- Сложность операций со словарями
- User
- list
- collections.deque
- dict
- Notes
- Сколько стоят операции над list, set и dict в Python? Разбираемся с временной сложностью
- Что означает нотация «O» большое?
- Значения нотации «О» большое
- O(1)
- O(log n)
- O(n)
- O(n log n)
- O(n^2)
- O(n!)
- Благоприятные, средние и худшие случаи
- Коллекции Python и их временная сложность
- Список (list)
- Операции списка и их временная сложность
- Множество (set)
- Операции с множествами и их временная сложность
- Словарь (dict)
- Операции со словарями и их временная сложность
Сложность операций со словарями
В таблице ниже приводится усреднённая сложность. Амортизированный худший случай обычно описывается O(n) . Для усреднённой сложности предполагается, что хеш-функция для словарей в состоянии сделать конфликты редкими. Также предполагается, что ключи, используемые в параметрах, выбираются равномерно из множества всех существующих ключей.
Далее n — количество элементов в контейнере; k — значение параметра, либо количество элементов в параметре.
Указанная ниже сложность справледлива и для defaultdict (вместе с доступными операциями они наследуют от словарей и их сложности). Предполагается, что конструирование нового defaultdict имеет сложность O(1) (что справледливо для часто используемых int(), list(), set()).
| Обращение по индексу | O(1) | d[k] | |
| Присвоение | O(1) | d[k] = v | |
| len | O(1) | len(d) | |
| del | O(1) | del d[k] | |
| .setdefault | O(1) | d.setdefault(1) | |
| .pop | O(1) | d.pop(k) | |
| .popitem | O(1) | d.popitem() | |
| .clear | O(1) | d.clear() | То же: d = <> и d = dict() . |
| Представление | O(1) | d.keys() | |
| Создание | O(k) | dict(obj) | Зависит от числа кортежей (ключ, значение). |
| Проход | O(n) | for k in d: | То же для keys(), values(), items(). |
| .copy | O(n) | d1 = d.copy() |
Для словарей, где ключи являются строками, используется быстрый путь. Это не оказывает влияния на алгоритмическую сложность, однако сильно влияет на постоянные факторы — то, на сколько быстро исполяется типовое приложение.
User
This page documents the time-complexity (aka «Big O» or «Big Oh») of various operations in current CPython. Other Python implementations (or older or still-under development versions of CPython) may have slightly different performance characteristics. However, it is generally safe to assume that they are not slower by more than a factor of O(log n).
Generally, ‘n’ is the number of elements currently in the container. ‘k’ is either the value of a parameter or the number of elements in the parameter.
list
The Average Case assumes parameters generated uniformly at random.
Internally, a list is represented as an array; the largest costs come from growing beyond the current allocation size (because everything must move), or from inserting or deleting somewhere near the beginning (because everything after that must move). If you need to add/remove at both ends, consider using a collections.deque instead.
collections.deque
A deque (double-ended queue) is represented internally as a doubly linked list. (Well, a list of arrays rather than objects, for greater efficiency.) Both ends are accessible, but even looking at the middle is slow, and adding to or removing from the middle is slower still.
See dict — the implementation is intentionally very similar.
- As seen in the source code the complexities for set difference s-t or s.difference(t) (set_difference()) and in-place set difference s.difference_update(t) (set_difference_update_internal()) are different! The first one is O(len(s)) (for every element in s add it to the new set, if not in t). The second one is O(len(t)) (for every element in t remove it from s). So care must be taken as to which is preferred, depending on which one is the longest set and whether a new set is needed.
- To perform set operations like s-t, both s and t need to be sets. However you can do the method equivalents even if t is any iterable, for example s.difference(l), where l is a list.
dict
The Average Case times listed for dict objects assume that the hash function for the objects is sufficiently robust to make collisions uncommon. The Average Case assumes the keys used in parameters are selected uniformly at random from the set of all keys.
Note that there is a fast-path for dicts that (in practice) only deal with str keys; this doesn’t affect the algorithmic complexity, but it can significantly affect the constant factors: how quickly a typical program finishes.
Notes
[1] = These operations rely on the «Amortized» part of «Amortized Worst Case». Individual actions may take surprisingly long, depending on the history of the container. [2] = Popping the intermediate element at index k from a list of size n shifts all elements after k by one slot to the left using memmove. n — k elements have to be moved, so the operation is O(n — k). The best case is popping the second to last element, which necessitates one move, the worst case is popping the first element, which involves n — 1 moves. The average case for an average value of k is popping the element the middle of the list, which takes O(n/2) = O(n) operations. [3] = For these operations, the worst case n is the maximum size the container ever achieved, rather than just the current size. For example, if N objects are added to a dictionary, then N-1 are deleted, the dictionary will still be sized for N objects (at least) until another insertion is made.TimeComplexity (last edited 2023-01-19 22:35:03 by AndrewBadr )
Сколько стоят операции над list, set и dict в Python? Разбираемся с временной сложностью

Программисту, работающему с данными, крайне важно выбирать правильные структуры данных для решения поставленной задачи, ведь выбор неправильного типа данных плохо влияет на производительность приложения. В этой статье объясняется нотация «О» большое и сложность ключевых операций структур данных в CPython.
Что означает нотация «O» большое?
В алгоритме выполняется ряд операций. Эти операции могут включать в себя итерацию по коллекции, копирование элемента или всей коллекции, добавление элемента в коллекцию, вставку элемента в начало или конец коллекции, удаление элемента или обновление элемента в коллекции.
«O» большое служит обозначением временной сложности операций алгоритма. Она показывает, сколько времени потребуется алгоритму для вычисления требуемой операции. Можно также измерить пространственную сложность (сколько места занимает алгоритм), но в этой статье мы сосредоточимся на временной.
Проще говоря, нотация «O» большое — это способ измерения производительности операции на основе размера ввода, известного как n.
Значения нотации «О» большое
На письме временная сложность алгоритма обозначается как O(n), где n — размер входной коллекции.
O(1)
Обозначение константной временной сложности. Независимо от размера коллекции, время, необходимое для выполнения операции, константно. Это обозначение константной временной сложности. Эти операции выполняются настолько быстро, насколько возможно. Например, операции, которые проверяют, есть ли внутри коллекции элементы, имеют сложность O(1).
O(log n)
Обозначение логарифмической временной сложности. В этом случае когда размер коллекции увеличивается, время, необходимое для выполнения операции, логарифмически увеличивается. Эту сложность имеют потенциально оптимизированные алгоритмы поиска.
O(n)
Обозначение линейной временной сложности. Время, необходимое для выполнения операции, прямо и линейно пропорционально количеству элементов в коллекции. Это обозначение линейной временной сложности. Это что-то среднее с точки зрения производительности. Например, если мы хотим суммировать все элементы в коллекции, нужно будет выполнить итерацию по коллекции. Следовательно, итерация коллекции является операцией O(n).
O(n log n)
Обозначение квазилинейной временной сложности. Скорость выполнения операции является квазилинейной функцией числа элементов в коллекции. Временная сложность оптимизированного алгоритма сортировки обычно равна O(n log n).
O(n^2)
Обозначение квадратичной временной сложности. Время, необходимое для выполнения операции, пропорционально квадрату элементов в коллекции.
O(n!)
Обозначение факториальной временной сложности. Каждая операция требует вычисления всех перестановок коллекции, следовательно требуемое время выполнения операции является факториалом размера входной коллекции. Это очень медленно.
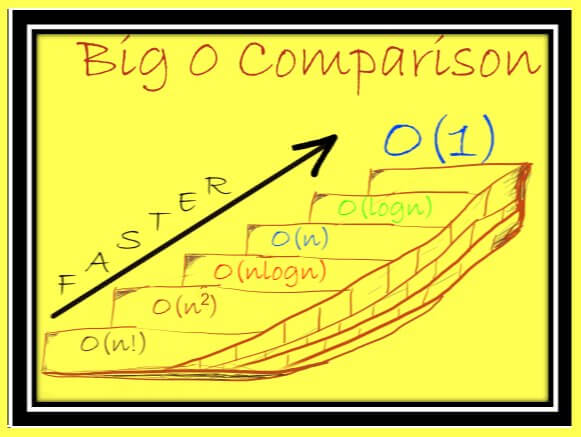
Нотация «O» большое относительна. Она не зависит от машины, игнорирует константы и понятна широкой аудитории, включая математиков, технологов, специалистов по данным и т. д.
Благоприятные, средние и худшие случаи
При вычислении временной сложности операции можно получить сложность на основе благоприятного, среднего или худшего случая.
Благоприятный случай. Как следует из названия, это сценарий, когда структуры данных и элементы в коллекции вместе с параметрами находятся в оптимальном состоянии. Например, мы хотим найти элемент в коллекции. Если этот элемент оказывается первым элементом коллекции, то это лучший сценарий для операции.
Средний случай. Определяем сложность на основе распределения значений входных данных.
Худший случай. Структуры данных и элементы в коллекции вместе с параметрами находятся в наиболее неоптимальном состоянии. Например, худший случай для операции, которой требуется найти элемент в большой коллекции в виде списка — когда искомый элемент находится в самом конце, а алгоритм перебирает коллекцию с самого начала.
Коллекции Python и их временная сложность
Список (list)
Список является одной из самых важных структур данных в Python. Можно использовать списки для создания стека или очереди. Списки — это упорядоченные и изменяемые коллекции, которые можно обновлять по желанию.
Операции списка и их временная сложность
Вставка: O(n).
Получение элемента: O(1).
Удаление элемента: O(n).
Проход: O(n).
Получение длины: O(1).
Множество (set)
Множества также являются одними из наиболее используемых типов данных в Python. Множество представляет собой неупорядоченную коллекцию. Множество не допускает дублирования, и, следовательно, каждый элемент в множестве уникален. Множество поддерживает множество математических операций, таких как объединение, разность, пересечение и так далее.
Операции с множествами и их временная сложность
Проверить наличие элемента в множестве: O(1).
Отличие множества A от B: O(длина A).
Пересечение множеств A и B: O(минимальная длина A или B).
Объединение множеств A и B: O(N) , где N это длина (A) + длина (B).
Словарь (dict)
Словарь — это коллекция пар ключ-значение. Ключи в словаре уникальны, чтобы предотвратить коллизию элементов. Это чрезвычайно полезная структура данных.
Словари индексируются по ключам, которые могут быть строками, числами или даже кортежами со строками, числами или кортежами. Над словарём можно выполнить ряд операций, таких как сохранение значения для ключа, извлечение элемента на основе ключа, или итерация по элементам и так далее.
Операции со словарями и их временная сложность
Здесь мы считаем, что ключ используется для получения, установки или удаления элемента.
Получение элемента: O(1).
Установка элемента: O(1).
Удаление элемента: O(1).
Проход по словарю: O(n).