- Python Импорт данных №5. Импорт таблиц из PDF
- Решение
- Примененные функции
- Код
- Курс Импорт данных в Python
- How to Extract Data from PDF Files with Python
- How to Use PDFQuery
- Package installation
- Import the libraries
- Read and convert the PDF files
- Access and extract the Data
- Conclusion
- How to Extract Table from PDF with Python and Pandas
- 1: Extract tables from PDF with Python
- 2: Extract tables from PDF — keep format
- 2.1 Convert PDF to HTML
- 2.2 Extract tables with Pandas
- 2.3 HTMLTableParser
- 3. Python Libraries for extraction from PDF files
- 3.1 Python PDF parsing
- 3.2 Parse HTML tables
- 3.3 Example PDF files
Python Импорт данных №5. Импорт таблиц из PDF
Нам нужно импортировать таблицы определенного типа из множества PDF файлов и объединить их в одну таблицу по вертикали.
Дополнительная сложность в том, что PDF файлы содержат таблицы разного вида. Нам нужно отобрать только определенные.
Решение
Для решения нам понадобится 3 модуля: pandas, glob, tabula. Модуль tabula может извлекать таблицы из PDF файлов, glob создаст для нас список PDF файлов в папке, отфильтровав все остальные, а pandas почистит полученные таблицы.
Примененные функции
- glob.glob
- tabula.read_pdf
- display
- pandas.DataFrame
- pandas.concat
- pandas.to_datetime
- pandas.DataFrame.dropna
- pandas.Series.str.replace
- pandas.DataFrame.to_csv
- pandas.Series
- pandas.Series.repeat
- len
- pandas.DataFrame.append
- pandas.DataFrame.reset_index
- pandas.Series.rename
Код
Список всех PDF файлов в рабочей папке
pdf_files = glob.glob('*.pdf') pdf_files pdf_tables = tabula.read_pdf(pdf_files[1], pages='all', multiple_tables=True, lattice=True) Объединить таблицы одного PDF
df_single = pd.DataFrame() for table in pdf_tables: if table.columns[0] == 'Дата': df_single = pd.concat([df_single, table]) elif table.iloc[0,0] == 'Дата': table.columns = table.iloc[0] df_single = pd.concat([df_single, table]) else: continue Преобразовать тип данных столбца «Дата» в datetime.
df_single['Дата'] =pd.to_datetime(df_single['Дата'], format='%d.%m.%Y', errors='coerce') Удалить строки, где в столбце «Дата» значения null.
Курс Импорт данных в Python
| Номер урока | Урок | Описание |
|---|---|---|
| 1 | Python Импорт данных №1. Импорт Excel | Научимся импортировать данные из книг MS Excel в формате xlsx. |
| 2 | Python Импорт данных №2. Импорт CSV | Научимся импортировать данные из текстовых файлов CSV. |
| 3 | Python Импорт данных №3. Импорт с веб-сайта (HTML) | Импортируем таблицу с веб-страницы и запишем результат в CSV файл. |
| 4 | Python Импорт данных №4. Импорт таблиц XML | Научимся импортировать таблицы XML на примере данных с сайта Банка России. |
| 5 | Python Импорт данных №5. Импорт таблиц из PDF | Научимся импортировать нужные таблицы из PDF файлов, объединять их по вертикали в одну большую таблицу и записывать результат в CSV файл. |
| 6 | Python Импорт данных №6. Импорт таблиц из Word | Научимся импортировать таблицы из документов MS Word в формате docx. |
| 7 | Python Импорт данных №7. Импорт таблиц из Word | В этом уроке мы извлечем таблицу из документа Word и запишем ее в файл CSV. Для этого нам понадобится модули python-docx и pandas. |
How to Extract Data from PDF Files with Python

Shittu Olumide

Data is present in all areas of the modern digital world, and it takes many different forms.
One of the most common formats for data is PDF. Invoices, reports, and other forms are frequently stored in Portable Document Format (PDF) files by businesses and institutions.
It can be laborious and time-consuming to extract data from PDF files. Fortunately, for easy data extraction from PDF files, Python provides a variety of libraries.
This tutorial will explain how to extract data from PDF files using Python. You’ll learn how to install the necessary libraries and I’ll provide examples of how to do so.
There are several Python libraries you can use to read and extract data from PDF files. These include PDFMiner, PyPDF2, PDFQuery and PyMuPDF. Here, we will use PDFQuery to read and extract data from multiple PDF files.
How to Use PDFQuery
PDFQuery is a Python library that provides an easy way to extract data from PDF files by using CSS-like selectors to locate elements in the document.
It reads a PDF file as an object, converts the PDF object to an XML file, and accesses the desired information by its specific location inside of the PDF document.
Let’s consider a short example to see how it works.
from pdfquery import PDFQuery pdf = PDFQuery('example.pdf') pdf.load() # Use CSS-like selectors to locate the elements text_elements = pdf.pq('LTTextLineHorizontal') # Extract the text from the elements text = [t.text for t in text_elements] print(text) In this code, we first create a PDFQuery object by passing the filename of the PDF file we want to extract data from. We then load the document into the object by calling the load() method.
Next, we use CSS-like selectors to locate the text elements in the PDF document. The pq() method is used to locate the elements, which returns a PyQuery object that represents the selected elements.
Finally, we extract the text from the elements by accessing the text attribute of each element and we store the extracted text in a list called text .
Let’s consider another method we can use to read PDF files, extract some data elements, and create a structured dataset using PDFQuery. We will follow the following steps:
- Package installation.
- Import the libraries.
- Read and convert the PDF files.
- Access and extract the Data.
Package installation
First, we need to install PDFQuery and also install Pandas for some analysis and data presentation.
pip install pdfquery pip install pandas Import the libraries
import pandas as pd import pdfquery We import the two libraries to be be able to use them in our project.
Read and convert the PDF files
#read the PDF pdf = pdfquery.PDFQuery('customers.pdf') pdf.load() #convert the pdf to XML pdf.tree.write('customers.xml', pretty_print = True) pdf We will read the pdf file into our project as an element object and load it. Convert the pdf object into an Extensible Markup Language (XML) file. This file contains the data and the metadata of a given PDF page.
The XML defines a set of rules for encoding PDF in a format that is readable by humans and machines. Looking at the XML file using a text editor, we can see where the data we want to extract is.
Access and extract the Data
We can get the information we are trying to extract inside the LTTextBoxHorizontal tag, and we can see the metadata associated with it.
The values inside the text box, [68.0, 231.57, 101.990, 234.893] in the XML fragment refers to Left, Bottom, Right, Top coordinates of the text box. You can think of this as the boundaries around the data we want to extract.
Let’s access and extract the customer name using the coordinates of the text box.
# access the data using coordinates customer_name = pdf.pq('LTTextLineHorizontal:in_bbox("68.0, 231.57, 101.990, 234.893")').text() print(customer_name) #output: Brandon James Note: Sometimes the data we want to extract is not in the exact same location in every file which can cause issues. Fortunately, PDFQuery can also query tags that contain a given string.
Conclusion
Data extraction from PDF files is a crucial task because these files are frequently used for document storage and sharing.
Python’s PDFQuery is a potent tool for extracting data from PDF files. Anyone looking to extract data from PDF files will find PDFQuery to be a great option thanks to its simple syntax and comprehensive documentation. It is also open-source and can be modified to suit specific use cases.
Let’s connect on Twitter and on LinkedIn. You can also subscribe to my YouTube channel.
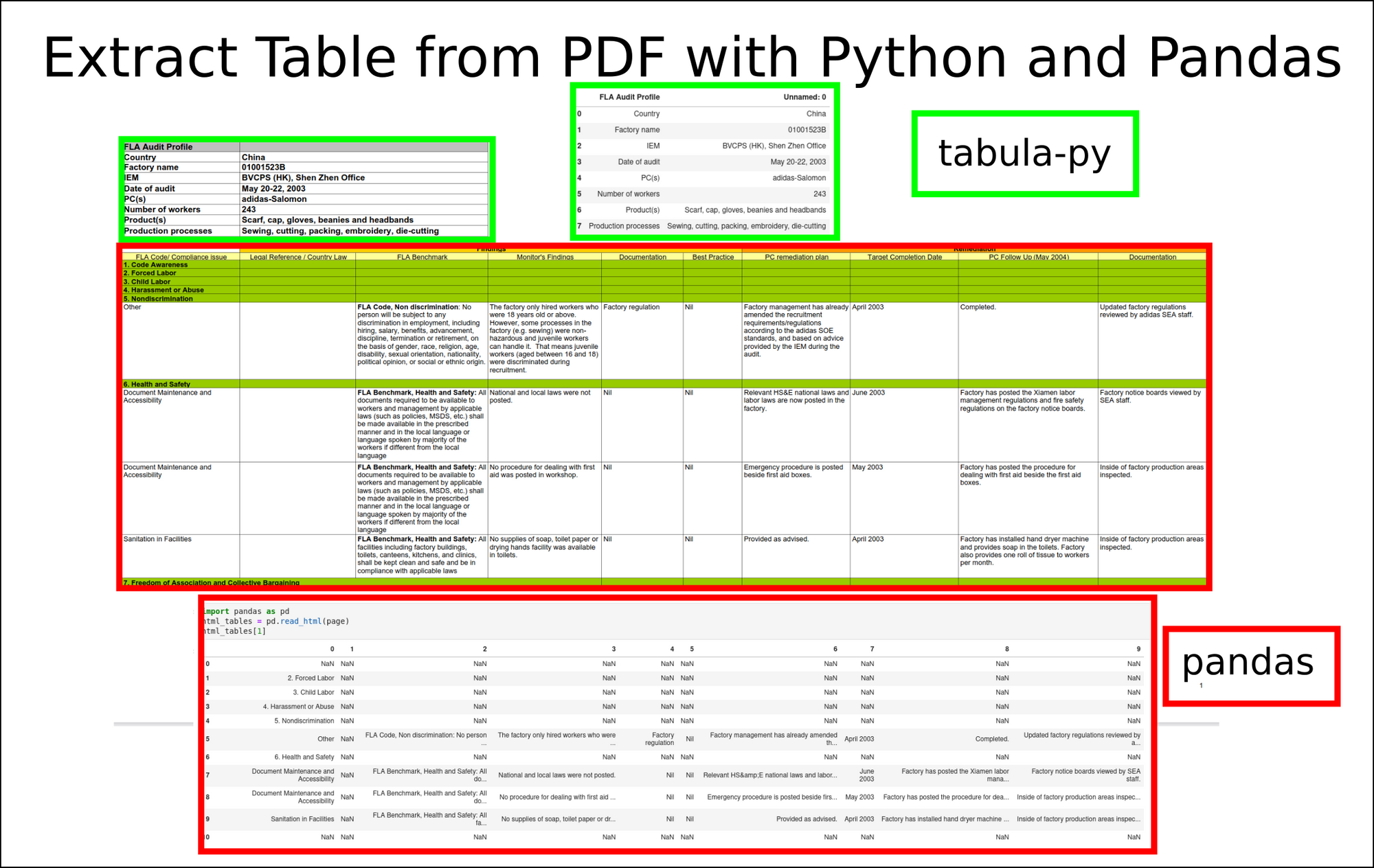
How to Extract Table from PDF with Python and Pandas
In this short tutorial, we’ll see how to extract tables from PDF files with Python and Pandas.
We will cover two cases of table extraction from PDF:
(1) Simple table with tabula-py
from tabula import read_pdf df_temp = read_pdf('china.pdf') (2) Table with merged cells
import pandas as pd html_tables = pd.read_html(page) Let’s cover both examples in more detail as context is important.
1: Extract tables from PDF with Python
In this example we will extract multiple tables from remote PDF file: china.pdf.
We will use library called: tabula-py which can be installed by:
The .pdf file contains 2 table:
from tabula import read_pdf file = 'https://raw.githubusercontent.com/tabulapdf/tabula-java/master/src/test/resources/technology/tabula/china.pdf' df_temp = read_pdf(file, stream=True) After reading the data we can get a list of DataFrames which contain table data.
| FLA Audit Profile | Unnamed: 0 | |
|---|---|---|
| 0 | Country | China |
| 1 | Factory name | 01001523B |
| 2 | IEM | BVCPS (HK), Shen Zhen Office |
| 3 | Date of audit | May 20-22, 2003 |
| 4 | PC(s) | adidas-Salomon |
| 5 | Number of workers | 243 |
| 6 | Product(s) | Scarf, cap, gloves, beanies and headbands |
| 7 | Production processes | Sewing, cutting, packing, embroidery, die-cutting |
Which is the exact match of the first table from the PDF file.
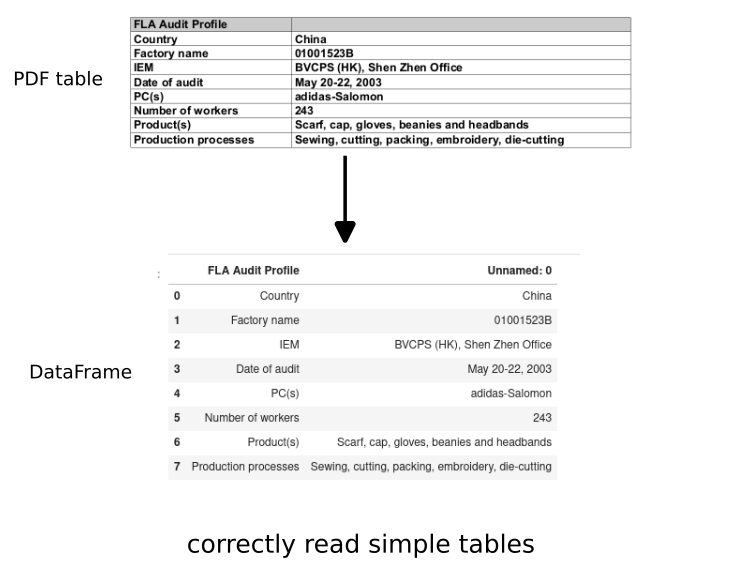
While the second one is a bit weird. The reason is because of the merged cells which are extracted as NaN values:
| Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Findings | Unnamed: 3 | |
|---|---|---|---|---|---|
| 0 | FLA Code/ Compliance issue | Legal Reference / Country Law | FLA Benchmark | Monitor’s Findings | NaN |
| 1 | 1. Code Awareness | NaN | NaN | NaN | NaN |
| 2 | 2. Forced Labor | NaN | NaN | NaN | NaN |
| 3 | 3. Child Labor | NaN | NaN | NaN | NaN |
| 4 | 4. Harassment or Abuse | NaN | NaN | NaN | NaN |
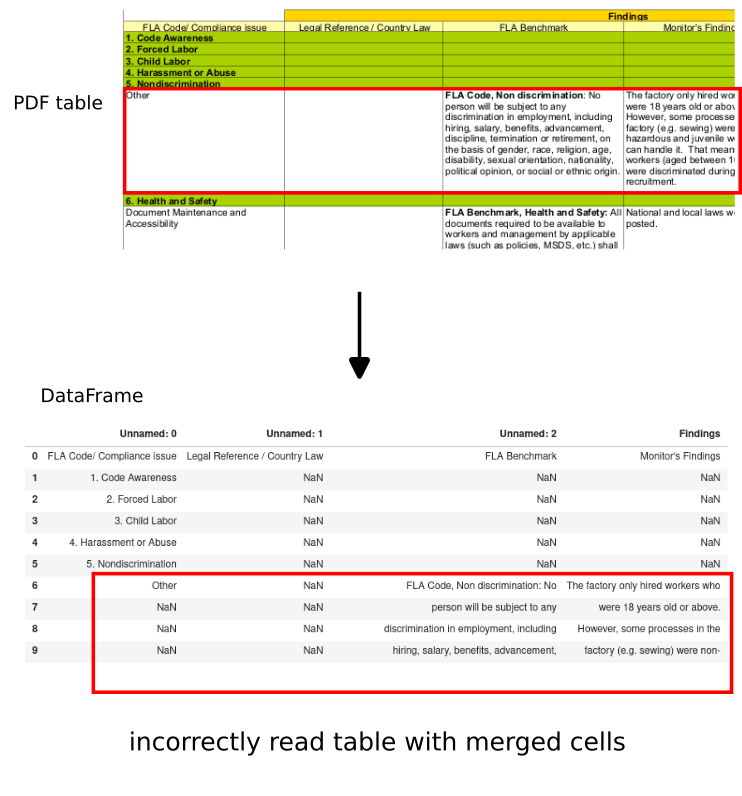
How to workaround this problem we will see in the next step.
Some cells are extracted to multiple rows as we can see from the image:
2: Extract tables from PDF — keep format
Often tables in PDF files have:
Most libraries and software are not able to extract them in a reliable way.
To extract complex table from PDF files with Python and Pandas we will do:
- download the file (it’s possible without download)
- convert the PDF file to HTML
- extract the tables with Pandas
2.1 Convert PDF to HTML
First we will download the file from: china.pdf.
Then we will convert it to HTML with the library: pdftotree.
import pdftotree page = pdftotree.parse('china.pdf', html_path=None, model_type=None, model_path=None, visualize=False) library can be installed by:
2.2 Extract tables with Pandas
Finally we can read all the tables from this page with Pandas:
import pandas as pd html_tables = pd.read_html(page) html_tables[1] Which will give us better results in comparison to tabula-py

2.3 HTMLTableParser
As alternatively to Pandas, we can use the library: html-table-parser-python3 to parse the HTML tables to Python lists.
from html_table_parser.parser import HTMLTableParser p = HTMLTableParser() p.feed(page) print(p.tables[0]) it convert the HTML table to Python list:
[['', ''], ['Country', 'China'], ['Factory name', '01001523B'], ['IEM', 'BVCPS (HK), Shen Zhen Office'], ['Date of audit', 'May 20-22, 2003'], ['PC(s)', 'adidas-Salomon'], ['Number of workers', '243'], ['Product(s)', 'Scarf, cap, gloves, beanies and headbands']] Now we can convert the list to Pandas DataFrame:
import pandas as pd pd.DataFrame(p.tables[1]) To install this library we can do:
pip install html-table-parser-python3 There are two differences to Pandas:
3. Python Libraries for extraction from PDF files
Finally let’s find a list of useful Python libraries which can help in PDF parsing and extraction:
3.1 Python PDF parsing
3.2 Parse HTML tables
- html-table-parser-python3 — parse HTML tables with Python 3 to list of values
- tablextract — extracts the information represented in any HTML table
- pdftotree — convert PDF into hOCR with text, tables, and figures being recognized and preserved.
- pandas.read_html
- html-table-extractor — A python library for extracting data from html table
- py-html-table — Python library to extract data from HTML Tables with rowspan
3.3 Example PDF files
Finally you can find example PDF files where you can test table extraction with Python and Pandas:
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.