- What is a Python File Header?
- What is File Header?
- What is Python File Header?
- How to write Python File Header?
- Format for writing Python File Header
- Shebang
- Docstring with description description
- Importing Modules
- Encoding
- Authorship Info
- FAQs
- Difference between a file header and a header file?
- Conclusion
- References
- Downloading Files In Python Using Requests Module
- Introduction
- Not all URLs pointing to downloadable resources
- Define a function to verify a downloadable resource
- Checking Content-Type of the request header
- Restricting the file size of the downloading resource
- Getting the file name from the URL
- Leave a Reply Cancel reply
What is a Python File Header?


Similar to file headers in other languages the python file header also includes information relevant to the file. Every language or document has its name and a few details written at the top of it. This basically includes its name, author, and some relevant information.
The python file header is easy to create, but if you are someone new who is working with python and not familiar with file headers then you may require a little help. This guide here will help you with understanding and create a file header with the help of a common format.
What is File Header?
In general, a file header is defined as a block present at the top of the file that all the information related to the file. This will include the filename, author, and maybe date and some other information related to it. This is a common part present in all the files.
It is often used to verify the data types of the file. This is written along with the file extension of the applications on which it was written. It can also help to locate deleted files and user activity logs.
What is Python File Header?
Similar to the general File header the python file header has a filename, author name, date, and other details relevant to the file. This is used by in-built modules and third-party imports. Although the content of the file header may remain similar the format may not be. As the format differs from programmer to programmer. Unlike the regular file header, file header creation in programming languages like python requires coding
How to write Python File Header?
As mentioned above the file header in python require coding. So, while working the format of the file header may vary from programmer to programmer as it does not necessarily follow a particular path. Despite varying formats for making file headers, there is a common format that can help you without a fail.
Format for writing Python File Header
A file header in python generally has a shebang and a docstring with a description which basically includes syntax, and, encoding. The basic requirement for writing a good file header is to have an appropriate interpreter-friendly shebang and a module description that should be informative with regard to the script.
Shebang
It is basically a character sequence with a character number sign starting with a hash and an exclamation mark (#!) at the beginning.

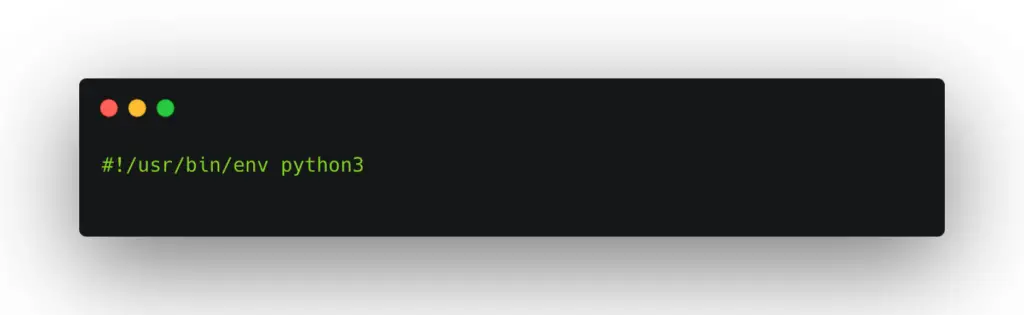
The shebang ends with the python along with the version it’s using. For example, if you are using python version 3 then it will be written as
Docstring with description description
This part basically includes the description of the file. The first line of the docstring description should be a short summary of the entire file as it should be interpreter friendly. The line can also include ‘#!interpreter’ which is an optional argument that is basically a string argument representing a single argument.
The docstring should be followed by all the codes or else the interpreter will not recognize the docstring. This may result in the denying of access to interactive sessions or generating documentation with automated tools.
Importing Modules
After adding the docstring with descriptions, the next step is to import built-in modules. Then you can move to import the third-party modules which are followed by making changes to the path and own modules. Sometimes changing the path and modules makes it difficult to locate so you may keep them in one place to make it easier to find.
The imports of built-in modules use the code ‘os’ module, ‘sys’ module, ‘math’ module, etc.
Encoding
After writing the syntax for docstring the next step is encoding. This step is used to convert data from one form to another. This line uses the utf-8. The number placed after the utf denotes the values of the bits. in python 3 the default value is 8.
Authorship Info
The next step is to add the authorship. In this part, you can mention the author, copyrighted to, and credits. You can also add the maintainer, which can edit to improve the file when it’s imported. You can also put status, which will show the status of the file. It can be “prototype”, “development”, or “production” based on the stage.
Apart from these, you can also add date, version, license, email, etc.
FAQs
Difference between a file header and a header file?
A file header is defined as a block present at the top of the file that all the information related to the file whereas the header file is a file with an extension that contains function declarations and macro definitions that can be shared between several files. It is related to the C language.
Conclusion
This guide will help you find the right way to create a header for your file using the common format discussed above.
References
To learn more about resolving regular python issues follow pythonclear.
Downloading Files In Python Using Requests Module

This post aims to present you how to download a resource from the given URL using the requests module. Of course, there are other modules which allow you to accomplish this purpose but I just focus on explaining how to do with the requests module and leave you discovering the other methods. Let’s get started now.
Introduction
Below is a simple snippet to download Google’s logo in the Google search page via the link https://www.google.co.uk/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png
import requests url = "https://www.google.co.uk/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png" r = requests.get(url, allow_redirects=True) open("google.ico", "wb").write(r.content) The file named google.ico is saved into the current working directory. It’s easy as a piece of cake, right? In practice, we have to face more difficult situations that I am gonna show you now.
Not all URLs pointing to downloadable resources
The real world is you almost certainly handle circumstances where the resources in downloading are protected not allow users to download. For example, Youtube videos have been secured to prevent users from greedily downloading. People developers browser extensions or standalone applications to download Youtube videos, however, Google has detected such violent activities and increasingly protected their data. Therefore, it is important to check whether the resource of interest is allowed to download or not before sending a request. A snippet below simulates how to check that based on the Content-Type parameter of the header of the requesting URL.
import requests def extract_content_type(_url): r = requests.get(_url, allow_redirects=True) return r.headers.get("Content-Type") url = "https://www.google.co.uk/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png" # open("google.ico", "wb").write(r.content) print(extract_content_type(url)) url = "https://www.youtube.com/watch?v=ylk5AYyOcGI" print(extract_content_type(url)) The output of the script above looks like
image/png text/html; charset=utf-8
The extract_content_type function returns a string as the mime type of the remote file. In the above example, what we are expecting from the Youtube URL is a video type rather than text/html while the first URL returns an expected value. In other words, the content type of a request is text/html which we just download a plain text or HTML document instead of well-known mime types such as image/png, video/mp4, etc.
Define a function to verify a downloadable resource
As explained in the previous section, checking a resource allowed to download is necessary before sending a request.
Checking Content-Type of the request header
The function below can do what we need by checking the content type from the header.
def is_downloadable(_url): """ Does the url contain a downloadable resource """ h = requests.head(_url, allow_redirects=True) header = h.headers content_type = header.get('content-type') if 'text' in content_type.lower(): return False if 'html' in content_type.lower(): return False return True Applying this function for the two URLs in the previous examples, it returns False for Youtube URL while True is returned with Google’s icon link.
Restricting the file size of the downloading resource
We might have another restriction on the downloading resource, for example, just downloading the file which the size is not greater than 100 MB. By inspecting the header of the request URL on the content-length property, the code below can work as expected.
content_length = header.get('content-length', None) if content_length and content_length > 1e8: # 100 MB approx return False Getting the file name from the URL
Again, to obtain the file name of the downloading resource, we can use the Content-Disposition property of the request header.
def get_filename_from_url(_url): """ Get filename from content-disposition """ r = requests.get(_url, allow_redirects=True) cd = r.headers.get('content-disposition') if not cd: return None filename = re.findall('filename=(.+)', cd) if len(filename) == 0: return None return filename[0] The URL-parsing code in conjunction with the above method to get filename from the Content-Disposition header will work for most of the cases.
Voilà! If you have any judgments, please don’t hesitate to leave your comments in the comment box below.
Leave a Reply Cancel reply
This site uses Akismet to reduce spam. Learn how your comment data is processed.