Парсинг html библиотекой jsoup


Итак мы хотим получить конкретную информацию с сайта. Пошагово разберем как это сделать. Для начала нам нужно получить объект Document . Это представление нашей html страницы. В Jsoup есть несколько способов превратить сайт в объект Document . Подключиться к серверу
Document document = Jsoup.connect("https://hh.ru/").get(); Jsoup сам подключается к сайту. Данный способ самый простой, но он годится только для тестирования. Есть более удобные и гибкие http клиенты. Также имейте ввиду, каким бы http клиентом вы не пользовались, добавляйте в запрос заголовок User-Agent с значением например Chrome/81.0.4044.138 . По этому заголовку сервер определяет с какого устройстрва вы подключились. Без этого заголовка сервер считает вас ботом и может забанить. Из файла;
File file = new File("hh-test.html"); Document document = Jsoup.parse(file, "UTF-8", "hh.ru"); Это основной способ получения объекта Document . Последний аргумент «hh.ru» — базовый URI. Это нужно для создания абсолютных ссылок из относительных, которые присутствуют на сайте. Из строки
String html = " " + " " + " " + " Работа в Москве, поиск персонала и публикация вакансий - hh.ru " + " " + " " + " " + " " + " Работа найдется для каждого
" + " Поиск вакансий " + " " + " Вакансии дня " + " " + " Работа из дома " + " " + " " + " "; Document document = Jsoup.parse(html, "hh.ru"); Далее я буду демонстрировать библиотеку на этом html, который представляет упрощенный сайт. Получение тега Основная задача при парсинге — получить нужный тег. Делать мы это будем при помощи метода select . Обратите внимание, что он всегда возвращает список тегов. Если теги не найдены, то список будет пустым. В аргумент метода нужно передать css селектор, по которому ищутся теги. На селекторах я остановлюсь подробнее, потому что вся работа сводится к написанию правильного селектора. Обычно нам нужно составить его так, чтобы он возвращал один тег.
Elements h1 = document.select("h1"); System.out.println(h1); Работа найдется для каждого
Elements titleElem = document.select("head > title"); Elements divs = document.select("body > div"); Elements firstDiv = document.select("body > div:nth-child(1)"); Получить первый тег div вложенный в body . Получать тег по порядковому номеру плохой способ, потому что его положение на сайте может поменяться. Лучше определить тег по абсолютным параметрам. Такими параметрами являются атрибуты class и id
Elements contentElem = document.select("body > div.content"); Elements idElem = document.select("#123"); Elements divHeader = document.select("body > div.header.main :not(h1)"); Методы Elements Когда мы получили список Elements можно извлечь данные из него. Напомню, что обычно селектором ищется один тег, т.е. у Elements должен быть размер 1.
строковое представление тега Если вам нужно быстро получить селектор элемента — в браузере откройте панель разработчика (f12), нажмите правой кнопкой на элемент, «просмотреть код», нажмите правой кнопкой на тег, далее «Copy» «Copy selector». Такой селектор будет не оптимальным, но для быстрого результата вполне подходит. 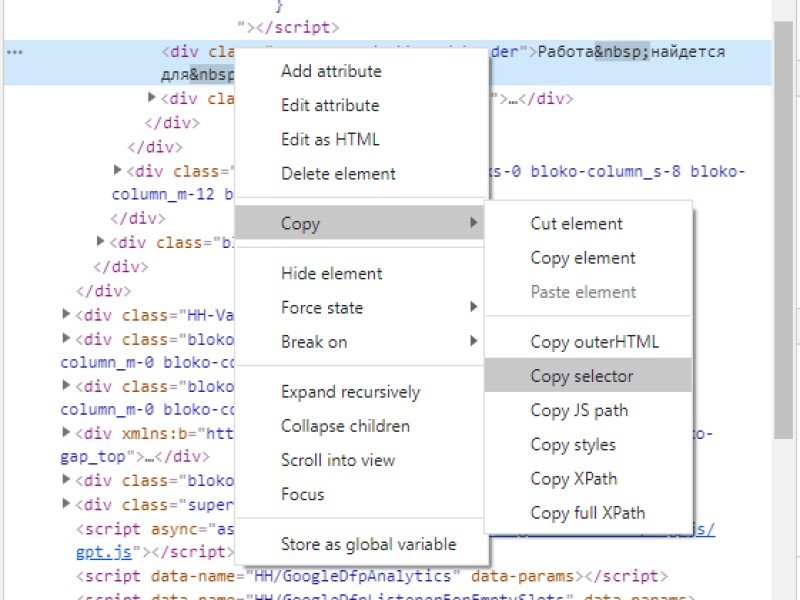
 Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне
Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне
3 примера как разобрать HTML-файл в Java используя Jsoup

HTML это ядро WEB, все интернет-страницы которые Вы видите, являются ли они динамически сгенерированы средствами JavaScript, JSP, PHP, ASP или другими веб-технологиями, основаны на HTML. На самом деле, Ваш браузер разбирает HTML и отображает его в удобном для Вас виде. Но что делать если Вам нужно разобрать HTML-документ и найти в нем некоторый элемент, тэг, атрибут или проверить существует или нет конкретный элемент при помощи программы на Java. Если бы Вы были Java программистом уже несколько лет, я уверен, Вы бы сделали XML разбор используя парсеры вроде DOM или SAX. Но, по иронии судьбы, бывают случаи, когда Вам необходимо разобрать HTML-документ из базового Java приложения, которое не содержит Servlet и другие Java веб-технологии. Более того, Core JDK также не содержит HTTP или HTML библиотек. Вот почему, когда дело доходит до разбора HTML файла, многие Java программисты спрашивают у Google, как получить значение HTML-тэга в Java. Когда я столкнулся с этим, я был уверен что решением будет open-source библиотека, осуществляющая нужную мне функциональность, но я не знал, что она будет такой замечательной и многофункциональной как Jsoup. Она не только обеспечивает поддержку чтения и разбора HTML файлов, атрибутов, CSS классов в стиле JQuery, но и в то же время, позволяет модифицировать их. Используя Jsoup Вы можете сделать с HTML документом все что угодно. В этой статье мы будем разбирать HTML файл и находить названия и атрибуты тэгов. Также мы разберем примеры скачивания и разбора HTML из файла и любого URL-адреса, например домашнюю страницу Google.
Что такое Jsoup
- Jsoup может очистить и разобрать HTML из URL, файла или строки.
- Jsoup может найти и извлечь данные используя обход DOM или CSS селекторы.
- Jsoup позволяет манипулировать HTML элементами, атрибутами и текстом.
- Jsoup обеспечивает очистку предоставленной пользователем информации по white-list, для предотвращения XSS атак.
- Также Jsoup выдает «аккуратный» HTML.
Разбор HTML в Java используя Jsoup
В этом учебнике мы увидим три различных примера разбора и обхода HTML-документа в Java используя Jsoup. В первом примере, мы будем разбирать HTML строку, содержащую тэги, в форме строкового литерала Java. Во втором примере, мы скачаем наш HTML-документ из интернет, и в третьем примере, мы загрузим для разбора наш собственный образец HTML файла login.html. Этот файл — образец HTML документа, который состоит из тэга «title» и тэга «div» в секции «body», который содержит HTML форму. В форме находятся поля для ввода имени пользователя и пароля, а также кнопки сброса и подтверждения для дальнейших действий. Это «правильный» HTML, который может пройти проверку на «валидность», то есть все тэги и атрибуты правильно закрыты. Вот как выглядит наш HTML файл:
С помощью Jsoup очень просто разобрать HTML, все что Вам нужно это вызвать статический метод Jsoup.parse() и передать в него Вашу HTML строку. Jsoup предоставляет несколько перегруженных методов parse() для чтения HTML из строки, файла, из базового URI, из URL и из InputStream . Вы также можете указать кодировку, для корректного чтения HTML файла, в случае если он не в формате «UTF-8». Метод parse(String html) разбирает входящий HTML в новый объект Document . В Jsoup класс Document наследует класс Element , который расширяет класс Node . Также от класса Node наследуется класс TextNode . До тех пор, пока Вы передаете в метод строку отличную от null, Вы гарантированно имеете успешный, осмысленный разбор, объект Document содержащий (по крайней мере) элементы «head» и «body». Если у Вас есть объект Document , Вы можете получить желаемые данные вызвав соответствующие методы класса Document и его родителей Element и Node .
Java программа для разбора HTML документа
Вот наша полная программа для разбора HTML-строки, HTML-файла, скачанного из интернет и локального HTML файла. Для ее запуска Вы можете использовать IDE (Eclipse или любую другую) или командную строку. В Eclipse это очень легко, просто скопируйте этот код, создайте новый Java проект, щелкните правой кнопкой мыши по папке «src» и вставьте скопированный код (paste). Eclipse позаботится о создании надлежащего пакета и файла исходного кода с соответствующим именем, так гораздо меньше работы. Если у Вас уже есть Java проект, тогда это всего один шаг. Расположенная ниже программа иллюстрирует три примера разбора и обхода HTML файла. В первом примере, мы непосредственно разбираем строку, содержащую HTML, во втором HTML-файл скачанный из URL, в третьем мы загружаем и разбираем HTML-документ из локальной файловой системы.
import java.io.File; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; /** * Java Program to parse/read HTML documents from File using Jsoup library. * Jsoup is an open source library which allows Java developer to parse HTML * files and extract elements, manipulate data, change style using DOM, CSS and * JQuery like method. * * @author Javin Paul */ public class HTMLParser< public static void main(String args[]) < // Parse HTML String using JSoup library String HTMLSTring = "" + "" + "" + "" + "" + "" + "HelloWorld
" + "" + ""; Document html = Jsoup.parse(HTMLSTring); String title = html.title(); String h1 = html.body().getElementsByTag("h1").text(); System.out.println("Input HTML String to JSoup :" + HTMLSTring); System.out.println("After parsing, Title : " + title); System.out.println("Afte parsing, Heading : " + h1); // JSoup Example 2 - Reading HTML page from URL Document doc; try < doc = Jsoup.connect("http://google.com/").get(); title = doc.title(); >catch (IOException e) < e.printStackTrace(); >System.out.println("Jsoup Can read HTML page from URL, title : " + title); // JSoup Example 3 - Parsing an HTML file in Java //Document htmlFile = Jsoup.parse("login.html", "ISO-8859-1"); // wrong Document htmlFile = null; try < htmlFile = Jsoup.parse(new File("login.html"), "ISO-8859-1"); >catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >// right title = htmlFile.title(); Element div = htmlFile.getElementById("login"); String cssClass = div.className(); // getting class form HTML element System.out.println("Jsoup can also parse HTML file directly"); System.out.println("title : " + title); System.out.println("class of div tag : " + cssClass); > > Input HTML String to JSoup :HelloWorld
After parsing, Title : JSoup Example Afte parsing, Heading : HelloWorld Jsoup Can read HTML page from URL, title : Google Jsoup can also parse HTML file directly title : Login Page class of div tag : simple