- Как читать большие текстовые файлы в Python
- Чтение больших текстовых файлов в Python
- Что если большой файл не имеет строк?
- Читайте ещё по теме:
- Обработка больших файлов с использованием Python
- How to Read Large Text Files in Python
- Reading Large Text Files in Python
- What if the Large File doesn’t have lines?
Как читать большие текстовые файлы в Python
Как читать большие файлы в Python? Мы можем использовать объект файла Python в качестве итератора для чтения его линии по строке. Мы также можем использовать буфер для чтения больших двоичных файлов.
Объект Python File предоставляет различные способы чтения текстового файла. Популярным способом является использование метода readleines (), который возвращает список всех строк в файле. Тем не менее, это не подходит для чтения большого текстового файла, потому что весь файл содержится будет загружен в память.
Чтение больших текстовых файлов в Python
Мы можем использовать объект файла как итератор. Итератор вернет каждую строку одну на одну, которая может быть обработана. Это не будет читать весь файл в память, и он подходит для чтения больших файлов в Python.
Вот фрагмент кода, чтобы прочитать большой файл в Python, обрабатывая его как итератор.
import resource import os file_name = "/Users/pankaj/abcdef.txt" print(f'File Size is MB') txt_file = open(file_name) count = 0 for line in txt_file: # we can process file line by line here, for simplicity I am taking count of lines count += 1 txt_file.close() print(f'Number of Lines in the file is ') print('Peak Memory Usage =', resource.getrusage(resource.RUSAGE_SELF).ru_maxrss) print('User Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_utime) print('System Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_stime) Когда мы запускаем эту программу, производится вывод:
File Size is 257.4920654296875 MB Number of Lines in the file is 60000000 Peak Memory Usage = 5840896 User Mode Time = 11.46692 System Mode Time = 0.09655899999999999
- Я использую ОС модуль Чтобы распечатать размер файла.
- Ресурсный модуль используется для проверки времени использования памяти и процессора программы.
Мы также можем использовать С заявлением Чтобы открыть файл. В этом случае нам не нужно явно закрыть файл объект.
with open(file_name) as txt_file: for line in txt_file: # process the line pass
Что если большой файл не имеет строк?
Приведенный выше код будет работать отлично, когда содержимое большого файла разделено на многие строки. Но, если в одной строке есть большое количество данных, то она будет использовать много памяти. В этом случае мы можем прочитать содержимое файла в буфер и обработать его.
with open(file_name) as f: while True: data = f.read(1024) if not data: break print(data)
Приведенный выше код будет читать файловые данные в буфер 1024 байта. Тогда мы печатаем его к консоли.
Когда весь файл читается, данные станут пустыми, а оператор разрыва завершится цикл While.
Этот метод также полезен для чтения двоичного файла, такого как изображения, PDF, документы Word и т. Д.
Вот простой фрагмент кода, чтобы сделать копию файла.
with open(destination_file_name, 'w') as out_file: with open(source_file_name) as in_file: for line in in_file: out_file.write(line)
Читайте ещё по теме:
Обработка больших файлов с использованием Python
В последний год или около того, и с моим повышенным вниманием к данным ribo-seq я полностью осознал, что означает термин большие данные. Исследования ribo-seq в их необработанном виде могут легко охватить сотни ГБ, что означает, что их обработка как своевременной, так и эффективной требует некоторого обдумывания. В этом посте, и, надеюсь, в следующем, я хочу подробно описать некоторые из методов, которые я придумала (собрал из разных статей в интернете), которые помогают мне получать данные такого масштаба. В частности, я буду подробно описывать методы для Python, хотя некоторые методы можно перенести на другие языки.
Мой первый большой совет по Python о том, как разбить ваши файлы на более мелкие блоки (или куски) таким образом, чтобы вы могли использовать несколько процессоров. Давайте начнем с самого простого способа чтения файла на python.
with open("input.txt") as f: data = f.readlines() for line in data: process(line) Эта ошибка, сделанная выше в отношении больших данных, заключается в том, что она считывает все данные в ОЗУ, прежде чем пытаться обрабатывать их построчно. Это, вероятно, самый простой способ вызвать переполнение памяти и возникновение ошибки. Давайте исправим это, читая данные построчно, чтобы в любой момент времени в оперативной памяти сохранялась только одна строка.
with open("input.txt") as f: for line in f: process(line) Это большое улучшение, и именно оно не перегружает ОЗУ при загрузке большого файла. Затем мы должны попытаться немного ускорить это, используя все эти бездействующие ядра.
import multiprocessing as mp pool = mp.Pool(cores) jobs = [] with open("input.txt") as f: for line in f: jobs.append( pool.apply_async(process,(line)) ) # дождаться окончания всех работ for job in jobs: job.get() pool.close() При условии, что порядок обработки строк не имеет значения, приведенный выше код генерирует набор (пул) обработчиков, в идеале один для каждого ядра, перед созданием группы задач (заданий), по одной для каждой строки. Я склонен использовать объект Pool, предоставляемый модулем multiprocessing, из-за простоты использования, однако, вы можете порождать и контролировать отдельные обработчики, используя mp.Process, если вы хотите более точное управление. Для простого вычисления числа объект Pool очень хорош.
Хотя вышеперечисленное теперь использует все эти ядра, к сожалению, снова возникают проблемы с памятью. Мы специально используем функцию apply_async, чтобы пул не блокировался во время обработки каждой строки. Однако при этом все данные снова считываются в память; это время сохраняется в виде отдельных строк, связанных с каждым заданием, ожидая обработки в строке. Таким образом, память снова будет переполнена. В идеале метод считывает строку в память только тогда, когда подходит ее очередь на обработку.
import multiprocessing as mp def process_wrapper(lineID): with open("input.txt") as f: for i, line in enumerate(f): if i != lineID: continue else: process(line) break pool = mp.Pool(cores) jobs = [] with open("input.txt") as f: for ID, line in enumerate(f): jobs.append( pool.apply_async(process_wrapper,(ID)) ) # дождаться окончания всех работ for job in jobs: job.get() pool.close() Выше мы изменили функцию, переданную в пул обработчика, чтобы она включала в себя открытие файла, поиск указанной строки, чтение ее в память и последующую обработку. Единственный вход, который теперь сохраняется для каждой порожденной задачи — это номер строки, что предотвращает переполнение памяти. К сожалению, накладные расходы, связанные с необходимостью найти строку путем итеративного чтения файла для каждого задания, являются несостоятельными, поскольку по мере того, как вы углубляетесь в файл, процесс занимает все больше времени. Чтобы избежать этого, мы можем использовать функцию поиска файловых объектов, которая пропускает вас в определенное место в файле. Сочетание с функцией tell, которая возвращает текущее местоположение в файле, дает:
import multiprocessing as mp def process_wrapper(lineByte): with open("input.txt") as f: f.seek(lineByte) line = f.readline() process(line) pool = mp.Pool(cores) jobs = [] with open("input.txt") as f: nextLineByte = f.tell() for line in f: jobs.append( pool.apply_async(process_wrapper,(nextLineByte)) ) nextLineByte = f.tell() for job in jobs: job.get() pool.close() Используя поиск, мы можем перейти непосредственно к правильной части файла, после чего мы читаем строку в память и обрабатываем ее. Мы должны быть осторожны, чтобы правильно обрабатывать первую и последнюю строки, но в противном случае это будет именно то, что мы излагаем, а именно использование всех ядер для обработки данного файла без переполнения памяти.
Я закончу этот пост с небольшим обновлением вышеупомянутого, поскольку есть разумные накладные расходы, связанные с открытием и закрытием файла для каждой отдельной строки. Если мы обрабатываем несколько строк файла за один раз, мы можем сократить эти операции. Самая большая техническая сложность при этом заключается в том, что при переходе к месту в файле вы, скорее всего, не находитесь в начале строки. Для простого файла, как в этом примере, это просто означает, что вам нужно вызвать readline, который читает следующий символ новой строки. Более сложные типы файлов, вероятно, требуют дополнительного кода, чтобы найти подходящее место для начала / конца чанка.
import multiprocessing as mp, os def process_wrapper(chunkStart, chunkSize): with open("input.txt") as f: f.seek(chunkStart) lines = f.read(chunkSize).splitlines() for line in lines: process(line) def chunkify(fname,size=1024*1024): fileEnd = os.path.getsize(fname) with open(fname,'r') as f: chunkEnd = f.tell() while True: chunkStart = chunkEnd f.seek(size,1) f.readline() chunkEnd = f.tell() yield chunkStart, chunkEnd - chunkStart if chunkEnd > fileEnd: break pool = mp.Pool(cores) jobs = [] for chunkStart,chunkSize in chunkify("input.txt"): jobs.append( pool.apply_async(process_wrapper,(chunkStart,chunkSize)) ) for job in jobs: job.get() pool.close() Во всяком случае, я надеюсь, что некоторые из вышеперечисленных примеров были новыми и возможно, полезными для вас. Если вы знаете лучший способ сделать что-то (на python), мне было бы очень интересно узнать об этом. В следующем посте, который будет опубликован в ближайшем будущем, я расширю этот код, превратив его в родительский класс, из которого создается несколько дочерних элементов для использования с различными типами файлов.
How to Read Large Text Files in Python

While we believe that this content benefits our community, we have not yet thoroughly reviewed it. If you have any suggestions for improvements, please let us know by clicking the “report an issue“ button at the bottom of the tutorial.
Python File object provides various ways to read a text file. The popular way is to use the readlines() method that returns a list of all the lines in the file. However, it’s not suitable to read a large text file because the whole file content will be loaded into the memory.
Reading Large Text Files in Python
We can use the file object as an iterator. The iterator will return each line one by one, which can be processed. This will not read the whole file into memory and it’s suitable to read large files in Python. Here is the code snippet to read large file in Python by treating it as an iterator.
import resource import os file_name = "/Users/pankaj/abcdef.txt" print(f'File Size is MB') txt_file = open(file_name) count = 0 for line in txt_file: # we can process file line by line here, for simplicity I am taking count of lines count += 1 txt_file.close() print(f'Number of Lines in the file is ') print('Peak Memory Usage =', resource.getrusage(resource.RUSAGE_SELF).ru_maxrss) print('User Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_utime) print('System Mode Time =', resource.getrusage(resource.RUSAGE_SELF).ru_stime) File Size is 257.4920654296875 MB Number of Lines in the file is 60000000 Peak Memory Usage = 5840896 User Mode Time = 11.46692 System Mode Time = 0.09655899999999999 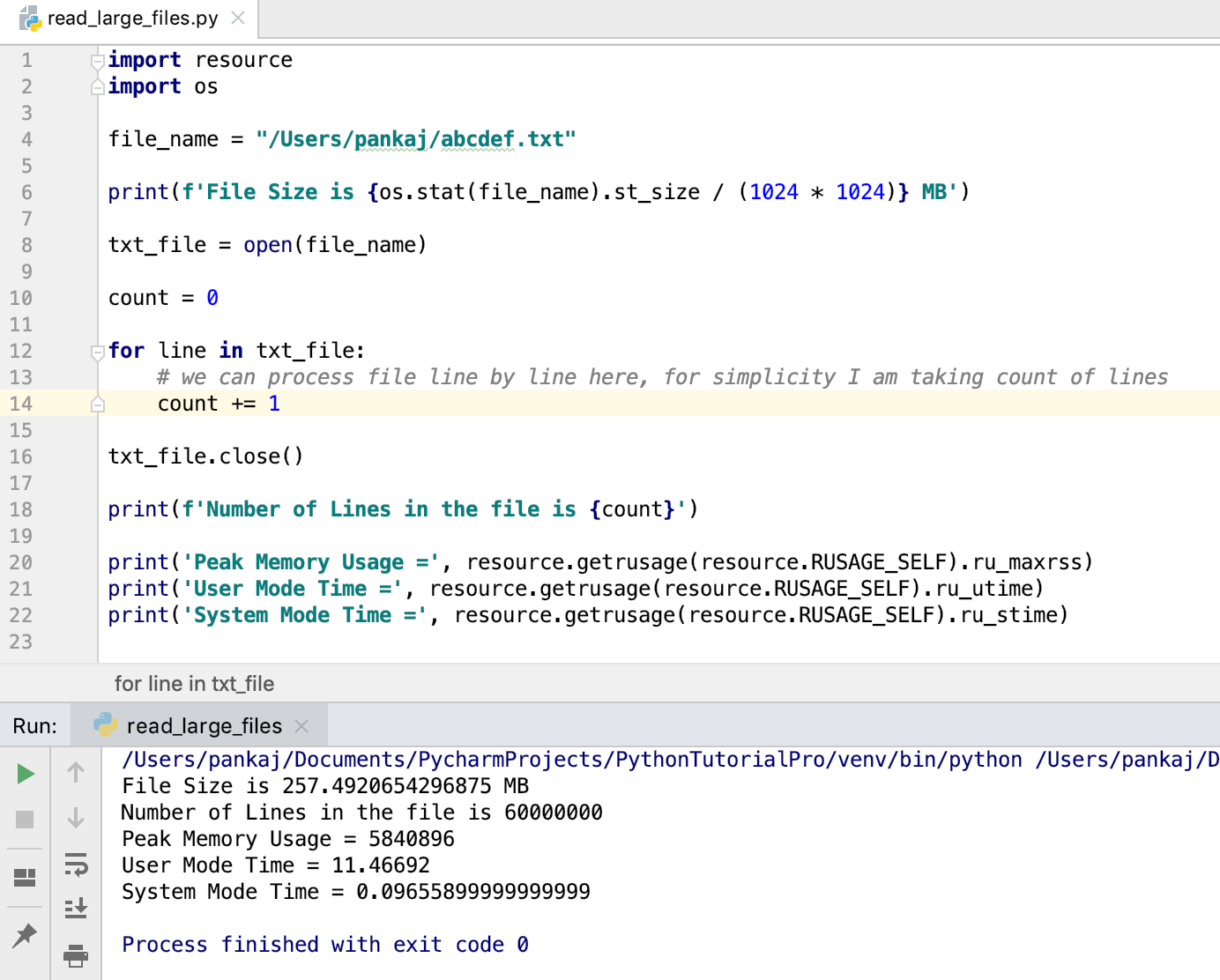
- I am using os module to print the size of the file.
- The resource module is used to check the memory and CPU time usage of the program.
We can also use with statement to open the file. In this case, we don’t have to explicitly close the file object.
with open(file_name) as txt_file: for line in txt_file: # process the line pass What if the Large File doesn’t have lines?
The above code will work great when the large file content is divided into many lines. But, if there is a large amount of data in a single line then it will use a lot of memory. In that case, we can read the file content into a buffer and process it.
with open(file_name) as f: while True: data = f.read(1024) if not data: break print(data) The above code will read file data into a buffer of 1024 bytes. Then we are printing it to the console. When the whole file is read, the data will become empty and the break statement will terminate the while loop. This method is also useful in reading a binary file such as images, PDF, word documents, etc. Here is a simple code snippet to make a copy of the file.
with open(destination_file_name, 'w') as out_file: with open(source_file_name) as in_file: for line in in_file: out_file.write(line) Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.