- python, UnicodeEncodeError, converting unicode to ascii
- 2 Answers 2
- Ошибки при конвертации#
- Обработка ошибок#
- Параметр errors в encode#
- Параметр errors в decode#
- Python encode error ascii
- # UnicodeEncodeError: ‘ascii’ codec can’t encode character in position
- # Use the correct encoding to encode the string
- # Set the errors keyword argument to ignore
- # Try using the ascii encoding to encode the string
- # Set the encoding keyword argument to utf-8 when opening a file
- # Setting the encoding globally with an environment variable
- # Set the encoding keyword argument to utf-8 when sending emails
- # Setting the LANG and LC_ALL environment variables incorrectly
python, UnicodeEncodeError, converting unicode to ascii
Now the problem is, that SQL query returns me unicode strings. The output from select is something like this:
So first I was trying to convert it string, but it fails as the third element contains this german ‘ae’ letter:
for x in data[0]: str_data.append(str(x)) I am getting: UnicodeEncodeError: ‘ascii’ codec can’t encode character u’\xe6′ in position 6: ordinal not in range(128)
I can insert unicode straightly to insert also as TypeError occurs. TypeError: coercing to Unicode: need string or buffer, NoneType found
2 Answers 2
From my experiences, Python and Unicode are often a problem.
Generally speaking, if you have a Unicode string, you can convert it to a normal string like this:
normal_string = unicode_string.encode('utf-8') And convert a normal string to a Unicode string like this:
unicode_string = normal_string.decode('utf-8') ‘utf-8’ is usually the right choice, but not always. You should use the same character set that your database is configured for.
Ok, i finally found how to force python to be in UTF-8 by default: def set_default_encoding(): import sys reload(sys) #to make setdefaultencoding available; IDK why sys.setdefaultencoding(«UTF-8»)
The issue here is that str function tries to convert unicode using ascii codepage, and ascii codepage doesn’t have mapping for u\xe6 (æ — char reference here).
Therefore you need to convert it to some codepage which supports the char. Nowdays the most usual is utf-8 encoding.
>>> x = (u'Abc', u'Lololo', u'Fjordk\xe6r') >>> print x[2].encode("utf8") Fjordkær >>> x[2].encode("utf-8") 'Fjordk\xc3\xa6r' On the other hand you may try to convert it to cp1252 — Western latin alphabet which supports it:
>>> x[2].encode("cp1252") 'Fjordk\xe6r' But Eeaster european charset cp1250 doesn’t support it:
>>> x[2].encode("cp1250") . UnicodeEncodeError: 'charmap' codec can't encode character u'\xe6' in position 6: character maps to The issue with unicode in python is very common, and I would suggest following:
- understand what unicode is
- understand what utf-8 is (it is not unicode)
- understand ascii and other codepages
- recommended conversion workflow: input (any cp) ->convert to unicode -> (process) -> output to utf-8
Ошибки при конвертации#
При конвертации между строками и байтами очень важно точно знать, какая кодировка используется, а также знать о возможностях разных кодировок.
Например, кодировка ASCII не может преобразовать в байты кириллицу:
In [32]: hi_unicode = 'привет' In [33]: hi_unicode.encode('ascii') --------------------------------------------------------------------------- UnicodeEncodeError Traceback (most recent call last) ipython-input-33-ec69c9fd2dae> in module>() ----> 1 hi_unicode.encode('ascii') UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5: ordinal not in range(128)
Аналогично, если строка «привет» преобразована в байты, и попробовать преобразовать ее в строку с помощью ascii, тоже получим ошибку:
In [34]: hi_unicode = 'привет' In [35]: hi_bytes = hi_unicode.encode('utf-8') In [36]: hi_bytes.decode('ascii') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) ipython-input-36-aa0ada5e44e9> in module>() ----> 1 hi_bytes.decode('ascii') UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0: ordinal not in range(128)
Еще один вариант ошибки, когда используются разные кодировки для преобразований:
In [37]: de_hi_unicode = 'grüezi' In [38]: utf_16 = de_hi_unicode.encode('utf-16') In [39]: utf_16.decode('utf-8') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) ipython-input-39-4b4c731e69e4> in module>() ----> 1 utf_16.decode('utf-8') UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
Наличие ошибок — это хорошо. Они явно говорят, в чем проблема. Хуже, когда получается так:
In [40]: hi_unicode = 'привет' In [41]: hi_bytes = hi_unicode.encode('utf-8') In [42]: hi_bytes Out[42]: b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' In [43]: hi_bytes.decode('utf-16') Out[43]: '뿐胑룐닐뗐苑'
Обработка ошибок#
У методов encode и decode есть режимы обработки ошибок, которые указывают, как реагировать на ошибку преобразования.
Параметр errors в encode#
По умолчанию encode использует режим strict — при возникновении ошибок кодировки генерируется исключение UnicodeError. Примеры такого поведения были выше.
Вместо этого режима можно использовать replace, чтобы заменить символ знаком вопроса:
In [44]: de_hi_unicode = 'grüezi' In [45]: de_hi_unicode.encode('ascii', 'replace') Out[45]: b'gr?ezi'
Или namereplace, чтобы заменить символ именем:
In [46]: de_hi_unicode = 'grüezi' In [47]: de_hi_unicode.encode('ascii', 'namereplace') Out[47]: b'gr\\Nezi'
Кроме того, можно полностью игнорировать символы, которые нельзя закодировать:
In [48]: de_hi_unicode = 'grüezi' In [49]: de_hi_unicode.encode('ascii', 'ignore') Out[49]: b'grezi'
Параметр errors в decode#
В методе decode по умолчанию тоже используется режим strict и генерируется исключение UnicodeDecodeError.
Если изменить режим на ignore, как и в encode, символы будут просто игнорироваться:
In [50]: de_hi_unicode = 'grüezi' In [51]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [52]: de_hi_utf8 Out[52]: b'gr\xc3\xbcezi' In [53]: de_hi_utf8.decode('ascii', 'ignore') Out[53]: 'grezi'
Режим replace заменит символы:
In [54]: de_hi_unicode = 'grüezi' In [55]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [56]: de_hi_utf8.decode('ascii', 'replace') Out[56]: 'gr��ezi'
Python encode error ascii
Last updated: Feb 18, 2023
Reading time · 4 min

# UnicodeEncodeError: ‘ascii’ codec can’t encode character in position
The Python «UnicodeEncodeError: ‘ascii’ codec can’t encode character in position» occurs when we use the ascii codec to encode a string that contains non-ascii characters.
To solve the error, specify the correct encoding, e.g. utf-8 .

Here is an example of how the error occurs.
Copied!my_str = 'one ф' # ⛔️ UnicodeEncodeError: 'ascii' codec can't encode character '\u0444' in position 4: ordinal not in range(128) my_bytes = my_str.encode('ascii')
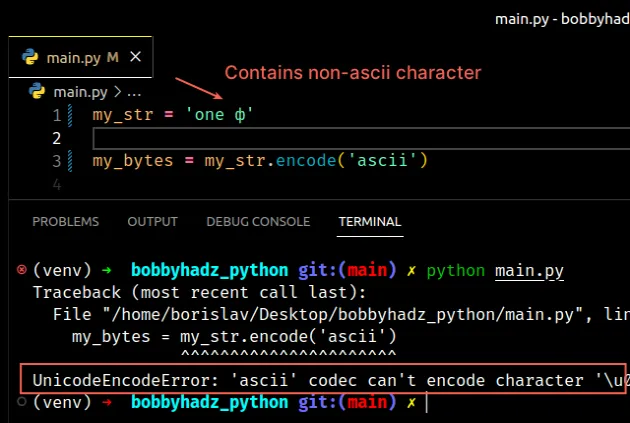
The error is caused because the string contains non-ASCII characters.
# Use the correct encoding to encode the string
To solve the error, use the correct encoding to encode the string, e.g. utf-8 .
Copied!my_str = 'one ф' my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'one \xd1\x84'
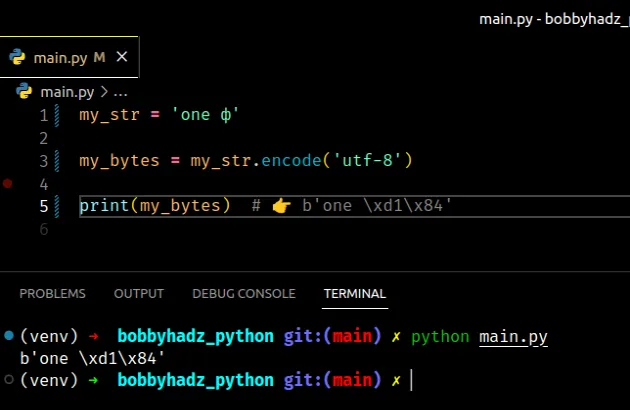
If you got the error when opening a file, set the encoding keyword argument to utf-8 in the call to the open() function.
Copied!my_str = 'one ф' # 👇️ set encoding to utf-8 with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
You can view all of the standard encodings in this table of the official docs.
Encoding is the process of converting a string to a bytes object and decoding is the process of converting a bytes object to a string .
Here is what the complete process looks like.
Copied!my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'one \xd1\x84' # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8') print(my_str_again) # 👉️ "one ф"
When decoding a bytes object, we have to use the same encoding that was used to encode the string to a bytes object.
The str.encode() method is used to convert a string to bytes.
The bytes.decode() method is used to convert a bytes object to a string.
Make sure to not mix the two as that often causes issues.
# Set the errors keyword argument to ignore
If the error persists when using the utf-8 encoding, try setting the errors keyword argument to ignore to ignore characters that cannot be encoded.
Copied!my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8', errors='ignore') print(my_bytes) # 👉️ b'one \xd1\x84' # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8', errors='ignore') print(my_str_again) # 👉️ "one ф"
Note that ignoring characters that cannot be encoded can lead to data loss.
# Try using the ascii encoding to encode the string
You can also try using the ascii encoding with errors set to ignore to ignore any non-ASCII characters.
Copied!my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('ascii', errors='ignore') print(my_bytes) # 👉️ b'one ' # 👇️ decode bytes to str my_str_again = my_bytes.decode('ascii', errors='ignore') print(my_str_again) # 👉️ "one"
Notice that the last character (which is a non-ASCII character) got dropped when we encoded the string into bytes.
# Set the encoding keyword argument to utf-8 when opening a file
If you got the error when opening a file, open the file with encoding set to utf-8 .
Copied!my_str = 'one ф' # 👇️ set encoding to utf-8 with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
You can also set the errors keyword argument to ignore to ignore any encoding errors when opening a file.
Copied!my_str = 'one ф' with open('example.txt', 'w', encoding='utf-8', errors='ignore') as f: f.write(my_str)
# Setting the encoding globally with an environment variable
If the error persists, try to set the encoding globally using an environment variable.
Copied!# on Linux and macOS export PYTHONIOENCODING=utf-8 # on Windows setx PYTHONIOENCODING=utf-8 setx PYTHONLEGACYWINDOWSSTDIO=utf-8
Make sure to use the correct command depending on your operating system.
The environment variables must be set before running your script.
If the PYTHONIOENCODING environment variable is set before running the interpreter, it overrides the encoding used for stdin and stdout .
On Windows, you also have to set the PYTHONLEGACYWINDOWSSTDIO environment variable.
If the error persists, try to add the following lines at the top of your file.
Copied!import sys sys.stdin.reconfigure(encoding='utf-8') sys.stdout.reconfigure(encoding='utf-8')
The sys module can be used to set the encoding globally if nothing else works.
Make sure the lines at added at the top of your file before you try to write to a file or encode a string to bytes.
# Set the encoding keyword argument to utf-8 when sending emails
If you got the error when using the smtplib module, encode the string using the utf-8 encoding before sending it.
Copied!my_str = 'one ф' encoded_message = my_str.encode('utf-8') server.sendmail( 'from@gmail.com', 'to@gmail.com', encoded_message )
Notice that we passed the encoded message as an argument to server.sendmail() .
If you don’t encode the message yourself, Python will try to encode it using the ASCII codec when you call the sendmail() method.
Since the message contains non-ASCII characters, the error is raised.
# Setting the LANG and LC_ALL environment variables incorrectly
If you are on Debian (Ubuntu), you might get the error if you’ve set the following 2 environment variables incorrectly.
- LANG — Determines the default locale in the absence of other locale-related environment variables.
- LC_ALL — Overrides all locale variables (except LANGUAGE ).
You can print the environment variables with the echo command.
Copied!echo $LANG echo $LC_ALL
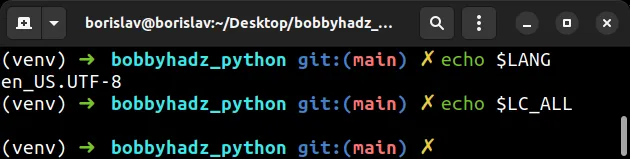
The LANG environment variable should be set to en_US.UTF-8 and the LC_ALL environment variable should not be set.
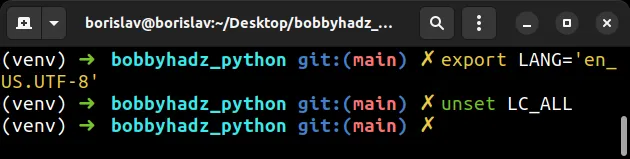
You can run the following commands if you need to correct the values of the environment variables.
Copied!# ✅ set LANG environment variable export LANG='en_US.UTF-8' # ✅ unset LC_ALL environment variable unset LC_ALL
If the error persists, try to install the language-pack-en package from your terminal.
Copied!sudo apt-get install language-pack-en
This might help if your operating system is out of date and has missing dependencies.
I wrote a book in which I share everything I know about how to become a better, more efficient programmer.