- A Complete Guide to Confidence Interval, and Examples in Python
- Deep Understanding of Confidence Interval and Its Calculation, a Very Popular Parameter in Statistics
- Confidence Interval
- Как рассчитать доверительные интервалы в Python
- Доверительные интервалы с использованием t-распределения
- Доверительные интервалы с использованием нормального распределения
- Как интерпретировать доверительные интервалы
- Использование функций scipy.stats. Доверительные интервалы.
- Оценка математического ожидания нормального распределения при известном \(\sigma\)
- Оценка математического ожидания нормального распределения при неизвестном \(\sigma\)
- Список использованных источников
- Как построить доверительный интервал в Python
- Построение доверительных интервалов с использованием lineplot()
- Построение доверительных интервалов с использованием regplot()
A Complete Guide to Confidence Interval, and Examples in Python
Deep Understanding of Confidence Interval and Its Calculation, a Very Popular Parameter in Statistics
Confidence Interval (CI) is essential in statistics and very important for data scientists. In this article, I will explain it thoroughly with necessary formulas and also demonstrate how to calculate it using python.
Confidence Interval
As it sounds, the confidence interval is a range of values. In the ideal condition, it should contain the best estimate of a statistical parameter. It is expressed as a percentage. 95% confidence interval is the most common. You can use other values like 97%, 90%, 75%, or even 99% confidence interval if your research demands. Let’s understand it by an example:
“In a sample of 659 parents with toddlers, about 85%, stated they use a car seat for all travel with their toddler. From these results, a 95% confidence interval was provided, going from about 82.3% up to 87.7%.”
This statement means, we are 95% certain that the population proportion who use a car seat for all travel with their toddler will fall between 82.3% and 87.7%. If we take a different sample or a subsample of these 659 people, 95% of the time, the percentage of the population who use a car seat in all travel with their toddlers will be in between 82.3% and 87.7%.
Remember, 95% confidence interval does not mean 95% probability
The reason confidence interval is so popular and useful is, we cannot take data from all populations. Like the example above, we could not get the information from all the parents with toddlers. We had to calculate the result from 659 parents. From that result, we tried to get an estimate of the overall population. So, it is reasonable to consider a margin of error and take a range. That’s why we take a confidence interval which is a range.
We want a simple random sample and a normal distribution to construct a confidence interval. But if the sample size is large enough (30 or more) normal distribution is not necessary.
Как рассчитать доверительные интервалы в Python
Доверительный интервал для среднего значения — это диапазон значений, который может содержать среднее значение генеральной совокупности с определенным уровнем достоверности.
Доверительный интервал = x +/- t*(s/√n)
- x : выборочное среднее
- t: t-значение, соответствующее доверительному уровню
- s: стандартное отклонение выборки
- n: размер выборки
В этом руководстве объясняется, как рассчитать доверительные интервалы в Python.
Доверительные интервалы с использованием t-распределения
В следующем примере показано, как рассчитать доверительный интервал для истинной средней высоты популяции (в дюймах) определенного вида растений, используя выборку из 15 растений:
import numpy as np import scipy.stats as st #define sample data data = [12, 12, 13, 13, 15, 16, 17, 22, 23, 25, 26, 27, 28, 28, 29] #create 95% confidence interval for population mean weight st.t.interval(alpha=0.95, df=len(data)-1, loc=np.mean(data), scale=st.sem(data)) (16.758, 24.042) 95% доверительный интервал для истинного среднего роста населения составляет (16,758, 24,042) .
Вы заметите, что чем выше уровень достоверности, тем шире доверительный интервал. Например, вот как рассчитать 99% ДИ для тех же самых данных:
#create 99% confidence interval for same sample st.t.interval(alpha= 0.99 , df=len(data)-1, loc=np.mean(data), scale=st.sem(data)) (15.348, 25.455) 99% доверительный интервал для истинного среднего роста населения составляет (15,348, 25,455).Обратите внимание, что этот интервал шире, чем предыдущий 95% доверительный интервал.
Доверительные интервалы с использованием нормального распределения
Если мы работаем с большими выборками (n≥30), мы можем предположить, что выборочное распределение выборочного среднего нормально распределено (благодаря центральной предельной теореме ), и вместо этого можем использовать функцию norm.interval() из scipy библиотека .stats.
В следующем примере показано, как рассчитать доверительный интервал для истинной средней высоты популяции (в дюймах) определенного вида растений, используя выборку из 50 растений:
import numpy as np import scipy.stats as st #define sample data np.random.seed(0) data = np.random.randint(10, 30, 50) #create 95% confidence interval for population mean weight st.norm.interval(alpha=0.95, loc=np.mean(data), scale=st.sem(data)) (17.40, 21.08) 95% доверительный интервал для истинного среднего роста населения составляет (17,40, 21,08) .
Как и в случае с t-распределением, более высокие уровни достоверности приводят к более широким доверительным интервалам. Например, вот как рассчитать 99% ДИ для тех же самых данных:
#create 99% confidence interval for same sample st.norm.interval(alpha= 0.99 , loc=np.mean(data), scale=st.sem(data)) (16.82, 21.66) 95% доверительный интервал для истинного среднего роста населения составляет (17,82, 21,66) .
Как интерпретировать доверительные интервалы
Предположим, что наш 95-процентный доверительный интервал для истинной средней высоты популяции вида растения составляет:
95% доверительный интервал = (16,758, 24,042)
Способ интерпретации этого доверительного интервала следующий:
Существует вероятность 95%, что доверительный интервал [16,758, 24,042] содержит истинную среднюю высоту растений.
Другой способ сказать то же самое состоит в том, что существует только 5%-ная вероятность того, что истинное среднее значение генеральной совокупности лежит за пределами 95%-го доверительного интервала. То есть существует только 5% вероятность того, что истинная средняя высота растений в популяции меньше 16,758 дюйма или больше 24,042 дюйма.
Использование функций scipy.stats. Доверительные интервалы.
В математической статистике интервальной оценкой называется результат использования выборки для вычисления интервала возможных значений неизвестного параметра, оценку которого нужно построить. Следует отличать от точечной оценки, которая даёт лишь одно значение. Самым распространенным видом интервальных оценок являются доверительные интервалы.
Доверительная вероятность — вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра, оцениваемого по выборочным данным.
Оценка математического ожидания нормального распределения при известном \(\sigma\)
Количественный признак генеральной совокупности X распределен нормально и известно среднеквадратическое отклонение этого распределения. Из генеральной совокупности формируется выборка, по которой определяется математическое ожидание выборки \(\hat\).
Необходимо найти доверительный интервал \([\hat-d, \hat+d]\), который покрывает неизвестное математическое ожидание \(a\) генеральной совокупности с надежностью или доверительной вероятностью \(\gamma\): \(P(|\hat-a| Математическое ожидание выборки \(\hat\) рассматривается как нормально-распределенная случайная величина с математическим ожиданием \(\hat\) и стандартным отклонением \(\sigma/\sqrt\). Если стандартное отклонение генеральной совокупности неизвестно, то для определения доверительного интервала используется распределение Стьюдента: \[P(\hat-t_\gamma s/\sqrt < a < \hat+t_\gamma s/\sqrt) = 2 \int_^ где \(s\) — “исправленное” среднеквадратичное отклонение выборки, \(S(t,n)\) — плотность распределения Стьюдента. При больших выборках (n>30) распределение Стьюдента стремится к нормальному и для оценки доверительного интервала может использоваться нормальное распределение. При малых выборках нормальное распределение будет давать более узкий (т.е. слишком оптимистичный) интервал, в отличие от распределения Стьюдента. Доверительный интервал — это диапазон значений, который может содержать параметр генеральной совокупности с определенным уровнем достоверности. В этом руководстве объясняется, как построить доверительный интервал для набора данных в Python с помощью библиотеки визуализации Seaborn . Первый способ построить доверительный интервал — использоватьфункцию lineplot() , которая соединяет все точки данных в наборе данных линией и отображает доверительный интервал вокруг каждой точки: По умолчанию функция lineplot() использует доверительный интервал 95%, но может указать уровень достоверности для использования с командой ci . Чем меньше уровень достоверности, тем более узким будет доверительный интервал вокруг линии. Например, вот как выглядит доверительный интервал 80% для точно такого же набора данных: Вы также можете построить доверительные интервалы с помощью функции regplot() , которая отображает диаграмму рассеяния набора данных с доверительными диапазонами вокруг оценочной линии регрессии: Подобно функции lineplot(), функция regplot() по умолчанию использует доверительный интервал 95%, но может указать уровень достоверности для использования с командой ci . Опять же, чем меньше уровень достоверности, тем более узким будет доверительный интервал вокруг линии регрессии. Например, вот как выглядит доверительный интервал 80% для точно такого же набора данных:# Стандартное отклонение генеральной совокупности sigma = 0.8 # Математическое ожидание генеральной совокупности mean = 4.1 # Формируем выборку из генеральной совокупности # Объем выборки n = 30 # Выборка data = np.random.normal(loc=mean, scale=sigma, size=n) # Надежность оценки (доверительная вероятность) gamma = 0.95 # Оценка математического ожидания выборки mean_of_sample = np.mean(data) # Стандартное отклонение выборочной средней sigma_of_mean = scipy.stats.sem(data)
interval = scipy.stats.norm.interval(gamma, loc = mean_of_sample, scale = sigma_of_mean) print('Математическое ожидание принадлежит интервалу [; ]'.format(interval[0],interval[1])) Математическое ожидание принадлежит интервалу [3.89; 4.47] Оценка математического ожидания нормального распределения при неизвестном \(\sigma\)
# Надежность оценки gamma = 0.95 # Оценка математического ожидания mean_of_sample = np.mean(data) # Стандартное отклонение выборочной средней совокупности sigma_of_mean = scipy.stats.sem(data)
# Доверительный интервал математического ожидания interval = scipy.stats.t.interval(gamma, df = n-1, loc = mean_of_sample, scale = sigma_of_mean) print(interval) (3.8810695725888413, 4.482390285924866) # Очень маленькая выборка n = 5 data = np.random.normal(loc=mean, scale=sigma, size=n) # Оценка математического ожидания mean_of_sample = np.mean(data) # Стандартное отклонение выборочной средней совокупности sigma_of_mean = scipy.stats.sem(data) # Доверительный интервал математического ожидания с использованием распределения Стьюдента interval = scipy.stats.t.interval(gamma, df = n-1, loc = mean_of_sample, scale = sigma_of_mean) print('Интервал по распределению Стьюдента [; ]'.format(interval[0],interval[1])) # Доверительный интервал математического ожидания с использованием нормального распределения interval = scipy.stats.norm.interval(gamma, loc = mean_of_sample, scale = sigma_of_mean) print('Интервал по нормальному распределению [; ]'.format(interval[0],interval[1])) Интервал по распределению Стьюдента [3.000; 4.419] Интервал по нормальному распределению [3.209; 4.210] Список использованных источников
Как построить доверительный интервал в Python
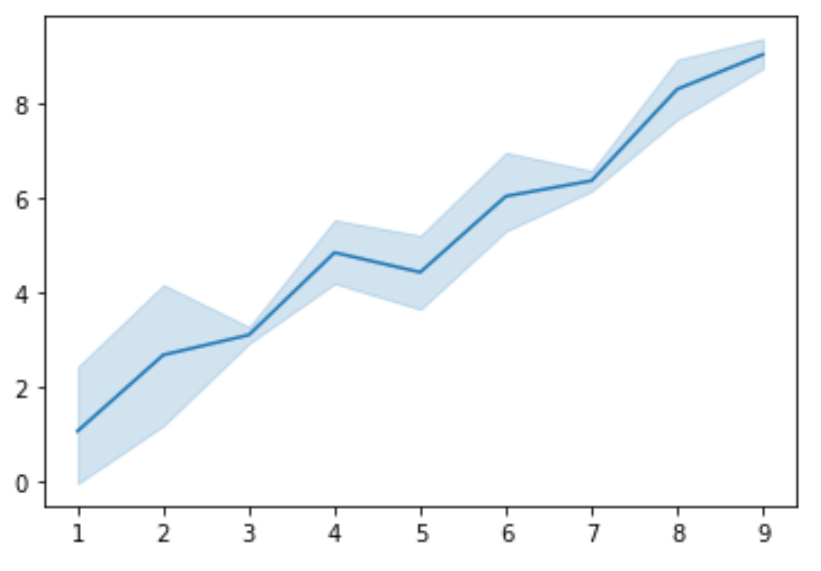
Построение доверительных интервалов с использованием lineplot()
import numpy as np import seaborn as sns import matplotlib.pyplot as plt #create some random data np.random.seed(0) x = np.random.randint(1, 10, 30) y = x+np.random.normal(0, 1, 30) #create lineplot ax = sns.lineplot(x, y) 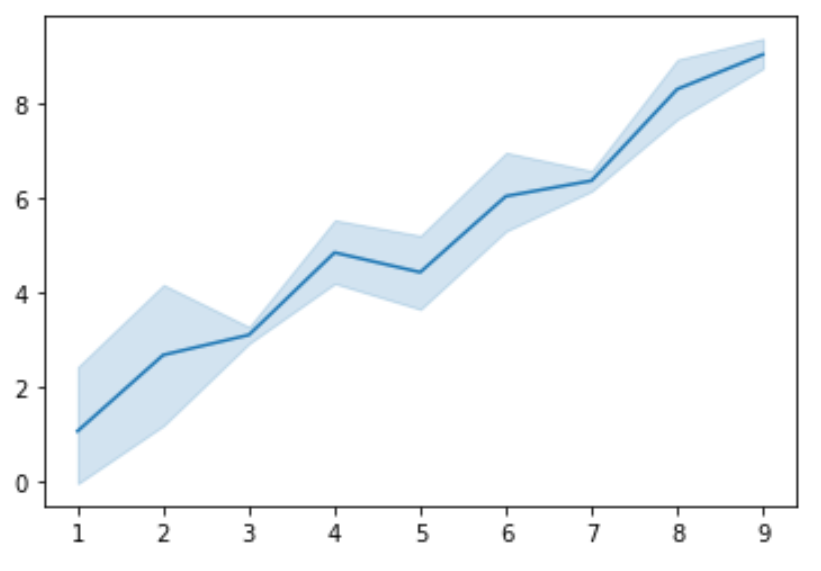
#create lineplot ax = sns.lineplot(x, y, ci= 80 ) 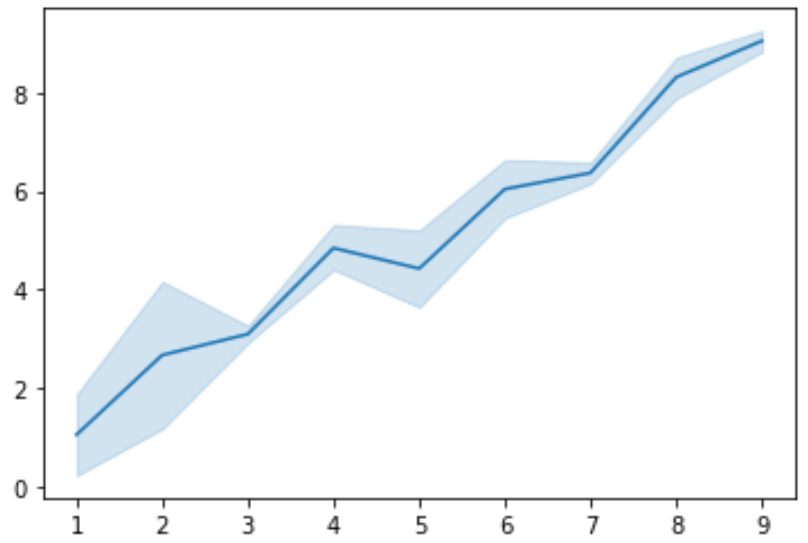
Построение доверительных интервалов с использованием regplot()
import numpy as np import seaborn as sns import matplotlib.pyplot as plt #create some random data np.random.seed(0) x = np.random.randint(1, 10, 30) y = x+np.random.normal(0, 1, 30) #create regplot ax = sns.regplot(x, y) 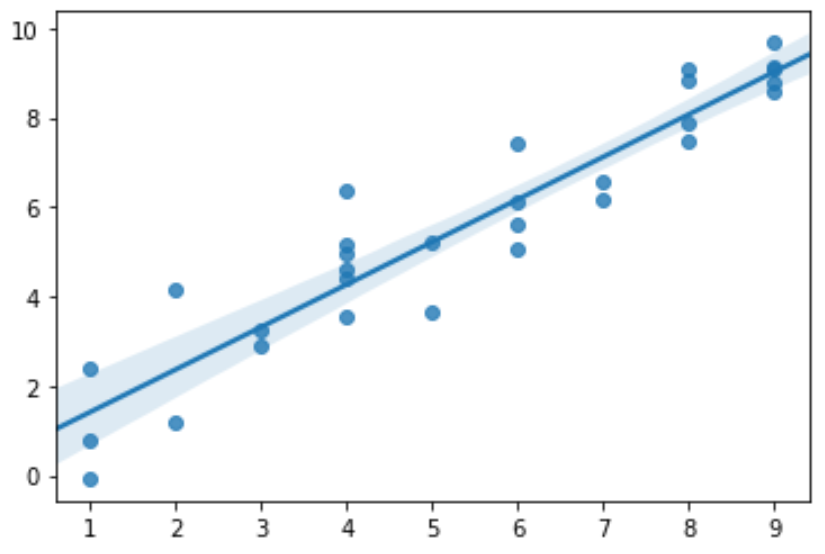
#create regplot ax = sns.regplot(x, y, ci= 80 )