- Чтение и запись файлов Excel (XLSX) в Python
- Установка Pandas
- Запись в файл Excel с python
- Запись нескольких DataFrame в файл Excel
- Чтение файлов Excel с python
- Как читать excel-файлы (xlsx) при помощи Python
- Для начала
- sales.xlsx
- Чтение Excel-файла с помощью xlrd
- Чтение Excel-файла с помощью openpyxl
- Чтение Excel-файла с помощью pandas
- Заключение
Чтение и запись файлов Excel (XLSX) в Python
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip .
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Запись в файл Excel с python
Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame . А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas . Потом используем словарь для заполнения DataFrame :
import pandas as pd
df = pd.DataFrame( 'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]>)Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
А вот и созданный файл Excel:
Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
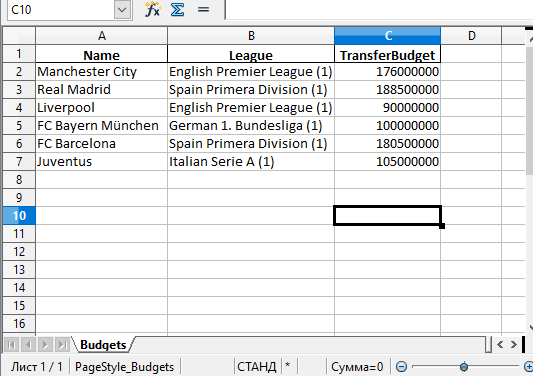
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel() :
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)Также можно добавили параметр index со значением False , чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame( 'Salary': [560000, 220000, 125000]>)
salaries2 = pd.DataFrame( 'Salary': [370000, 270000, 240000]>)
salaries3 = pd.DataFrame( 'Salary': [160000, 260000, 250000]>)
salary_sheets =
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets , где каждый ключ будет названием листа, а значение — объектом DataFrame .
Дальше используем движок xlsxwriter для создания объекта writer . Он и передается функции to_excel() .
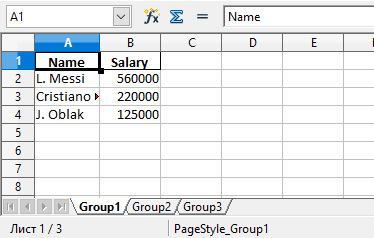
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter , который нужен для работы с классом ExcelWriter . Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save() , которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame . Для этого достаточно воспользоваться функцией read_excel() :
Как читать excel-файлы (xlsx) при помощи Python
.xlsx – это расширение документа Excel, который может хранить большой объем данных в табличной форме. Более того, в электронной таблице Excel можно легко выполнять многие виды арифметических и логических вычислений.
Иногда программистам требуется прочитать данные из документа Excel. В Python для этого есть множество различных библиотек, например, xlrd , openpyxl и pandas . Сегодня мы поговорим о том, как читать excel-файлы (xlsx) при помощи Python, и рассмотрим примеры использования различных библиотек для этих целей.
Для начала
Для проверки примеров этого руководства потребуется какой-нибудь файл Excel с расширением .xlsx , содержащий какие-либо исходные данные. Вы можете использовать любой существующий файл Excel или создать новый. Мы создадим новый файл с именем sales.xlsx со следующими данными:
sales.xlsx

| Sales Date | Sales Person | Amount |
|---|---|---|
| 12/05/18 | Sila Ahmed | 60000 |
| 06/12/19 | Mir Hossain | 50000 |
| 09/08/20 | Sarmin Jahan | 45000 |
| 07/04/21 | Mahmudul Hasan | 30000 |
Этот файл мы и будем читать с помощью различных библиотек Python в следующей части этого руководства.
Чтение Excel-файла с помощью xlrd
Библиотека xlrd не устанавливается вместе с Python по умолчанию, так что ее придется установить. Последняя версия этой библиотеки, к сожалению, не поддерживает Excel-файлы с расширением .xlsx . Поэтому устанавливаем версию 1.2.0. Выполните следующую команду в терминале:
После завершения процесса установки создайте Python-файл, в котором мы будем писать скрипт для чтения файла sales.xlsx с помощью модуля xlrd.
Воспользуемся функцией open_workbook() для открытия файла xlsx для чтения. Этот файл Excel содержит только одну таблицу. Поэтому функция workbook.sheet_by_index() используется в скрипте со значением аргумента 0.
Затем используем вложенный цикл for . С его помощью мы будем перемещаться по ячейкам, перебирая строки и столбцы. Также в скрипте используются две функции range() для определения количества строк и столбцов в таблице.
Для чтения значения отдельной ячейки таблицы на каждой итерации цикла воспользуемся функцией cell_value() . Каждое поле в выводе будет разделено одним пробелом табуляции.
import xlrd # Open the Workbook workbook = xlrd.open_workbook("sales.xlsx") # Open the worksheet worksheet = workbook.sheet_by_index(0) # Iterate the rows and columns for i in range(0, 5): for j in range(0, 3): # Print the cell values with tab space print(worksheet.cell_value(i, j), end='\t') print('') Запустим наш код и получим следующий результат.

Чтение Excel-файла с помощью openpyxl
Openpyxl – это еще одна библиотека Python для чтения файла .xlsx , и она также не идет по умолчанию вместе со стандартным пакетом Python. Чтобы установить этот модуль, выполните в терминале следующую команду:
После завершения процесса установки можно начинать писать код для чтения файла sales.xlsx.
Как и модуль xlrd, модуль openpyxl имеет функцию load_workbook() для открытия excel-файла для чтения. В качестве значения аргумента этой функции используется файл sales.xlsx.
Объект wookbook.active служит для чтения значений свойств max_row и max_column . Эти свойства используются во вложенных циклах for для чтения содержимого файла sales.xlsx.
Функцию range() используем для чтения строк таблицы, а функцию iter_cols() — для чтения столбцов. Каждое поле в выводе будет разделено двумя пробелами табуляции.
import openpyxl # Define variable to load the wookbook wookbook = openpyxl.load_workbook("sales.xlsx") # Define variable to read the active sheet: worksheet = wookbook.active # Iterate the loop to read the cell values for i in range(0, worksheet.max_row): for col in worksheet.iter_cols(1, worksheet.max_column): print(col[i].value, end="\t\t") print('') Запустив наш скрипт, получим следующий вывод.

Чтение Excel-файла с помощью pandas
Если вы не пользовались библиотекой pandas ранее, вам необходимо ее установить. Как и остальные рассматриваемые библиотеки, она не поставляется вместе с Python. Выполните следующую команду, чтобы установить pandas из терминала.
После завершения процесса установки создаем файл Python и начинаем писать следующий скрипт для чтения файла sales.xlsx.
В библиотеке pandas есть функция read_excel() , которую можно использовать для чтения .xlsx -файлов. Ею мы и воспользуемся в нашем скрипте для чтения файла sales.xlsx.
Функция DataFrame() используется для чтения содержимого нашего файла и преобразования имеющейся там информации во фрейм данных. После мы сохраняем наш фрейм в переменной с именем data . А дальше выводим то, что лежит в data , в консоль.
import pandas as pd # Load the xlsx file excel_data = pd.read_excel('sales.xlsx') # Read the values of the file in the dataframe data = pd.DataFrame(excel_data, columns=['Sales Date', 'Sales Person', 'Amount']) # Print the content print("The content of the file is:\n", data) После запуска кода мы получим следующий вывод.

Результат работы этого скрипта отличается от двух предыдущих примеров. В первом столбце печатаются номера строк, начиная с нуля. Значения даты выравниваются по центру. Имена продавцов выровнены по правому краю, а сумма — по левому.
Заключение
Программистам довольно часто приходится работать с файлами .xlsx . Сегодня мы рассмотрели, как читать excel-файлы при помощи Python. Мы разобрали три различных способа с использованием трех библиотек. Все эти библиотеки имеют разные функции и свойства.
Надеемся, теперь у вас не возникнет сложностей с чтением этих файлов в ваших скриптах.