- Rukovodstvo
- статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
- Классификация в Python с помощью Scikit-Learn и Pandas
- Введение Классификация — это обширная область статистики и машинного обучения. Как правило, классификацию можно разбить на две области: 1. Бинарная классификация, где мы хотим сгруппировать результат в одну из двух групп. 2. Классификация по нескольким классам, где мы хотим сгруппировать результат в одну из нескольких (более двух) групп. В этом посте основное внимание будет уделено использованию различных алгоритмов классификации в обоих этих доменах.
- Вступление
- Бинарная классификация
- Логистическая регрессия
- Машины опорных векторов
- Случайные леса
- Нейронные сети
- Мультиклассовая классификация
- Заключение
- Обзор методов классификации в машинном обучении с помощью Scikit-Learn
- Что такое Scikit-Learn?
- Основные термины
- Типы классификаторов
Rukovodstvo
статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
Классификация в Python с помощью Scikit-Learn и Pandas
Введение Классификация — это обширная область статистики и машинного обучения. Как правило, классификацию можно разбить на две области: 1. Бинарная классификация, где мы хотим сгруппировать результат в одну из двух групп. 2. Классификация по нескольким классам, где мы хотим сгруппировать результат в одну из нескольких (более двух) групп. В этом посте основное внимание будет уделено использованию различных алгоритмов классификации в обоих этих доменах.
Вступление
Классификация — это обширная область статистики и машинного обучения. Как правило, классификацию можно разделить на две области:
- Бинарная классификация , в которой мы хотим сгруппировать результат в одну из двух групп.
- Классификация по нескольким классам , где мы хотим сгруппировать результат в одну из нескольких (более двух) групп.
В этом посте основное внимание будет уделено использованию различных алгоритмов классификации в обеих этих областях, меньше внимания будет уделяться теории, лежащей в основе них.
Мы можем использовать библиотеки в Python, такие как scikit-learn для моделей машинного обучения и Pandas для импорта данных в виде фреймов данных.
Их можно легко установить и импортировать в Python с помощью pip :
$ python3 -m pip install sklearn $ python3 -m pip install pandas import sklearn as sk import pandas as pd Бинарная классификация
Для двоичной классификации нас интересует классификация данных в одну из двух двоичных групп — они обычно представлены в наших данных как 0 и 1.
Мы рассмотрим данные по ишемической болезни сердца (ИБС) в Южной Африке. Цель состоит в том, чтобы использовать различные переменные, такие как употребление табака , семейный анамнез , уровень холестерина ЛПН , употребление алкоголя , ожирение и многое другое.
Полное описание этого набора данных доступно в разделе «Данные» на веб-сайте Elements of Statistical Learning.
Приведенный ниже код считывает данные во фрейм данных Pandas, а затем разделяет фрейм данных на y вектор ответа и X матрицу независимых переменных:
import pandas as pd import os os.chdir('/Users/stevenhurwitt/Documents/Blog/Classification') heart = pd.read_csv('SAHeart.csv', sep=',', header=0) heart.head() y = heart.iloc[:,9] X = heart.iloc[. 9] При запуске этого кода просто не забудьте изменить путь к файловой системе в строке 4 в соответствии с вашими настройками.
sbp табак ldl ожирение фамхист наберите \"А ожирение алкоголь возраст chd 0 160 12.00 5,73 23.11 1 49 25.30 97,20 52 1 1 144 0,01 4,41 28,61 0 55 28,87 2,06 63 1 2 118 0,08 3,48 32,28 1 52 29,14 3,81 46 0 3 170 7,50 6,41 38,03 1 51 31,99 24,26 58 1 4 134 13,60 3,50 27,78 1 60 25,99 57,34 49 1
Логистическая регрессия
Логистическая регрессия — это тип обобщенной линейной модели (GLM), которая использует логистическую функцию для моделирования двоичной переменной на основе любых независимых переменных.
Чтобы соответствовать бинарной логистической регрессии с помощью sklearn , мы используем модуль LogisticRegression multi_class установленным на «ovr» и подходящим для X и y .
Затем мы можем использовать predict для прогнозирования вероятностей новых данных, а также score для получения средней точности прогноза:
import sklearn as sk from sklearn.linear_model import LogisticRegression import pandas as pd import os os.chdir('/Users/stevenhurwitt/Documents/Blog/Classification') heart = pd.read_csv('SAHeart.csv', sep=',',header=0) heart.head() y = heart.iloc[:,9] X = heart.iloc[. 9] LR = LogisticRegression(random_state=0, solver='lbfgs', multi_class='ovr').fit(X, y) LR.predict(X.iloc[460. ]) round(LR.score(X,y), 4) array([1, 1]) Машины опорных векторов
Машины опорных векторов (SVM) представляют собой более гибкий тип алгоритмов классификации — они могут выполнять линейную классификацию, но могут использовать другие нелинейные базисные функции . В следующем примере используется линейный классификатор для соответствия гиперплоскости, разделяющей данные на два класса:
import sklearn as sk from sklearn import svm import pandas as pd import os os.chdir('/Users/stevenhurwitt/Documents/Blog/Classification') heart = pd.read_csv('SAHeart.csv', sep=',',header=0) y = heart.iloc[:,9] X = heart.iloc[. 9] SVM = svm.LinearSVC() SVM.fit(X, y) SVM.predict(X.iloc[460. ]) round(SVM.score(X,y), 4) array([0, 1]) Случайные леса
- это метод ансамблевого обучения, который подбирает несколько деревьев решений по подмножествам данных и усредняет результаты. Мы снова можем подогнать их с помощью sklearn и использовать их для прогнозирования результатов, а также для получения средней точности прогноза: import sklearn as sk from sklearn.ensemble import RandomForestClassifier RF = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0) RF.fit(X, y) RF.predict(X.iloc[460. ]) round(RF.score(X,y), 4) 0.7338
Нейронные сети
Нейронные сети — это алгоритм машинного обучения, который включает подгонку множества скрытых слоев, используемых для представления нейронов, связанных с функциями синаптической активации. По сути, они используют очень упрощенную модель мозга для моделирования и прогнозирования данных.
Мы используем sklearn для обеспечения согласованности в этой должности, однако библиотеки , такие как Tensorflow и Keras более подходит для установки и настройки нейронных сетей, из которых Есть несколько сортов , используемых для различных целей:
import sklearn as sk from sklearn.neural_network import MLPClassifier NN = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5, 2), random_state=1) NN.fit(X, y) NN.predict(X.iloc[460. ]) round(NN.score(X,y), 4) 0.6537 Мультиклассовая классификация
Хотя сама по себе двоичная классификация невероятно полезна, бывают случаи, когда нам нужно моделировать и прогнозировать данные, которые имеют более двух классов. Многие из тех же алгоритмов можно использовать с небольшими изменениями.
Кроме того, данные обычно разделяют на обучающие и тестовые наборы. Это означает, что мы используем определенную часть данных для соответствия модели (обучающий набор) и сохраняем оставшуюся часть для оценки точности прогноза подобранной модели (тестового набора).
Официального правила, которому нужно следовать при выборе пропорции разделения, не существует, хотя в большинстве случаев вы хотите, чтобы около 70% было выделено для обучающего набора и около 30% — для набора тестов.
Чтобы изучить как мультиклассовые классификации, так и данные обучения / тестирования, мы рассмотрим другой набор данных с веб-сайта Elements of Statistical Learning . Эти данные используются для определения того, какой из одиннадцати гласных звуков был произнесен:
import pandas as pd vowel_train = pd.read_csv('vowel.train.csv', sep=',', header=0) vowel_test = pd.read_csv('vowel.test.csv', sep=',', header=0) vowel_train.head() y_tr = vowel_train.iloc[:,0] X_tr = vowel_train.iloc[:,1:] y_test = vowel_test.iloc[:,0] X_test = vowel_test.iloc[:,1:] y х.1 х.2 х.3 х.4 х.5 x.6 x.7 x.8 х.9 х.10 0 1 -3,639 0,418 -0,670 1,779 -0,168 1,627 -0,388 0,529 -0,874 -0,814 1 2 -3,327 0,496 -0,694 1,365 -0,265 1,933 -0,363 0,510 -0,621 -0,488 2 3 -2,120 0,894 -1,576 0,147 -0,707 1,559 -0,579 0,676 -0,809 -0,049 3 4 -2,287 1,809 -1,498 1.012 -1,053 1.060 -0,567 0,235 -0,091 -0,795 4 5 -2,598 1,938 -0,846 1.062 -1,633 0,764 0,394 -0,150 0,277 -0,396
Теперь мы подбираем модели и тестируем их, как это обычно делается в статистике / машинном обучении: обучая их на обучающем наборе и оценивая их на тестовом наборе.
Кроме того, поскольку это мультиклассовая классификация, некоторые аргументы должны быть изменены в каждом алгоритме:
import pandas as pd import sklearn as sk from sklearn.linear_model import LogisticRegression from sklearn import svm from sklearn.ensemble import RandomForestClassifier from sklearn.neural_network import MLPClassifier vowel_train = pd.read_csv('vowel.train.csv', sep=',',header=0) vowel_test = pd.read_csv('vowel.test.csv', sep=',',header=0) y_tr = vowel_train.iloc[:,0] X_tr = vowel_train.iloc[:,1:] y_test = vowel_test.iloc[:,0] X_test = vowel_test.iloc[:,1:] LR = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial').fit(X_tr, y_tr) LR.predict(X_test) round(LR.score(X_test,y_test), 4) SVM = svm.SVC(decision_function_shape="ovo").fit(X_tr, y_tr) SVM.predict(X_test) round(SVM.score(X_test, y_test), 4) RF = RandomForestClassifier(n_estimators=1000, max_depth=10, random_state=0).fit(X_tr, y_tr) RF.predict(X_test) round(RF.score(X_test, y_test), 4) NN = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(150, 10), random_state=1).fit(X_tr, y_tr) NN.predict(X_test) round(NN.score(X_test, y_test), 4) 0.5455 Хотя реализация этих моделей была довольно наивной (на практике существует множество параметров, которые можно и нужно варьировать для каждой модели), мы все же можем сравнить точность прогнозов по моделям. Это скажет нам, какой из них наиболее точен для этого конкретного набора данных для обучения и тестирования:
Модель Прогнозная точность Логистическая регрессия 46,1% Машина опорных векторов 64,07% Случайный лес 57,58% Нейронная сеть 54,55%
Это показывает нам, что для данных гласных наиболее точной была SVM, использующая радиальную базисную функцию по умолчанию.
Заключение
Подводя итог этому посту, мы начали с изучения простейшей формы классификации: бинарной. Это помогло нам смоделировать данные, в которых наш ответ мог принимать одно из двух состояний.
Затем мы перешли к мультиклассовой классификации, когда переменная ответа может принимать любое количество состояний.
Мы также увидели, как подбирать и оценивать модели с обучающими и тестовыми наборами. Кроме того, мы могли бы изучить дополнительные способы уточнения подбора моделей среди различных алгоритмов.
Licensed under CC BY-NC-SA 4.0
Обзор методов классификации в машинном обучении с помощью Scikit-Learn

Для машинного обучения на Python написано очень много библиотек. Сегодня мы рассмотрим одну из самых популярных — Scikit-Learn.
Scikit-Learn упрощает процесс создания классификатора и помогает более чётко выделить концепции машинного обучения, реализуя их с помощью понятной, хорошо документированной и надёжной библиотекой.
Что такое Scikit-Learn?
Scikit-Learn — это Python-библиотека, впервые разработанная David Cournapeau в 2007 году. В этой библиотеке находится большое количество алгоритмов для задач, связанных с классификацией и машинным обучением в целом.
Scikit-Learn базируется на библиотеке SciPy, которую нужно установить перед началом работы.
Основные термины
В системах машинного обучения или же системах нейросетей существуют входы и выходы. То, что подаётся на входы, принято называть признаками (англ. features).
Признаки по существу являются тем же, что и переменные в научном эксперименте — они характеризуют какой-либо наблюдаемый феномен и их можно как-то количественно измерить.
Когда признаки подаются на входы системы машинного обучения, эта система пытается найти совпадения, заметить закономерность между признаками. На выходе генерируется результат этой работы.
Этот результат принято называть меткой (англ. label), поскольку у выходов есть некая пометка, выданная им системой, т. е. предположение (прогноз) о том, в какую категорию попадает выход после классификации.
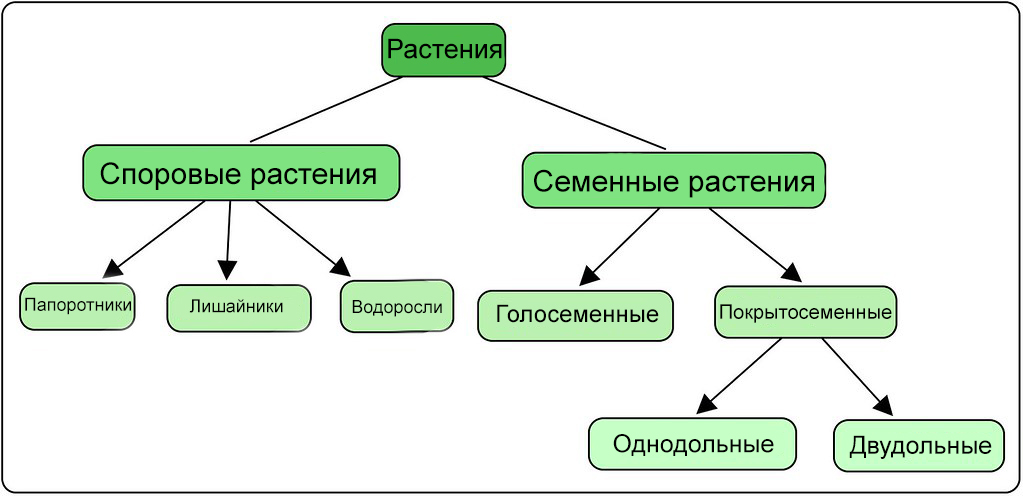
В контексте машинного обучения классификация относится к обучению с учителем. Такой тип обучения подразумевает, что данные, подаваемые на входы системы, уже помечены, а важная часть признаков уже разделена на отдельные категории или классы. Поэтому сеть уже знает, какая часть входов важна, а какую часть можно самостоятельно проверить. Пример классификации — сортировка различных растений на группы, например «папоротники» и «покрытосеменные». Подобная задача может быть выполнена с помощью Дерева Решений — одного из типов классификатора в Scikit-Learn.
При обучении без учителя в систему подаются непомеченные данные, и она должна попытаться сама разделить эти данные на категории. Так как классификация относится к типу обучения с учителем, способ обучения без учителя в этой статье рассматриваться не будет.
Процесс обучения модели — это подача данных для нейросети, которая в результате должна вывести определённые шаблоны для данных. В процессе обучения модели с учителем на вход подаются признаки и метки, а при прогнозировании на вход классификатора подаются только признаки.
Принимаемые сетью данные делятся на две группы: набор данных для обучения и набор для тестирования. Не стоит проверять сеть на том же наборе данных, на которых она обучалась, т. к. модель уже будет «заточена» под этот набор.
Типы классификаторов
Scikit-Learn даёт доступ ко множеству различных алгоритмов классификации. Вот основные из них:
На сайте Scikit-Learn есть много литературы на тему этих алгоритмов с кратким пояснением работы каждого из них.