Как добавить колонку к pd.DataFrame
В Pandas существует по меньшей мере три официальных способа добавить колонку, не включая экзотических:
import pandas as pd df = pd.DataFrame(. ) df['column'] = value У этого способа самый простой и очевидный синтаксис, поэтому по умолчанию обычно используют именно его. Но наверняка каждый, кто работал с Pandas, получал хотя бы раз в жизни такой неприятный warning при добавлении колонки:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead Этот warning говорит нам, что существует второй способ.
Откуда же берется warning в первом способе? Он возникает, когда выполняется несколько выборок идущих друг за другом, причем на вход следующей выборки подаются результаты предыдущей выборки. В терминологии Pandas это называется chained indexing и выглядит например так:
# Выборка по строкам, потом по колонкам df[df['a'] > 5][['b', 'c']] # Выборка по колонкам, потом по строкам df[['b', 'c']][df['a'] > 5] Если попытаться модифицировать результаты chained indexing (добавление колонки это тоже модификация), то Pandas не поймет, что мы хотим — добавить колонку в результаты выборки, или добавить колонку в исходный фрейм? Оба примера, приведенные ниже, эквивалентны с точки зрения Pandas:
# Добавить колонку 'b' к исходному фрейму? df[df['a'] > 5]['b'] = 42 # Или к результатам выборки? df1 = df[df['a'] > 5] df1['b'] = 42 Чтобы выдать SettingWithCopyWarning , Pandas запоминает источник данных для каждого фрейма, ‘родительский’ фрейм. Если такой источник существует, т.е. фрейм является подмножеством данных родительского фрейма, то в момент модификации выдается warning.
Второй способ позволяет нам более явным образом сообщить о своих намерениях, т.к. даёт совместить выборку и присваивание в одном выражении.
Более подробно о премудростях chained indexing можно прочитать в документации Pandas или в отличной статье на Medium.
result = df.assign(column=value) Третий способ не модифицирует исходный фрейм, что в зависимости от ситуации может быть как плюсом (например при повторном выполнении ячейки в Ipython Notebook), так и минусом, загромождая код присваиваниями. Кроме того, при выполнении assign() всегда происходит создание нового фрейма, что теоретически должно быть немного медленнее, чем предыдущие in-place способы.
Наличие нескольких способов сделать одну и ту же простую задачу противоречит известному принципу Zen of Python :
There should be one—and preferably only one—obvious way to do it.
И как оказалось, проблема здесь не только в нарушении философского принципа.
Проблема

Я давно замечал, что при активном добавлении колонок во фреймы код начинает работать подозрительно медленно. Под активным я имею в виду сотни и тысячи добавлений — такие задачи встречаются, когда данные надо разбить на много мелких групп и работать с каждой отдельно. Использование третьего способа, через assign() обычно ускоряло такой код, хотя теоретически он должен работать медленнее двух первых — я списывал это на то, что мне просто показалось, и никогда не делал точных замеров.
Но на последней задаче эта проблема проявилась особенно остро. Скрипт, который должен был пропустить через себя примерно 100Gb данных, и довольно бодро стартовавший с прогнозом времени выполнения 3 часа, был оставлен на ночь. К утру скрипт не выполнил и 20% работы и почти завис, потребляя при этом 100% CPU. В чём же дело?
Запуск скрипта под cProfile выявил занятную картину: основную часть времени процесс находится внутри метода gc.collect() , при том, что я нигде не вызываю сборщик мусора. Такое поведение было бы объяснимым для виртуальной машины Java, работающей в условиях нехватки памяти, тогда бы сборщик мусора активировался на каждый чих. Но Python?
Пришлось поглубже залезть в трассировку вызовов… и следы привели к коду, добавляющему колонки в dataframe! Вот фрагмент кода метода DataFrame._check_setitem_copy() , занимающегося проверкой при добавлении колонки, и выдающего тот самый SettingWithCopyWarning , о котором говорилось выше :
if force or self._is_copy: value = config.get_option('mode.chained_assignment') if value is None: return # see if the copy is not actually referred; if so, then dissolve # the copy weakref try: gc.collect(2) if not gc.get_referents(self._is_copy()): self._is_copy = None return except Exception: pass В поле self._is_copy хранится weak reference на объект, являющийся ‘родителем’ текущего фрейма. Чтобы проверить, жив ли еще родитель, авторы Pandas не нашли лучшего способа, чем просто запустить сборку мусора во всей виртуальной машине 😟
На тестах, когда в памяти не очень много объектов, сборка мусора отрабатывает практически мгновенно и код не вызывает никаких нареканий. В моём же случае в памяти было закешировано около 10Gb данных, и сборщику мусора приходилось изрядно потрудиться, обходя все эти объекты при каждом добавлении колонки во фрейм.
Решение
Решение было простым — раз блок кода со сборкой мусора исполняется только при наличии ‘родителя’, надо сделать так, чтобы родителя не было. Я просто добавил вызов copy() перед тем местом, где добавляется колонка. После copy() фрейм считается ‘заново рождённым’, и не содержит ссылок на источник данных:
df = df.copy() df['column'] = value Скрипт сразу заработал намного быстрее, и завершился всего за час 🎉
Отмечу, что тормоза были одинаковыми при использовании и первого и второго способа добавления колонки, что неудивительно, т.к. оба они вызывают эту проверку. А что же третий способ, assign() ? Посмотрим на его код, он очень простой (привожу только ветку для Python 3.6):
def assign(self, **kwargs): data = self.copy() for k, v in kwargs.items(): data[k] = com._apply_if_callable(v, data) return data Как видно, этот код делает ровно то, что я сделал вручную, ускоряя свой скрипт: сначала копирует фрейм, а потом добавляет в него колонки дедовским способом. Именно поэтому использование assign() , вопреки логике, всегда ускоряло работу.
Выводы
Для пользователей Pandas вывод простой: надёжнее всего использовать assign() , и со стороны performance, и со стороны того, что он ограждает пользователя от side effects, связанных с необратимым изменением фрейма. Автор статьи, которую я рекомендовал выше, приходит к тем же выводам. Всегда, когда надо присвоить что-то фрейму, перед присваиванием лучше вызвать df.copy() , чтобы избежать неоднозначностей. И, как показывает мой пример, еще и получить прибавку к скорости!
А разработчикам Pandas хорошо бы или найти способ отказаться от такой brute-force проверки, или хотя бы отразить её наличие в документации.
pandas.DataFrame.insert#
Raises a ValueError if column is already contained in the DataFrame, unless allow_duplicates is set to True.
Parameters loc int
Insertion index. Must verify 0
column str, number, or hashable object
Label of the inserted column.
value Scalar, Series, or array-like allow_duplicates bool, optional, default lib.no_default
>>> df = pd.DataFrame('col1': [1, 2], 'col2': [3, 4]>) >>> df col1 col2 0 1 3 1 2 4 >>> df.insert(1, "newcol", [99, 99]) >>> df col1 newcol col2 0 1 99 3 1 2 99 4 >>> df.insert(0, "col1", [100, 100], allow_duplicates=True) >>> df col1 col1 newcol col2 0 100 1 99 3 1 100 2 99 4
Notice that pandas uses index alignment in case of value from type Series :
>>> df.insert(0, "col0", pd.Series([5, 6], index=[1, 2])) >>> df col0 col1 col1 newcol col2 0 NaN 100 1 99 3 1 5.0 100 2 99 4
4 способа добавления колонок в датафреймы Pandas

Pandas — это библиотека для анализа и обработки данных, написанная на языке Python. Она предоставляет множество функций и способов для управления табличными данными. Основная структура данных Pandas — это датафрейм, который хранит информацию в табличной форме с помеченными строками и столбцами.
В контексте данных строки представляют собой утверждения, или точки данных. Столбцы отражают свойства, или атрибуты утверждений. Рассмотрим эту структуру на простом примере. Допустим, каждая строка — это дом. В таком случае, столбцы заключают в себе сведения об этом доме (его возрасте, количестве комнат, стоимости и т.д.).
Добавление или удаление столбцов — обычная операция при анализе данных. Ниже мы разберем 4 различных способа добавления новых столбцов в датафрейм Pandas.
Сначала создадим простой фрейм данных для использования в примерах:
import numpy as np import pandas as pd df = pd.DataFrame() df
Способ 1-й
Пожалуй, это самый распространенный путь создания нового столбца в Pandas:

Мы указываем имя столбца подобно тому, как выбираем столбец во фрейме данных. Затем этому столбцу присваиваются значения. Новый столбец добавляется последним (т. е. становится столбцом с самым высоким индексом).
Можно добавить сразу несколько столбцов. Их наименования перечисляются списком, а значения должны быть двумерными для совместимости с количеством строк и столбцов. Например, следующий код добавляет три столбца, заполненные случайными целыми числами от 0 до 10:
df[["1of3", "2of3", "3of3"]] = np.random.randint(10, size=(4,3)) df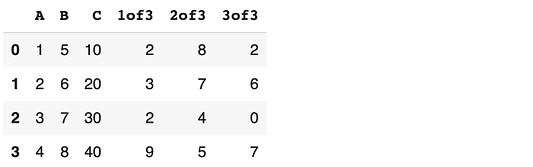
Давайте удалим эти три столбца, прежде чем перейти к следующему методу.
df.drop(["1of3", "2of3", "3of3"], axis=1, inplace=True)
Способ 2-й
В первом способе мы добавляли новый столбец в конец. Pandas также позволяет добавлять столбцы по определенному индексу. Для настройки расположения нового столба воспользуемся функцией вставки (insert function). Давайте добавим один столбец рядом с А:

Для использования функции вставки необходимо 3 параметра: индекс, имя столбца и значение. Индексы столбцов начинаются с 0, поэтому мы устанавливаем параметр индекса 1, чтобы добавить новый столбец рядом со столбцом A. Мы можем указать постоянное значение, которое будет выставлено во всех строках.
Способ 3-й
Функция loc позволяет выбирать строки и столбцы, используя их метки. Таким же образом можно создать новый столбец:

Для выбора строк и столбцов мы указываем нужные метки. Если хотим выбрать все строки, ставим двоеточие. В части таблицы, где нужно проставить столбец, указываем метки столбцов, которые нам необходимо выбрать. Поскольку в датафрейме нет столбца E, Pandas создаст новый столбец.
Способ 4-й
Добавить столбцы можно также с помощью функции assign :
df = df.assign(F = df.C * 10) df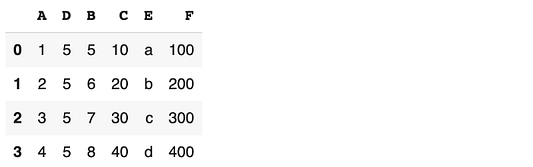
В функции assign необходимо прописать имя столбца и значения. Обратите внимание: мы получаем значения, используя другой столбец во фрейме данных. Предыдущие способы также допускают такую операцию.
Надо понимать, что между функциями assign и insert есть существенное различие.
Функция вставки ( insert ) работает на месте. Это означает, что изменение (добавление нового столбца) сохраняется во фрейме данных.
С функцией назначения ситуация немного иная. Он возвращает измененный фрейм данных, но не изменяет исходный. Чтобы использовать измененную версию (с новым столбцом), нам нужно явно назначить ее.
Заключение
Мы рассмотрели 4 различных способа добавления новых столбцов в фрейм данных Pandas. Это обычная операция при анализе и обработке данных.
Мне нравится пользоваться библиотекой Pandas, поскольку она предоставляет, как правило, несколько способов для выполнения одной задачи. По-моему, это говорит о гибкости и универсальности Pandas.
pandas.DataFrame.assign#
Returns a new object with all original columns in addition to new ones. Existing columns that are re-assigned will be overwritten.
Parameters **kwargs dict of
The column names are keywords. If the values are callable, they are computed on the DataFrame and assigned to the new columns. The callable must not change input DataFrame (though pandas doesn’t check it). If the values are not callable, (e.g. a Series, scalar, or array), they are simply assigned.
A new DataFrame with the new columns in addition to all the existing columns.
Assigning multiple columns within the same assign is possible. Later items in ‘**kwargs’ may refer to newly created or modified columns in ‘df’; items are computed and assigned into ‘df’ in order.
>>> df = pd.DataFrame('temp_c': [17.0, 25.0]>, . index=['Portland', 'Berkeley']) >>> df temp_c Portland 17.0 Berkeley 25.0
Where the value is a callable, evaluated on df :
>>> df.assign(temp_f=lambda x: x.temp_c * 9 / 5 + 32) temp_c temp_f Portland 17.0 62.6 Berkeley 25.0 77.0
Alternatively, the same behavior can be achieved by directly referencing an existing Series or sequence:
>>> df.assign(temp_f=df['temp_c'] * 9 / 5 + 32) temp_c temp_f Portland 17.0 62.6 Berkeley 25.0 77.0
You can create multiple columns within the same assign where one of the columns depends on another one defined within the same assign:
>>> df.assign(temp_f=lambda x: x['temp_c'] * 9 / 5 + 32, . temp_k=lambda x: (x['temp_f'] + 459.67) * 5 / 9) temp_c temp_f temp_k Portland 17.0 62.6 290.15 Berkeley 25.0 77.0 298.15