Text File Parsing with Python
I am trying to parse a series of text files and save them as CSV files using Python (2.7.3). All text files have a 4 line long header which needs to be stripped out. The data lines have various delimiters including » (quote), — (dash), : column, and blank space. I found it a pain to code it in C++ with all these different delimiters, so I decided to try it in Python hearing it is relatively easier to do compared to C/C++. I wrote a piece of code to test it for a single line of data and it works, however, I could not manage to make it work for the actual file. For parsing a single line I was using the text object and «replace» method. It looks like my current implementation reads the text file as a list, and there is no replace method for the list object. Being a novice in Python, I got stuck at this point. Any input would be appreciated! Thanks!
# function for parsing the data def data_parser(text, dic): for i, j in dic.iteritems(): text = text.replace(i,j) return text # open input/output files inputfile = open('test.dat') outputfile = open('test.csv', 'w') my_text = inputfile.readlines()[4:] #reads to whole text file, skipping first 4 lines # sample text string, just for demonstration to let you know how the data looks like # my_text = '"2012-06-23 03:09:13.23",4323584,-1.911224,-0.4657288,-0.1166382,-0.24823,0.256485,"NAN",-0.3489428,-0.130449,-0.2440527,-0.2942413,0.04944348,0.4337797,-1.105218,-1.201882,-0.5962594,-0.586636' # dictionary definition 0-, 1- etc. are there to parse the date block delimited with dashes, and make sure the negative numbers are not effected reps = txt = data_parser(my_text, reps) outputfile.writelines(txt) inputfile.close() outputfile.close() You should attach a copy of the file you need to parse and the expected output, that way it will be easier to help you.
Parsing text with Python

I hate parsing files, but it is something that I have had to do at the start of nearly every project. Parsing is not easy, and it can be a stumbling block for beginners. However, once you become comfortable with parsing files, you never have to worry about that part of the problem. That is why I recommend that beginners get comfortable with parsing files early on in their programming education. This article is aimed at Python beginners who are interested in learning to parse text files.
In this article, I will introduce you to my system for parsing files. I will briefly touch on parsing files in standard formats, but what I want to focus on is the parsing of complex text files. What do I mean by complex? Well, we will get to that, young padawan.
For reference, the slide deck that I use to present on this topic is available here. All of the code and the sample text that I use is available in my Github repo here.
Why parse files?
First, let us understand what the problem is. Why do we even need to parse files? In an imaginary world where all data existed in the same format, one could expect all programs to input and output that data. There would be no need to parse files. However, we live in a world where there is a wide variety of data formats. Some data formats are better suited to different applications. An individual program can only be expected to cater for a selection of these data formats. So, inevitably there is a need to convert data from one format to another for consumption by different programs. Sometimes data is not even in a standard format which makes things a little harder.
Parse Analyse (a string or text) into logical syntactic components.
I don’t like the above Oxford dictionary definition. So, here is my alternate definition.
Parse Convert data in a certain format into a more usable format.
The big picture
With that definition in mind, we can imagine that our input may be in any format. So, the first step, when faced with any parsing problem, is to understand the input data format. If you are lucky, there will be documentation that describes the data format. If not, you may have to decipher the data format for yourselves. That is always fun.
Once you understand the input data, the next step is to determine what would be a more usable format. Well, this depends entirely on how you plan on using the data. If the program that you want to feed the data into expects a CSV format, then that’s your end product. For further data analysis, I highly recommend reading the data into a pandas DataFrame .
If you a Python data analyst then you are most likely familiar with pandas. It is a Python package that provides the DataFrame class and other functions to do insanely powerful data analysis with minimal effort. It is an abstraction on top of Numpy which provides multi-dimensional arrays, similar to Matlab. The DataFrame is a 2D array, but it can have multiple row and column indices, which pandas calls MultiIndex , that essentially allows it to store multi-dimensional data. SQL or database style operations can be easily performed with pandas (Comparison with SQL). Pandas also comes with a suite of IO tools which includes functions to deal with CSV, MS Excel, JSON, HDF5 and other data formats.
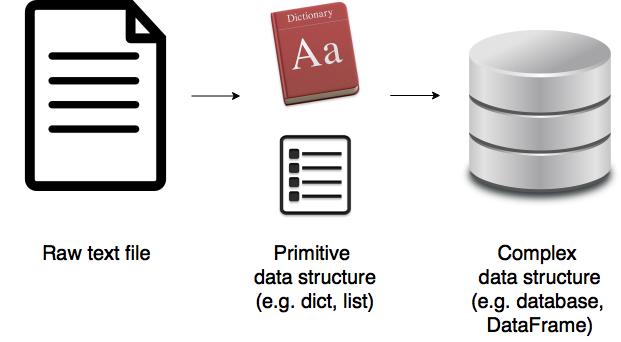
Although, we would want to read the data into a feature-rich data structure like a pandas DataFrame , it would be very inefficient to create an empty DataFrame and directly write data to it. A DataFrame is a complex data structure, and writing something to a DataFrame item by item is computationally expensive. It’s a lot faster to read the data into a primitive data type like a list or a dict . Once the list or dict is created, pandas allows us to easily convert it to a DataFrame as you will see later on. The image below shows the standard process when it comes to parsing any file.
Parsing text in standard format
If your data is in a standard format or close enough, then there is probably an existing package that you can use to read your data with minimal effort.
For example, let’s say we have a CSV file, data.txt:
You can handle this easily with pandas.
Parsing a text file with Python?
I have to do an assignment where i have a .txt file that contains something like this
p
There is no one who loves pain itself, who seeks after it and wants to have it, simply because it is pain. h1
this is another example of what this text file looks like i am suppose to write a python code that parses this text file and creates and xhtml file
I need to find a starting point for this project because i am very new to python and not familiar with alot of this stuff.
This python code is suppose to take each of these «tags» from this text file and put them into an xhtml file I hope that what i ask makes sense to you.
Any help is greatly appreciated,
Thanks in advance!
-bojan
The format of the input file is somewhat ambiguous. It may be the way it is displayed in SO, but. Are these «p», «h1» marks expected to be on a separate line, just before the section to which they are applied, or are they html-like tags, for which the brackets and closing tag have been lost or omitted here?
2 Answers 2
You say you’re very new to Python, so I’ll start at the very low-level. You can iterate over the lines in a file very simply in Python
fyle = open("contents.txt") for lyne in fyle : # Do string processing here fyle.close() Now how to parse it. If each formatting directive (e.g. p, h1), is on a separate line, you can check that easily. I’d build up a dictionary of handlers and get the handler like so:
handlers= # . in the loop if lyne.rstrip() in handlers : # strip to remove trailing whitespace # close current handler? # start new handler? else : # pass string to current handler You could do what Daniel Pryden suggested and create an in-memory data structure first, and then serialize that the XHTML. In that case, the handlers would know how to build the objects corresponding to each tag. But I think the simpler solution, especially if you don’t have lots of time, you have is just to go straight to XHTML, keeping a stack of the current enclosed tags. In that case your «handler» may just be some simple logic to write the tags to the output file/string.
I can’t say more without knowing the specifics of your problem. And besides, I don’t want to do all your homework for you. This should give you a good start.
Parse text files using Python
I have a log file that I would like to parse and plot using matplotlib. After skipping the first 6 lines, I have data of interest. e.g. my log file looks like this:
# 2014-05-09 17:51:50,473 - root - INFO - Epoch = 1, batch = 216, Classif Err = 52.926, lg(p) -1.0350 # 2014-05-09 17:51:53,749 - root - INFO - Test set error = 37.2317 import numpy from numpy import * from pylab import * f1 = open('log.txt', 'r') FILE = f1.readlines() f1.close() for line in FILE: line = line.strip() if ('Epoch' in line): epoch += line.split('Epoch = ') elif('Test set error' in line): test_err += line.split('Test set error = ') Traceback (most recent call last): File "logfileparse.py", line 18, in epoch += line.split('Epoch = ') NameError: name 'epoch' is not defined Read the error carefully «epoch» undefined. to concatenate epoch, first epoch should be initialized. like epoch = [] or «» or anything you want
Why you are not using line.spli(‘ ‘) to create a list of all words then grab your interest parts using list indexing?
@Shahinism ok. I see ` ‘2014-05-09′, ’18:35:59,131’, ‘-‘, ‘root’, ‘-‘, ‘INFO’, ‘-‘, ‘Test’, ‘set’, ‘error’, ‘=’, ‘16.0433’` which are different values.
Sorry about my bad suggestion! as @iamsudip said your problem here is that you are not defined the variable epoch in your code! you can define it as a string just before your for loop like epoch=»» and I think every think will work just fine.
4 Answers 4
I guess you need to get a set of epoch and the test set errors together to plot them. Assuming the error line is always after the line with ‘epoch’, try this:
data_points = [] ep = 'Epoch = (\d+), batch = \d+, Classif Err = (\d+\.?\d+)' with open('file.txt') as f: for line in f: epoch = re.findall(ep, line) if epoch: error_line = next(f) # grab the next line, which is the error line error_value = error_line[error_line.rfind('=')+1:] data_points.append(map(float,epoch[0]+(error_value,))) Now data_points will be a list of lists, the first value is the epoch, the second the classif err value, and the third the error value.
The regular expression will return a list with a tuple:
Here i is your first line
To grab the error code, find the last = and then the error code is the remaining characters:
>>> i2 = '# 2014-05-09 17:51:53,749 - root - INFO - Test set error = 37.2317' >>> i2[i2.rfind('=')+1:] ' 37.2317' I used map(float,epoch[0]+(error_value,)) to convert the values from strings to floats:
>>> map(float, re.findall(ep, i)[0]+(i2[i2.rfind('=')+1:],)) [1.0, 52.926, 37.2317]