PHP пример парсинга URL для «User Friendly URLs»
Во многих статьях встречал описание user friendly urls, но ни разу не было приведено простого и понятного примера реализации. В этой статье приведен такой пример.
Итак. Для начала приведу код примера, а далее подробно разберем все встречающиеся в нем функции.
php пример.
Теория. user friendly urls – технология, которая помогает избавится от некрасивых ссылок с параметрами (напр.: http://site.ru/index.php?action=view&id=1&print=true ) и заменить их более понятными человеку (напр.: http://site.ru/1/print/ ). Основное преимущество в том, то, что ссылки «понятного» вида легче запоминаются человеком. Отличным примером реализации этой технологии является сайт nokia, ну и, конечно же, наш php wars. В данный момент использование «понятных ссылок» стандартом и показателем уважения к посетителю. Это неотъемлемый элемент «юзабилити» любого сайта.
Основы практики. Идея данной технологии проста. Это использование вместо стандартной страницы 404 специального срипта, который бы перенаправил (или сам вывел) запрашиваемое содержимое.
Пример. Посетитель вводит в браузере http://phpwars.net/content/index.html. На самом деле на сервере нет никакого каталога «content» и уж тем более файла «index.html» в нем. Все происходит так. Веб-сервер пытается открыть файл «/content/index.html». Не найдя его он отображает страницу 404 (которая как уже говорилось выше является специально подготовленным скриптом). Далее в работу вступает скрипт. Он посылает http заголовок 200 (страница найдена), обрабатывает запрашиваемый пользователем url и, как например на php wars, выбирает нужные данные из базы данных и формирует страницу и выдает ее в браузер посетителя.
В нашем примере рассмотрен как раз самые первые этапы: отправка заголовка и анализ url. Нашей целью будет превратить строку введенную посетителем в массив параметров.
Для отправки http заголовков в php служит функция «header». Ей мы и пользуемся в самом начале, отправляя заголовок «http/1.1 200 ok».
Далее мы проверяем на пустоту элемент супер-глобального массива «$_server». Это необходимо для того, что бы выяснить как обратились к скрипту. Например, Вы настраиваете свой веб-сревер что бы вместо страницы 404 он отображал index.php. Таким образом становятся возможными два варианта. Посетитель зашел по ссылке прямой ссылке http://phpwars.net/index.php или по какой-либо понятной ссылке http://phpwars.net/content/index.html. В первом случае элемент «redirect_url» будет пустым. Во втором он будет равен «/content/index.html». Если элемент пуст, то оставляем массив параметров пустым.
Следующим шагом мы присваиваем значение элемента «redirect_url» переменной «$url». Это делается для того, что бы была возможность в дальнейшем использовать этот элемент.
Готовим «$url» к обработке. Если первым символом в строке является слеш, то удаляем его. Это необходимо для того, что бы при набивке массива у нас не получалось первого пустого элемента («нарезка» массива будет производится по слешам).
Следующим шагом мы удаляем последний слеш в конце строки, если он есть.
if($url[strlen($url)-1]==’/’) $url=substr($url, 0, -1);
Как видно для выделения подстрок в php используется функция «substr». Ей передаются три параметра:
переменная, из которой необходимо выделить подстроку
номер символа, с которого начинается выделяемая подстрока
номер последнего символа выделяемой подстроки
Если передать третий параметр, как отрицательное число, то отсчет будет производится с конца строки. Естественно, что функция возвращает нужную подстроку в случае удачи либо flase в противном случае.
Разделяй и властвуй.
Следующим шагом мы разделяем строку на элементы с помощью функции «explode». В качестве разделителя используем слеш. Как видно функции «explode» передается только два параметра:
переменная, которую надо разделить
разделитель по которому будет производится деление. Заметьте, что в качестве разделителя может использоваться не только один символ, а произвольная строка.
Функция возвращает массив полученный при разделении строки.
Далее мы считаем количество элементов в массиве с помощью функции «count». Если у нас ноль элементов (массив пуст), то присваиваем нашему результирующему массиву параметров также пустой массив. Такая ситуация может сложиться только теоретически, но все же – береженого Бог бережет.
Рассматриваем ситуация, когда у нас больше нуля элементов. Тут все достаточно просто. В цикле мы проходимся по всему массиву и очередной элемент не пуст присваиваем ему соответствующий элемент результирующего массива. Звучит сложно, но как видно в это всего несколько строк кода.
Итог.
Вот и все. Обработка закончена. В результате у нас получился массив с обработанным url. Так например, если посетитель зайдет по ссылке http://phpwars.net/content/index.html, то в нашем массиве будут следующие элементы:
$p[0]=”content”; $p[1]=”index.html”; Дальнейшая реализация user friendly urls уже зависит от того, какие другие технологии используются (mysql например).
Как найти все ссылки на странице через PHP

Иногда перед программистом стоит не самая простая задача: найти все ссылки на странице с помощью PHP. Где это может быть нужно? Да, много где, например, при выводе одного сайта на другом. Для этого требуется вытащить из него все ссылки и заменить на другие. Также поиск ссылок используется при создании ЧПУ-ссылок, ведь нужно вытащить все старые ссылки и поставить заместо них новые. В общем, задач можно придумать много, но ключевой вопрос всего один: «Как найти все ссылки на странице через PHP?«. Об этом я и написал данную статью.
Кто имеет хотя бы маленький опыт, тут же скажет, что надо написать регулярное выражение и будет абсолютно прав. Действительно, простыми строковыми функциями данную задачу будет крайне трудно решить. Ведь каждый пишет по-разному, кто-то прописными бувами, кто-то строчными, кто-то ставит пробел после, например, знака «=«, а кто-то нет. У кого-то двойные кавычки, а у кого-то одинарные. В общем, разновидностей очень много. И единственная возможность предусмотреть максимум всего — это регулярное выражение.
Самая сложная часть — это регулярное выражение, ради его публикации данная статья и создавалась, чтобы новичкам не пришлось писать нечто подобное. Хотя это и является очень полезным, но сразу новичок такое никогда не напишет, а для решения задачи это требуется. Конечно, данное регулярное выражение по поиску ссылок неидеальное (едва ли можно написать идеальное), но, думаю, что 99% ссылок будут найдены. А если код писал адекватный верстальщик, то все 100%. А как работать с найденными ссылками дальше, это уже отдельная история.

![]()
Создано 26.09.2012 10:08:17
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
- Кнопка:
Она выглядит вот так: - Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт - BB-код ссылки для форумов (например, можете поставить её в подписи):
Комментарии ( 7 ):
а почему бы просто не воспользоваться функцией getElementsByTagNam(‘a’) ?
SoffRick http://php.net/manual/ru/class.domdocument.php почитайте, а потом умничайте
А DOM в таком случае не целесообразнее использовать? Вроде и проще, и, к тому же, есть достаточно библиотек для этого.
Поиск URL-адресов из текстовой строки через php и regex?
Я знаю, что название вопроса выглядит очень повторяющимся. Но некоторые из решений я не нашел здесь.
Мне нужно найти URL-адреса в текстовой строке:
$pattern = '`.*?((http|https)://[\w#$&+,\/:;=?@.-]+)[^\w#$&+,\/:;=?@.-]*?`i'; if (preg_match_all($pattern,$url_string,$matches))
используя этот шаблон, я смог найти URL-адреса с http:// и https:// которые являются okey. Но у меня есть пользовательский ввод, где люди добавляют URL-адрес, например, www.domain.com даже domain.com
Итак, мне нужно сначала проверить строку, где я могу заменить www.domain.com domain.com общим протоколом http:// перед ними. Или мне нужно придумать более хороший образец?
Я плохо разбираюсь в регулярном выражении и не знаю, что делать.
Моя идея сначала найти URL-адреса с http:// и https:// помещать их в массив, а затем заменить этот url пробелом («») в текстовой строке, а затем использовать для него другие шаблоны. Но я не уверен, какой шаблон использовать.
Я использую этот $url_string = preg_replace($pattern, ‘ ‘, $url_string ); но удаляет, если есть какой-либо URL www.domain.com или domain.com между двумя действительными URL с http:// или https://
Если вы можете помочь, это будет здорово.
Чтобы сделать вещи более ясными:
Мне нужен шаблон или какой-то другой метод, где я могу найти все URL-адреса в текстовом укусе. пример URL:
- domain.com
- www.domain.com
- http://www.domain.com
- http://domain.com
- https://www.domain.com
- https://domain.com
$pattern = '#(www\.|https?://)?[a-z0-9]+\.[a-z0-9]\S*#i'; preg_match_all($pattern, $str, $matches, PREG_PATTERN_ORDER); Я не уверен, правильно понял, что вам нужно, но вы можете использовать что-то вроде этого:
найти, есть ли протокол, указанный в строке, и если не просто добавить http://
Как в PHP находить ссылки без регулярных выражений
От автора: не люблю каждый раз натыкаться на одни и те же грабли! Вот сегодня опять та тема, в которой никак не обойтись без регулярных выражений. Это и есть мои любимые «грабли». Но все равно я не сдамся, и чтобы с помощью PHP находить ссылки, я обойдусь без них!
Никуда без них не деться!
Нет уж, господа консерваторы! Я постараюсь уж как-нибудь реализовать парсинг документов без этого застарелого средства. Ну не хватает у меня терпения на составление шаблонов с помощью регулярных выражений. А когда терпение лопается, то рождаются другие более «ругательные» выражения :). Так что «грабли» в сторону – мы идем по собственному галсу!
Чтобы не опростоволоситься, нам потребуется сторонняя библиотека — Simple HTML DOM. Скачать ее можно по этой ссылке. Не беспокойтесь, версия хоть и старая, но работает. А главное, что это средство посвежее будет, чем выражения регулярные :).
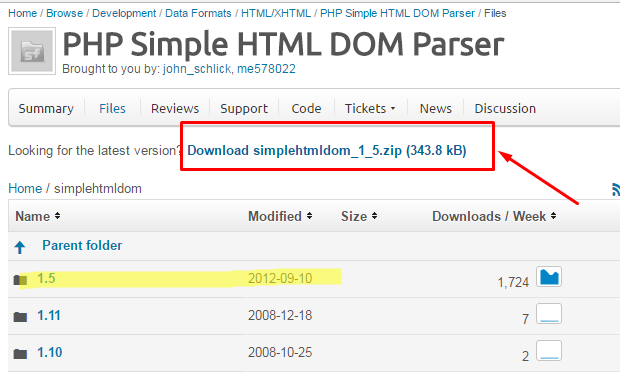
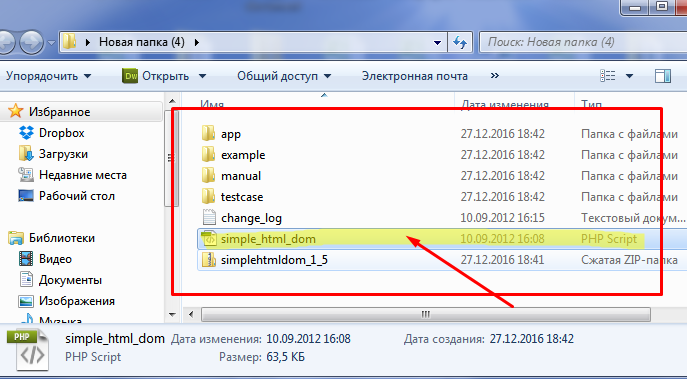
После распаковки помещаем файл simple_html_dom.php в папку со скриптом, чтоб легче было подключать. Все остальные файлы в принципе нас не интересуют, но пригодятся вам в будущем. Там есть и мануал, и примеры использования библиотеки.

Онлайн курс «PHP-разработчик»
Изучите курс и создайте полноценный проект — облачное хранилище файлов
С нуля освоите язык программирования PHP, структурируете имеющиеся знания, а эксперты помогут разобраться с трудными для понимания темами, попрактикуетесь на реальных задачах. Напишете первый проект для портфолио.
Реализуем!
Напомню, что сегодня мы научимся, как найти ссылки PHP без «ужасных» регулярных выражений. Теперь нам осталось подключить скрипт библиотеки у себя в коде и просканировать указанную веб-страницу на наличие гиперссылок.