Машинное обучение python numpy

Вы можете увидеть несколько различных версий Python. Выберите нужную, помня, что хорошим тоном является использование виртуальных окружений. Я использую виртуальное окружение, созданное miniconda.
Дальше мы увидим, следующую картину:
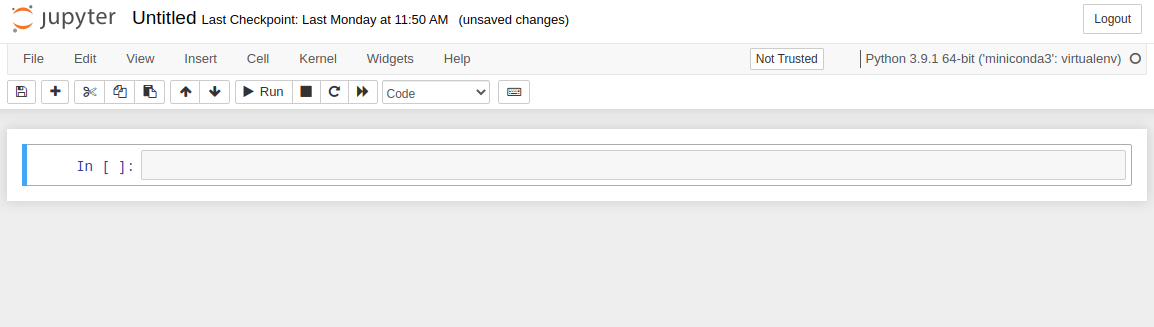
По умолчанию доступна пустая ячейка для вставки кода. Введем в нее print(«Hello proglib.io») и нажмём Ctrl+Enter. Это заставить Jupyter выполнить этот участок кода и вывести под ячейкой результат его выполнения.
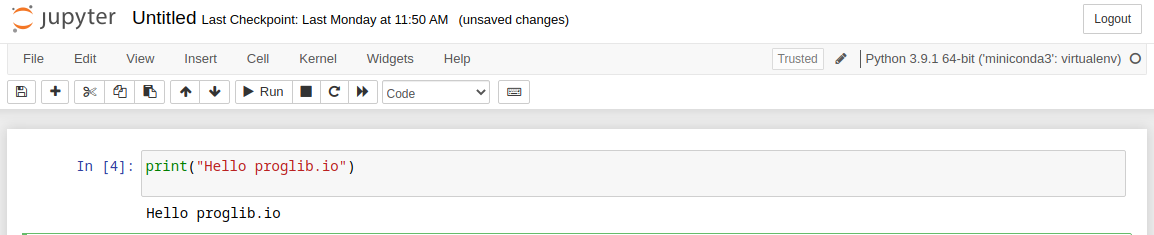
Доступна похожая на предыдущую комбинация клавиш Shift+Enter, которая выполняет код в текущей активной ячейке и добавляет под ней новую.
Второй тип ячеек, поддерживаемый в Jupyter Notebook, позволяет использовать разметку markdown. Чтобы сменить тип ячейки, можно нажать латинскую клавишу M или выбрать тип в выпадающем списке вверху.
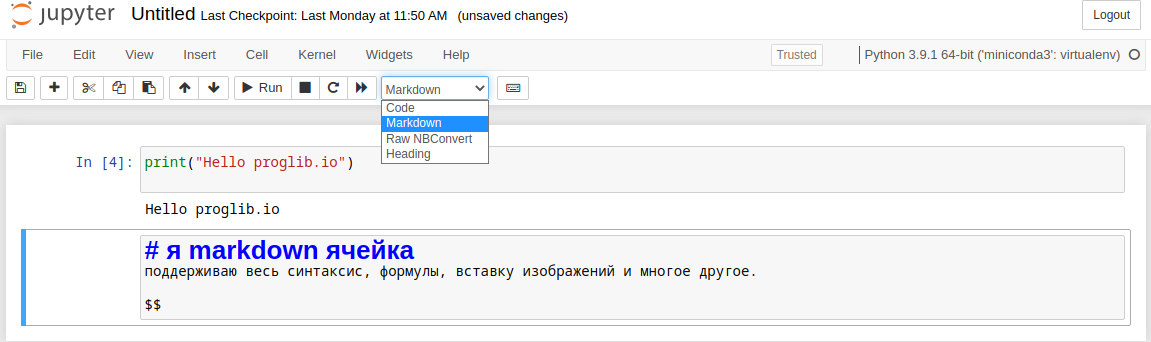
Полное описание синтаксиса этих ячеек можно найти здесь .
Дополнительные материалы:
NumPy. Массивы, базовые операции, индексация
Прежде, чем начать погружение в NumPy, его необходимо установить. Чтобы потом не отвлекаться, поставим и остальные необходимый пакеты. Откроем терминал и выполним:

В приведенном коде, создаем массив a1 из списка чисел. Обращаемся к свойству массива ndim, получаем одномерный массив.
Создадим двумерный массив. Для этого в качестве параметра будем метода array будем использовать не список, а список списков.

Чтобы узнать не только количество осей, но и количество элементов в каждой из них используют свойство shape . Для наших списков оно выглядит следующим образом:

Список а1 представляет собой одну ось из пяти элементов. Список a2 – одна ось из двух элементов, т.е. из двух строк, и вторая ось из пяти элементов, т.е. из пяти столбцов.
NumPy предоставляет довольно много различных функций для построение массивов. Рассмотрим некоторые из них. Мы уже сталкивались с методом array, позволяющим обернуть обычный список python в массив NumPy.
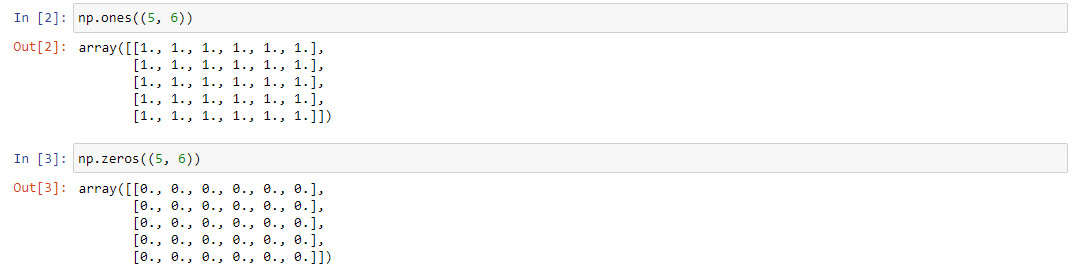
Существует довольно много специальных массивов, применяемых в различных расчетах: единичные, нулевые, пустые и т.д. Чтобы получить массив, состоящий строго из одних единиц, используется метод ones((n,m)) .
Квадратная матрица, состоящая из единиц на главной диагонали и остальных нулей, называется единичной и строится с помощью метода identity(n). Единственный входной параметр – количество строк и столбцов.

Обратите внимание, что матрица состоит не из нулей, а из очень маленьких чисел типа float.
В NumPy есть аналог стандартной функции range: np.arange(, stop, ). Он возвращает равномерно распределенные значения в заданном интервале и может принимать как целые числа, так и числа с плавающей точкой. Например:

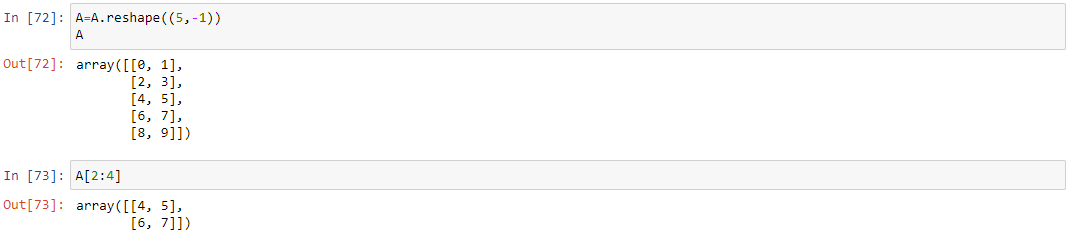
Метод reshape(a, newshape, order=’C’) позволяет переделать форму (количество осей) существующего массива. Для наглядности будем использовать следующий массив и приведем несколько примеров:
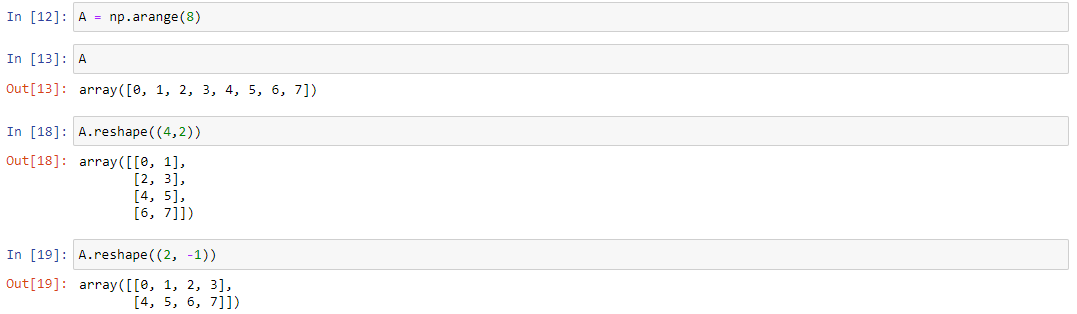
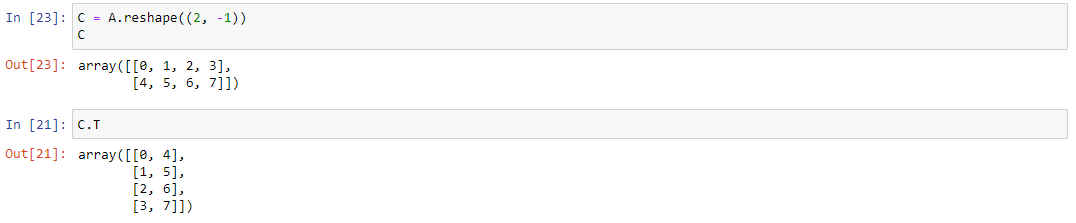
NumPy позволяет транспонировать матрицы. Создадим себе матрицу С следующим образом:
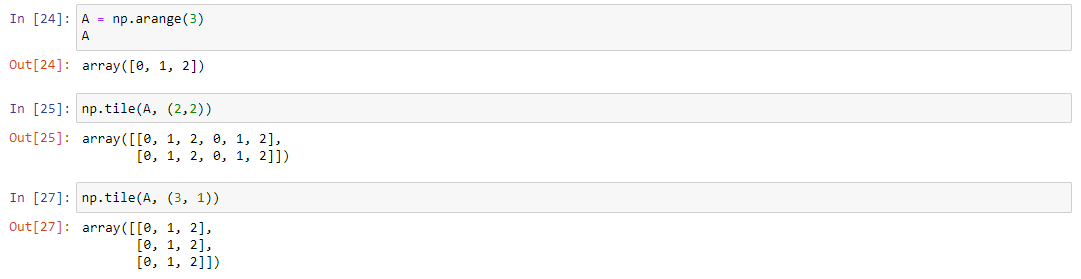
Часто возникает необходимость создать массив, состоящий из повторов другого массива. Для этого существует метод numpy.tile(A, reps), где A – какой-то массив, а resp – шаблон, по которому нужно скопировать массив А. Рассмотрим несколько примеров. Для этого создадим список A следующим образом:
Операции с массивами NumPy
NumPy предоставляет множество поэлементных арифметических операций над массивами: сложение, вычитание, умножение, деление, возведение в степень, тригонометрические функции, гиперболические функции.
Поэлементная операция воздействует на каждый конкретный элемент. Сложение складывает элементы, находящиеся на одинаковых индексах. Аналогично работают вычитание, умножение и деление.
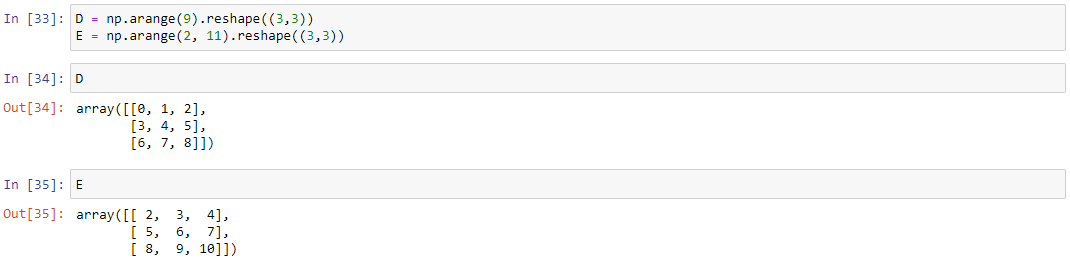
Создадим матрицы D и E размера 3х3. Для примера, сложим обе матрицы, перемножим друг с другом, перемножим матрицу E с числом 10. Остальные операции доступны в блокноте, ссылка на который в конце статьи:
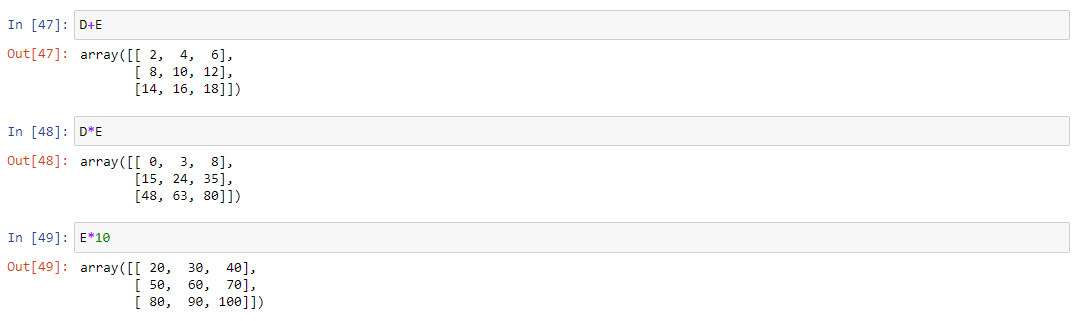
Стоит отдельно отметить, что выбор знака * для поэлементного перемножения матриц выглядит странным. От него, согласно правилам линейной алгебры, интуитивно ожидается другое поведение – перемножение матриц по следующим правилам: каждый элемент результирующей матрицы – сумма произведений каждого элемента соответствующей строки в первой матрице с соответствующим элементом из колонки второй. Но он позволяет поэлементно перемножить две матрицы.
Для классического умножения в NumPy используется метод dot(a, b). Применим его к нашим матрицам D и E.

Чтобы найти максимум матрицы, можно использовать метод max().

Входным параметром данного метода является axis — возвращение максимум по соответствующему измерению.
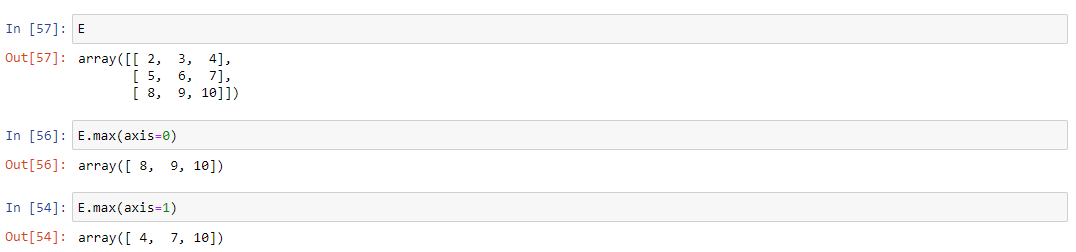
Аналогичным образом работает метод sum():

Индексация массивов NumPy
Пакет NumPy поддерживает несколько различных способ индексации массивов. Чтобы их рассмотреть, создадим себе массив A:
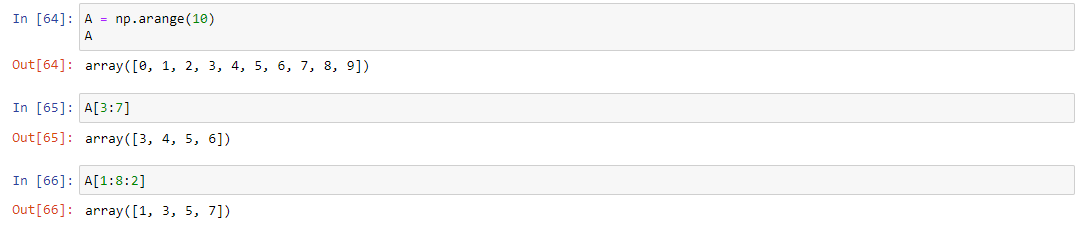
Для сортировки можно использовать логические операции. Выведем четные элементы списка от нуля до девяти. Для этого вместо индексов можно использовать логические выражения. Для связки выражений используются функции np.logical_and() и np.logical_or().

Pandas
Pandas – очень популярная библиотека для обработки данных на python. Работает на основе numpy и предоставляет специальные структуры данных для манипулирования с таблицами и временны́ми рядами. Мы с вами уже установили этот модуль, осталось импортировать его в блокнот.
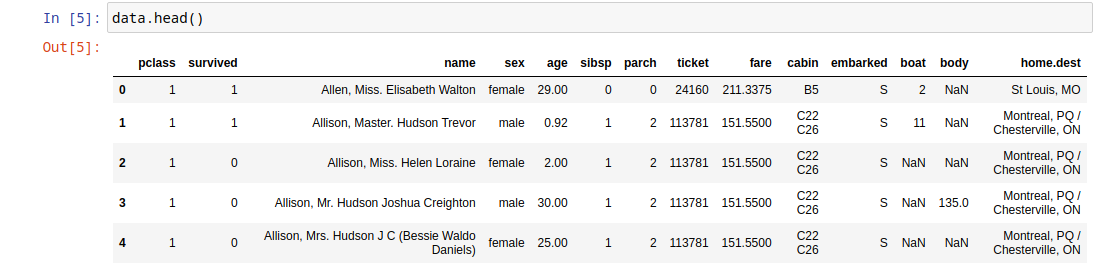
Для получения имен колонок существует свойство columns.

Индексация датафреймов аналогична стандартной индексации списков в python и индексации numpy.

Помимо такого способа, pandas предоставляет два метода индексации:
- iloc для индексации по номера столбцов и строк
- loc для индексации по строковым значением строк и названиям столбцов.
Например, есть задача получить пол пассажиров для строк с первой по седьмую. Используем loc следующий образом:

iloc работает аналогичным образом, но только с номерами строк и столбцов, а не с их именами.
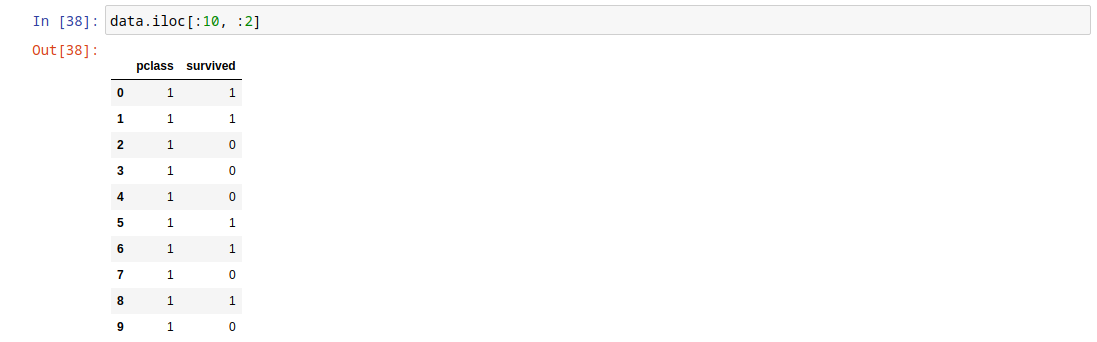
Получим для примера первые два столбца первых десяти строк.
Есть возможность обращаться по имени к каждому конкретному столбцу. Получим первые пять имен пассажиров нашей таблицы:

При индексации можно строить логические запросы к данным датафрефма. Для примера выведем пять первых женщин пассажиров.

Логика работы следующая: получаем строки таблицы, в которых колонка sex = female. Выбираем только колонку name и с помощью метода head() получаем верхние пять строк.
Усложним пример. Получим датафрейм, содержащий первые пять мужчин или женщин старше 50 лет.
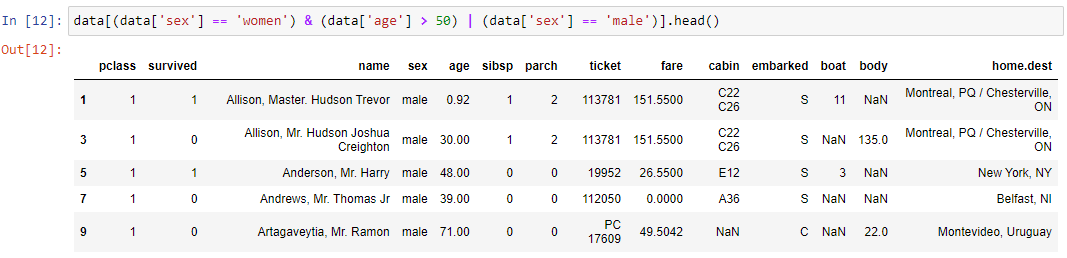
Связка условий происходит с помощью логических операторов И (&) и ИЛИ (|).
Изменение датафреймов Pandas
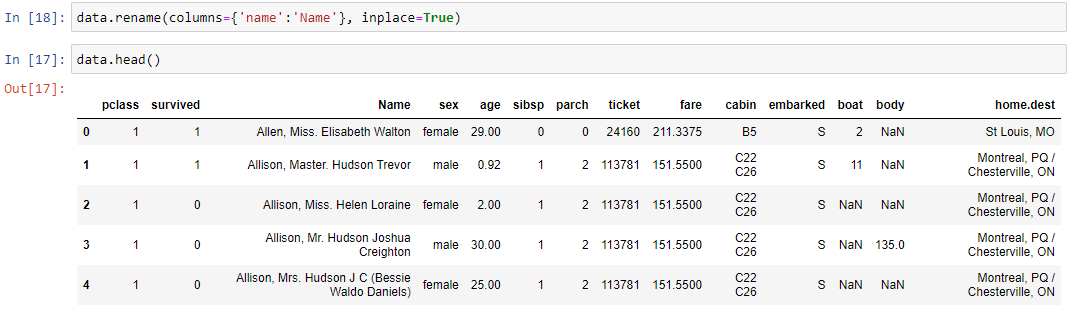
Пусть нам необходимо изменить название колонки. Pandas позволяет сделать это одной левой с помощью метода rename(). Переименуем колонку name в Name. В параметр columns передаем словарь, в котором указываются пары старое_имя:новое_имя колонок. Параметр inplace=True заставляет Pandas менять текущий датафрейм, а не создавать новый.
Возможно применить произвольную пользовательскую функцию к каждому элементу выбранных столбцов. Например, получим фамилии всех людей из колонки Name.
Функция получения фамилии выглядит следующим образом:

Теперь, чтобы применить ее ко всем элементам датафрейма, используется метод apply(), в которую передается объект функции. Например:

А теперь добавим в наш датафрейм столбец фамилий, которые мы сохранили в переменной last_names. Для этого просто в квадратных скобках указывается имя нового столбца:
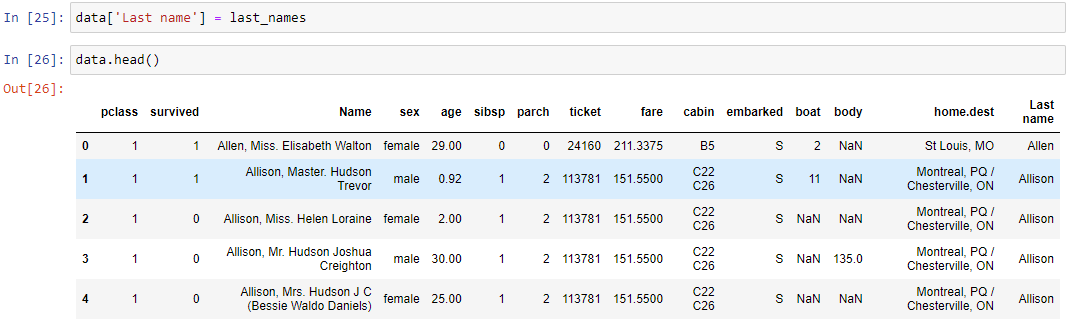
Чтобы удалить столбец, используется метод drop(). Удалим только что добавленный столбец фамилий. Параметр axis необходим, чтобы явно указать pandas работать со столбцами. Попробуйте поменять его на ноль и посмотреть, что произойдет.
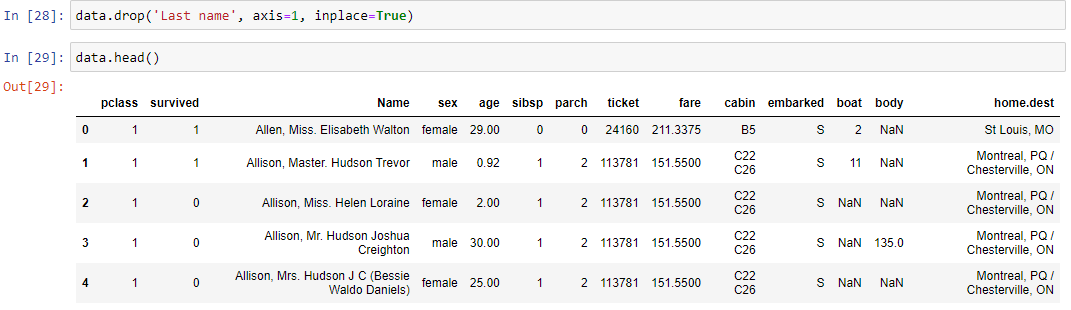
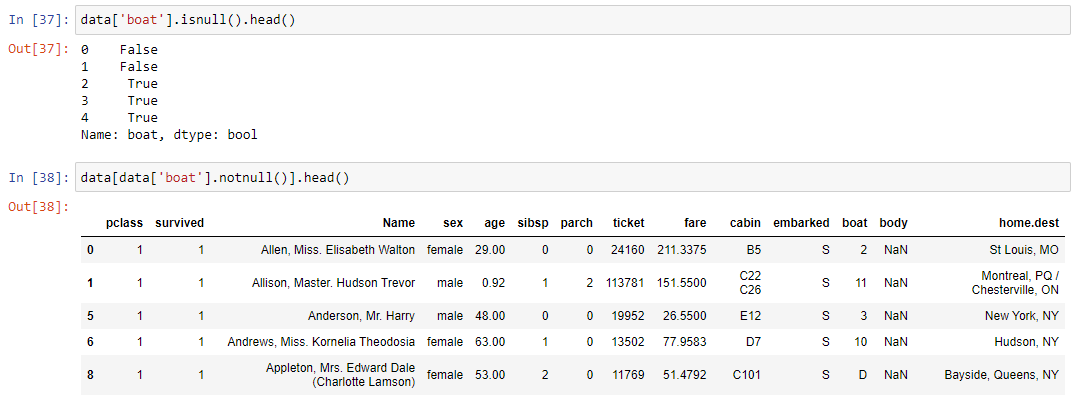
Очень часто датасеты поставляются неполными. Это значит, что в некоторых ячейках таблицы может не быть данных. В машинном обучении стараются или избавиться от таких строк данных, или как-то их заполнить. Для получения пустых строк используется метод isnull(), а для получения непустых строк – метод notnull(). Работает достаточно интуитивно.
Если вы работали с SQL, то вам наверняка знаком метод GROUP BY. Он позволяет группировать данные по какому-то заданному критерию. Pandas обладает такими же возможностями. Для этого используется метод groupby().
Сгруппируем пассажиров по полу в зависимости от класса каюты и посчитаем их количество:

Pandas содержит набор статистических методов, которые позволяют найти среднее значение, максимум, минимум, стандартное отклонение какого-либо набора данных из датафрейма. Кроме того, для быстрой оценки всех популярных параметров используется метод describe(). Рассчитаем все эти показатели для стоимости проезда пассажиров по разным классам:

В результате, получаем таблицу, содержащую количество пассажиров, среднюю стоимость, ее стандартное отклонение и другие показатели.
Эти же функции доступны отдельно. Например, определим в каком соотношении выжили мужчины и женщины:

После окончания работы с датафремом, его можно сохранить в файлы различных форматов. Например, для сохранения в csv формат используется метод to_csv().
Пакет позволяет строить семейства графиков.
1. График в графике. Схема состроения абсолютно такая же, как в предудыщем примере
2. Семейство графиков. В этом случае, холст создается методом subplots(), параметром которого является кортеж чисел, сколько графиков по-горизонтали и по-вертикали он включает в себя. Построим одну строку из трех графиков.
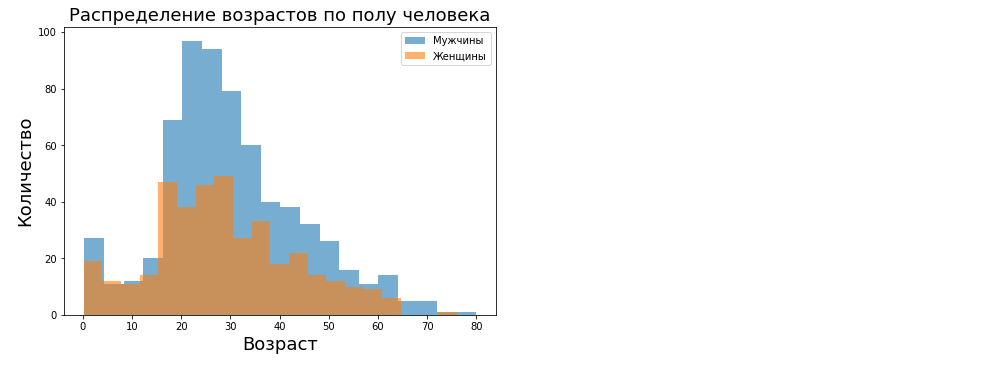
Matplotlib подходит для построения статистических графиков. Это огромная область, но построим гистограмму распределение пассажиров по возрасту для мужчин и женщин. В качестве данных используем тот же датасет titanic.
Стоит сказать, что это очень малая часть возможностей данной библиотеки. В качестве дополнительных материалов оставлю ссылки на документацию по всем рассмотренным в статье модулям: