24000 60days 5 Oracle 21000 50days 6 Java 22000 55days The below example Iterates all rows in a DataFrame using iterrows() .
# Iterate all rows using DataFrame.iterrows() for index, row in df.iterrows(): print (index,row["Fee"], row["Courses"]) # Output: 0 20000 Spark 1 25000 PySpark 2 26000 Hadoop 3 22000 Python 4 24000 Pandas 5 21000 Oracle 6 22000 Java Let’s see what a row looks like by printing it.
# Row contains the column name and data row = next(df.iterrows())[1] print("Data For First Row :") print(row) # Output: Data For First Row : Courses Spark Fee 20000 Duration 30day Name: 0, dtype: object Note that Series returned from iterrows() doesn’t contain the datatype ( dtype ), in order to access the data type you should use row[«Fee»].dttype . If you want data type for each row you should use DataFrame.itertuples() .
Note: Pandas document states that “You should never modify something you are iterating over. This is not guaranteed to work in all cases. Depending on the data types, the iterator returns a copy and not a view, and writing to it will have no effect.”
2. Using DataFrame.itertuples() to Iterate Over Rows
Pandas DataFrame.itertuples() is the most used method to iterate over rows as it returns all DataFrame elements as an iterator that contains a tuple for each row. itertuples() is faster compared with iterrows() and preserves data type.
Below is the syntax of the itertuples() .
# Syntax DataFrame.itertuples() DataFrame.itertuples(index=True, name='Pandas') - index – Defaults to ‘True’. Returns the DataFrame Index as a first element in a tuple. Setting it to False, doens’t return Index.
- name – Defaults to ‘Pandas’. You can provide a custom name to your returned tuple.
The below example loop through all elements in a tuple and get the value of each column by using getattr() .
# Iterate all rows using DataFrame.itertuples() for row in df.itertuples(index = True): print (getattr(row,'Index'),getattr(row, "Fee"), getattr(row, "Courses")) # Output: 0 20000 Spark 1 25000 PySpark 2 26000 Hadoop 3 22000 Python 4 24000 Pandas 5 21000 Oracle 6 22000 Java Let’s provide the custom name to the tuple.
# Display one row from iterator row = next(df.itertuples(index = True,name='Tution')) print(row) # Output: Tution(Index=0, Courses='Spark', Fee=20000, Duration='30day') If you set the index parameter to False , it removes the index as the first element of the tuple.
4. DataFrame.apply() to Iterate
You can also use apply() method of the DataFrame to loop through the rows by using the lambda function. For more details, refer to DataFrame.apply().
# Syntax of DataFrame.apply() DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs) # Another alternate approach by using DataFrame.apply() print(df.apply(lambda row: str(row["Fee"]) + " " + str(row["Courses"]), axis = 1)) # Output: 0 20000 Spark 1 25000 PySpark 2 26000 Hadoop 3 22000 Python 4 24000 Pandas 5 21000 Oracle 6 22000 Java dtype: object 5. Iterating using for & DataFrame.index
You can also loop through rows by using for loop. df[‘Fee’][0] returns the first-row value from column Fee .
# Using DataFrame.index for idx in df.index: print(df['Fee'][idx], df['Courses'][idx]) # Output: 20000 Spark 25000 PySpark 26000 Hadoop 22000 Python 24000 Pandas 21000 Oracle 22000 Java 6. Using for & DataFrame.loc
# Another alternate approach byusing DataFrame.loc() for i in range(len(df)) : print(df.loc[i, "Fee"], df.loc[i, "Courses"]) Yields same output as above.
7. Using For & DataFrame.iloc
# Another alternate approach by using DataFrame.iloc() for i in range(len(df)) : print(df.iloc[i, 0], df.iloc[i, 2]) # Output: Spark 30day PySpark 40days Hadoop 35days Python 40days Pandas 60days Oracle 50days Java 55days 8. Using DataFrame.items() to Iterate Over Columns
DataFrame.items() are used to iterate over columns (column by column) of pandas DataFrame. This returns a tuple (column name, Series) with the name and the content as Series.
The first value in the returned tuple contains the column label name and the second contains the content/data of DataFrame as a series.
# Iterate over column by column using DataFrame.items() for label, content in df.items(): print(f'label: ') print(f'content: ', sep='\n') # Output: label: Courses content: 0 Spark 1 PySpark 2 Hadoop 3 Python 4 Pandas 5 Oracle 6 Java Name: Courses, dtype: object label: Fee content: 0 20000 1 25000 2 26000 3 22000 4 24000 5 21000 6 22000 Name: Fee, dtype: int64 label: Duration content: 0 30day 1 40days 2 35days 3 40days 4 60days 5 50days 6 55days Name: Duration, dtype: object 9. Performance of Iterating DataFrame
Iterating a DataFrame is not advised or recommended to use as the performance would be very bad when iterating over the large dataset. Make sure you use this only when you exhausted all other options. Before using examples mentioned in this article, check if you can use any of these 1) Vectorization, 2) Cython routines, 3) List Comprehensions (vanilla for loop).
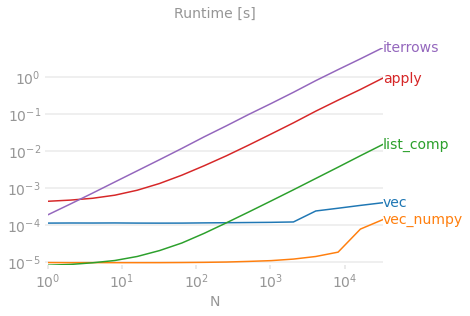
10. Complete Example of pandas Iterate over Rows
import pandas as pd Technologys = (< 'Courses':["Spark","PySpark","Hadoop","Python","Pandas","Oracle","Java"], 'Fee' :[20000,25000,26000,22000,24000,21000,22000], 'Duration':['30day', '40days' ,'35days', '40days', '60days', '50days', '55days'] >) df = pd.DataFrame(Technologys) print(df) # Using DataFrame.iterrows() row = next(df.iterrows())[1] print("Data For First Row :") print(row) for index, row in df.iterrows(): print (index,row["Fee"], row["Courses"]) # Using DataFrame.itertuples() row = next(df.itertuples(index = True, name='Tution')) print("Data For First Row :") print(row) for row in df.itertuples(index = True): print (getattr(row,'Index'),getattr(row, "Fee"), getattr(row, "Courses")) # Another alternate approach by using DataFrame.apply print(df.apply(lambda row: str(row["Fee"]) + " " + str(row["Courses"]), axis = 1)) # Using DataFrame.index for idx in df.index: print(df['Fee'][idx], df['Courses'][idx]) # Another alternate approach by using DataFrame.loc for i in range(len(df)) : print(df.loc[i, "Fee"], df.loc[i, "Courses"]) # Another alternate approach by using DataFrame.iloc for i in range(len(df)) : print(df.iloc[i, 0], df.iloc[i, 2]) # Using DataFrame.items for label, content in df.items(): print(f'label: ') print(f'content: ', sep='\n') Conclusion
DataFrame provides several methods to iterate over rows (loop over row by row) and access columns/cells. But it is not recommended to manually loop over the rows as it degrades the performance of the application when used on large datasets. Each example explained in this article behaves differently so depending on your use-case use the one that suits your need.
Related Articles
References
You may also like reading:
pandas.DataFrame.iterrows#
Iterate over DataFrame rows as (index, Series) pairs.
Yields index label or tuple of label
The index of the row. A tuple for a MultiIndex .
data Series
The data of the row as a Series.
Iterate over DataFrame rows as namedtuples of the values.
Iterate over (column name, Series) pairs.
- Because iterrows returns a Series for each row, it does not preserve dtypes across the rows (dtypes are preserved across columns for DataFrames). For example,
>>> df = pd.DataFrame([[1, 1.5]], columns=['int', 'float']) >>> row = next(df.iterrows())[1] >>> row int 1.0 float 1.5 Name: 0, dtype: float64 >>> print(row['int'].dtype) float64 >>> print(df['int'].dtype) int64
How to Iterate Over Rows with Pandas – Loop Through a Dataframe

Shittu Olumide

This article provides a comprehensive guide on how to loop through a Pandas DataFrame in Python.
I’ll start by introducing the Pandas library and DataFrame data structure. I’ll explain the essential characteristics of Pandas, how to loop through rows in a dataframe, and finally how to loop through columns in a dataframe.
What is Pandas?
Pandas is a popular open-source Python library that’s used for data cleaning, analysis, and manipulation. In addition to functions for carrying out operations on those datasets, it offers data structures for effectively storing and handling large and complex datasets.
Some of the essential characteristics of Pandas are:
- DataFrame and Series Objects: Pandas provides two primary data structures, DataFrames and Series. They allow users to store and manipulate tabular data and time series data, respectively. These data structures are highly efficient and can handle large datasets with ease.
- Data Cleaning and Preparation: Pandas provides a wide range of functions and methods for cleaning and preparing data, including handling missing values, removing duplicates, and transforming data.
- Data Analysis and Visualization: Pandas provides powerful functions for performing data analysis, including statistical functions and grouping and aggregation functions. It also integrates well with other data analysis and visualization libraries in Python, such as Matplotlib and Seaborn.
- Data Input and Output: Pandas provides functions for reading and writing data in a variety of formats, including CSV, Excel, SQL databases, and more.
What is a Pandas Dataframe?
In Pandas, a dataframe is a two-dimensional labeled data structure. It is comparable to a spreadsheet or a SQL table, where data is arranged in rows and columns with a variety of data types in each column.
Since dataframes offer an easy way to store, manipulate, and analyze data, they are frequently used in data science and data analysis applications. Dataframes provide a number of features, including pivoting, grouping, indexing, and filtering, that make it simple to carry out complex operations on data.
How to Loop Through Rows in a Dataframe
You can loop through rows in a dataframe using the iterrows() method in Pandas. This method allows us to iterate over each row in a dataframe and access its values.
import pandas as pd # create a dataframe data = df = pd.DataFrame(data) # loop through the rows using iterrows() for index, row in df.iterrows(): print(row['name'], row['age']) In this example, we first create a dataframe with two columns, name and age . We then loop through each row in the dataframe using iterrows() , which returns a tuple containing the index of the row and a Series object that contains the values for that row.
Within the loop, we can access the values for each column by using the column name as an index on the row object. For example, to access the value for the name column, we use row[‘name’] .
How to Loop Through Columns in a Dataframe
Looping through columns in a dataframe is a common task in data analysis and manipulation. It’s different from the way we loop through rows, though.
import pandas as pd # Create a sample dataframe df = pd.DataFrame(< 'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9] >) # Loop through columns using a for loop for col in df.columns: print(col) First, we import the Pandas library using the import pandas as pd statement.
Then, we create a sample dataframe using the pd.DataFrame() function, which takes a dictionary of column names and values as an input.
Next, we loop through the columns of the dataframe using a for loop and the df.columns attribute, which returns a list of column names.
Inside the loop, we simply print the name of each column using the print() function.
Use Cases for Looping Through a Dataframe
Looping through a dataframe is an important technique in data analysis and manipulation, as it allows us to perform operations on each row or column of the dataframe.
You’ll loop through dataframes in the following activities:
- Data Cleaning and Transformation.
- Data Analysis.
- Data Visualization.
- Feature Engineering.
Conclusion
By looping through the rows in a dataframe, we can perform operations on each row, such as filtering or transforming the data.
But it’s important to note that looping through rows in a dataframe can be slow and inefficient for large datasets. In general, it’s often better to use vectorized operations or apply() functions to perform operations on dataframes, as these methods are optimized for performance.
Let’s connect on Twitter and on LinkedIn. You can also subscribe to my YouTube channel.