Есть ли в PHP потоки
Я нашел пакет PECL под названием thread , для управления потоками в PHP. Как правильно управлять потоками в PHP?
Ответ 1
Насколько я знаю, ничего доступного нет. Лучшим вариантом было бы просто заставить один скрипт выполнять другой через CLI, но это немного примитивно. В зависимости от того, что вы пытаетесь сделать и насколько это сложно, существует множество вариантов.
Ответ 2
- Хэш-таблица хранилища объектов, в которой хранятся данные, безопасные для потоков, основана на хэш-таблице TsHashTable, поставляемой в PHP и Zend.
- Хранилище объектов имеет блокировку на чтение и запись, дополнительная блокировка доступа предусмотрена для TsHashTable, так что если потребуется (а это так, var_dump/print_r, прямой доступ к свойствам, так как движок PHP хочет ссылаться на них), потоки могут манипулировать TsHashTable за пределами определенного API.
- Блокировки удерживаются , только пока происходят операции копирования ; когда копии сделаны, блокировки освобождаютс я в определенном порядке.
- Когда происходит запись, удерживается не только блокировка чтения и записи, но и дополнительная блокировка доступа. Сама таблица заблокирована, нет никакой возможности, чтобы другой контекст мог заблокировать, прочитать, записать или повлиять на нее.
- Когда происходит чтение, удерживается не только блокировка чтения, но и дополнительная блокировка доступа, и снова таблица блокируется.
Ответ 3
- Поток — это последовательность команд, которые процессор будет обрабатывать. Единственные данные, из которых он состоит, – это счетчик программы. Каждое ядро процессора одновременно обрабатывает только один поток, но может переключаться между выполнением разных потоков с помощью планирования.
- Процесс — это набор совместно используемых ресурсов. Это означает, что он состоит из части памяти, переменных, экземпляров объектов, хэндлов файлов, мьютексов, соединений с базами данных и так далее. Каждый процесс также содержит один или несколько потоков. Все потоки одного процесса совместно используют его ресурсы, поэтому вы можете использовать в одном потоке переменную, которую создали в другом. Если эти потоки являются частью двух разных процессов, то они не могут получить прямой доступ к ресурсам друг друга. В этом случае вам необходимо межпроцессное взаимодействие, например, через каналы, файлы, сокеты .
- Для linux вы можете использовать следующее:
- Для windows вы можете использовать следующее:
- Сначала вам нужна потокобезопасная версия php.
- Вам нужны предварительно скомпилированные версии как pthreads, так и его расширения php. Убедитесь, что вы скачали версию, совместимую с вашей версией php.
- Скопируйте php_pthreads.dll (из zip-архива) в папку расширения php ([phpDirectory]/ext).
- Скопируйте pthreadVC2.dll в [phpDirectory] (корневую папку — не папку расширений).
- Отредактируйте [phpDirectory]/php.ini и вставьте следующую строку
- Протестируйте его с помощью скрипта выше с некоторым sleep или чем-то еще прямо там, где комментарий.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Потоки выполнения и PHP

PHP и потоки выполнения (threads). Предложение всего лишь из четырёх слов, а по этой теме можно написать книгу. Как обычно, я не буду так делать, зато дам вам информацию, чтобы вы стали разбираться в предмете до определённой степени.
Начнём с путаницы, которая есть в головах у некоторых программистов. PHP — это не многопоточный язык. Внутри самого PHP не используются потоки выполнения, и PHP не даёт возможности пользовательскому коду нативно использовать их в качестве механизма параллелизации.
PHP очень далёк от других технологий. Например, в Java очень активно используются потоки выполнения, ещё они могут встречаться в пользовательских программах. В PHP такого нет. И тому есть причины.
Движок PHP обходится без потоков выполнения в основном ради упрощения структуры. Прочитав следующий раздел, вы узнаете, что потоки выполнения — не «магическая технология, позволяющая ускорить работу любой программы». Похоже на речь продавца, правда? Но мы не торговцы — мы технари, и мы знаем, о чём говорим. В настоящий момент в движке PHP нет потоков выполнения. Возможно, в будущем они появятся. Но это повлечёт за собой столько сложностей, что результат может оказаться далёк от ожидаемого. Главная трудность — кроссплатформенное многопоточное программирование (thread programming). Вторая трудность — общие ресурсы (shared resources) и управление блокировками. Третья — потоки выполнения подходят не для каждой программы. Архитектура PHP зародилась в районе 2000 года, а в то время потоковое программирование было малораспространённым и незрелым. Поэтому авторы PHP (преимущественно движка Zend) решили сделать цельный движок без потоков. Да и не было у них нужных ресурсов для создания стабильного кроссплатформенного многопоточного движка.
Кроме того, потоки выполнения невозможно применять в пользовательском пространстве PHP. Этот язык не так выполняет код. Концепция PHP — «выстрелил и забыл». Запрос должен обрабатываться как можно быстрее, чтобы освободить PHP для следующего запроса. PHP создан как связующий язык: вы не обрабатываете сложные задачи, требующие потоков. Вместо этого обращаетесь к fast-and-ready ресурсам, связываете всё воедино и отправляете обратно пользователю. PHP — язык действия, а если что-то требует на обработку «больше времени, чем обычно», то это нужно делать не в PHP. Поэтому для асинхронной обработки каких-то тяжёлых задач используется система на базе очередей (Gearman, AMQP, ActiveMQ и т. д.). В Unix принято делать так: «Разрабатывай маленькие, самодостаточные инструменты и связывай их друг с другом». PHP не рассчитан на активное распараллеливание, это удел других технологий. Каждой проблеме — правильный инструмент.
Несколько слов о потоках выполнения
Освежим в памяти, что такое потоки выполнения. Не будем углубляться в подробности, их вы найдёте в интернете и книгах.
Поток выполнения — «малая» единица обработки (light unit of work treatment), находящаяся внутри процесса. Процесс может создавать многочисленные потоки выполнения. Поток должен быть частью только одного процесса. Процесс — «большая» единица обработки в рамках операционной системы. На многоядерных (многопроцессорных) компьютерах несколько ядер (процессоров) работают параллельно и обрабатывают часть нагрузки исполняемых задач. Если процессы А и Б готовы к постановке в очередь и два ядра (процессора) готовы к работе, то А и Б должны быть одновременно отправлены в обработку. Тогда компьютер эффективно обрабатывает несколько задач в единицу времени (временной интервал, timeframe). Мы называем это «параллелизм».

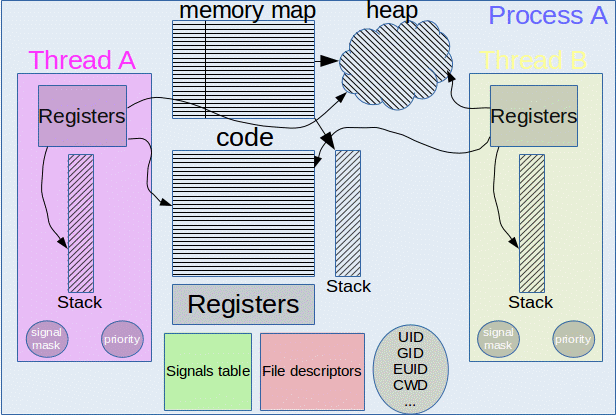
Раньше A и Б были процессами: полностью независимыми обработчиками. Но потоки выполнения — это не процессы. Потоки — это единицы, живущие внутри процессов. То есть процесс может распределить работу по нескольким более мелким задачам, выполняемым одновременно. К примеру, процессы А и Б могут породить потоки А1, А2, Б1 и Б2. Если компьютер оснащён несколькими процессорами, например восемью, то все четыре потока могут выполняться в одном временном интервале (timeframe).
Потоки выполнения — это способ разделения работы процесса на несколько мелких подзадач, решаемых параллельно (в одном временном интервале). Причём потоки выполняются примерно так же, как и процессы: диспетчер программного потока ядра (Kernel thread scheduler) управляет потоками с помощью состояний.

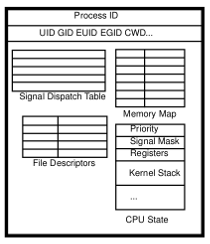
Потоки выполнения легче процессов, им для работы нужен лишь стек и несколько регистров. А процессам требуется много всего: новый кадр виртуальной машины (VM frame) от ядра, куча, разная сигнальная информация, информация о файловых дескрипторах, блокировках и т. д.
Память процесса управляется на аппаратном уровне ядром и MMU, а память потока выполнения — на программном уровне программистом и потоковыми библиотеками (threading library).
Так что запомните: потоки выполнения легче процессов и проще управляются. При грамотном использовании они ещё и работают быстрее процессов, поскольку ядро ОС почти не вмешивается в управление потоками и их диспетчеризацию.
Схема памяти потоков выполнения
У потоков выполнения есть свой стек. Поэтому при обращении к переменным, объявленным в функциях, они получают собственную копию этих данных.
Куча процесса совместно используется потоками выполнения, как и глобальные переменные, и файловые дескрипторы. Это и преимущество, и недостаток. Если мы только считываем из глобальной памяти, то нужно это делать вовремя. Например, после потока Х и до потока Y. Если мы пишем в глобальную память, то стоит удостовериться, что туда же и в то же время не попытаются записать несколько потоков. Иначе эта область памяти окажется в непредсказуемом состоянии — так называемом состоянии гонки (race condition). Это главная проблема в потоковом программировании.
На случай одновременного доступа вам нужно внедрить в код некоторые механизмы вроде повторного входа (reentrancy) или подпрограмм синхронизации (synchronization routine). Повторный вход нарушает согласованность (concurrency). А синхронизация позволяет управлять согласованностью предсказуемым образом.
Процессы не используют память совместно, они идеально изолированы на уровне ОС. А потоки выполнения внутри одного процесса совместно используют большой объём памяти.
Поэтому им нужны инструменты синхронизации доступа к общей памяти, например семафоры и мьютексы (mutexes). Работа этих инструментов основана на принципе «блокировки»: если ресурс заблокирован, а поток пытается получить к нему доступ, то по умолчанию поток будет ожидать разблокировки ресурса. Поэтому потоки выполнения сами по себе не сделают вашу программу быстрее. Без эффективного распределения задач по потокам и управления блокировками общей памяти ваша программа станет работать ещё медленнее, чем при использовании одного процесса без потоков выполнения. Просто потоки будут постоянно ожидать друг друга (и я ещё не говорю о взаимоблокировках, голодании и т. д.).
Если у вас нет опыта в потоковом программировании, то оно окажется для вас непростым занятием. Чтобы наработать опыт работы с потоками выполнения, понадобится много часов практики и решения WTF-моментов. Стоит забыть о какой-то мелочи — и вся программа пойдёт в разнос. Труднее отлаживать программу с потоками, чем без них, если мы говорим о реальных проектах с сотнями или тысячами потоков в одном процессе. Вы сойдёте с ума и просто утонете во всём этом.
Потоковое программирование — трудная задача. Чтобы стать мастером, нужно потратить массу времени и сил.
Такая схема совместного использования памяти потоками не всегда удобна. Поэтому появилось локальное хранилище потока (Thread Local Storage, TLS). TLS можно описать как «глобалы, принадлежащие какому-то одному потоку и не используемые другими». Это области памяти, отражающие глобальное состояние, приватные для конкретного потока выполнения (как в случае использования одних лишь процессов). При создании потока выделяется часть кучи процесса — хранилище. У потоковой библиотеки запрашивается ключ, который ассоциируется с этим хранилищем. Он должен использоваться потоком выполнения при каждом обращении к своему хранилищу. Для уничтожения выделенных ресурсов в конце жизни потока требуется деструктор.
Приложение «потокобезопасно» (thread safe), если каждое обращение к глобальным ресурсам находится под полным контролем и полностью предсказуемо. В противном случае вам перейдёт дорогу диспетчер (scheduler): будут неожиданно выполняться какие-то задачи, и производительность упадёт.
Потоковые библиотеки
Потокам выполнения нужна помощь ядра ОС. В операционных системах потоки выполнения появились в середине 1990-х, так что методики работы с ними отшлифованы.
Но существуют проблемы кроссплатформенности. Особенно много различий между Windows- и Unix-системами. В этих экосистемах приняты разные модели потокового выполнения и используются разные потоковые библиотеки.
В Linux для создания потока или процесса ядро осуществляет системный вызов clone(). Но он невероятно сложен, поэтому для облегчения повседневного потокового программирования системные вызовы используют код на Си. Libc до сих пор не управляет потоковыми операциями (подобную инициативу демонстрирует стандартная библиотека из С11), этим занимаются внешние библиотеки. Сегодня в Unix-системах обычно применяется pthread (есть и другие библиотеки). Pthread — сокращение от Posix threads. Эта POSIX-нормализация использования потоков и их поведения берёт своё начало в 1995-м. Если вам нужны потоки выполнения, подключите библиотеку libpthread: передайте в GCC -lpthread. Она написана на С, её код открыт, есть собственный механизм контроля и управления версиями.
Итак, в Unix-системах чаще всего используется библиотека pthread. Она обеспечивает согласованность (concurrency), а параллелизм зависит от конкретной ОС и компьютера.
Согласованность — это когда несколько потоков беспорядочно выполняются на одном процессоре. Параллелизм — это когда несколько потоков одновременно выполняются на разных процессорах.