- Saved searches
- Use saved searches to filter your results more quickly
- License
- JazzCore/python-pdfkit
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.rst
- About
- Создание PDF из HTML шаблона с помощью Python
- Создаем шаблон для формирования PDF
- Создаем PDF используя pdfkit
- Категории
- Свежие записи
- Python – Convert HTML Page to PDF
- What additional libraries or software do we need?
- Install pdfkit
- Install wkhtmltopdf
- Example 1: HTML to PDF using URL
- Example 2: Convert HTML to PDF from Local File
- Example 2: Convert HTML String to PDF
- Summary
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Wkhtmltopdf python wrapper to convert html to pdf
License
JazzCore/python-pdfkit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.rst
Python-PDFKit: HTML to PDF wrapper
Python 2 and 3 wrapper for wkhtmltopdf utility to convert HTML to PDF using Webkit.
This is adapted version of ruby PDFKit library, so big thanks to them!
$ pip install pdfkit (or pip3 for python3) $ sudo apt-get install wkhtmltopdf
$ brew install homebrew/cask/wkhtmltopdf
Warning! Version in debian/ubuntu repos have reduced functionality (because it compiled without the wkhtmltopdf QT patches), such as adding outlines, headers, footers, TOC etc. To use this options you should install static binary from wkhtmltopdf site or you can use this script (written for CI servers with Ubuntu 18.04 Bionic, but it could work on other Ubuntu/Debian versions).
import pdfkit pdfkit.from_url('http://google.com', 'out.pdf') pdfkit.from_file('test.html', 'out.pdf') pdfkit.from_string('Hello!', 'out.pdf')
You can pass a list with multiple URLs or files:
pdfkit.from_url(['google.com', 'yandex.ru', 'engadget.com'], 'out.pdf') pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
Also you can pass an opened file:
with open('file.html') as f: pdfkit.from_file(f, 'out.pdf')
If you wish to further process generated PDF, you can read it to a variable:
# Without output_path, PDF is returned for assigning to a variable pdf = pdfkit.from_url('http://google.com')
You can specify all wkhtmltopdf options. You can drop ‘—‘ in option name. If option without value, use None, False or » for dict value:. For repeatable options (incl. allow, cookie, custom-header, post, postfile, run-script, replace) you may use a list or a tuple. With option that need multiple values (e.g. —custom-header Authorization secret) we may use a 2-tuple (see example below).
options = < 'page-size': 'Letter', 'margin-top': '0.75in', 'margin-right': '0.75in', 'margin-bottom': '0.75in', 'margin-left': '0.75in', 'encoding': "UTF-8", 'custom-header': [ ('Accept-Encoding', 'gzip') ], 'cookie': [ ('cookie-empty-value', '""') ('cookie-name1', 'cookie-value1'), ('cookie-name2', 'cookie-value2'), ], 'no-outline': None > pdfkit.from_url('http://google.com', 'out.pdf', options=options)
By default, PDFKit will run wkhtmltopdf with quiet option turned on, since in most cases output is not needed and can cause excessive memory usage and corrupted results. If need to get wkhtmltopdf output you should pass verbose=True to API calls:
pdfkit.from_url('google.com', 'out.pdf', verbose=True)
Due to wkhtmltopdf command syntax, TOC and Cover options must be specified separately. If you need cover before TOC, use cover_first option:
toc = < 'xsl-style-sheet': 'toc.xsl' > cover = 'cover.html' pdfkit.from_file('file.html', options=options, toc=toc, cover=cover) pdfkit.from_file('file.html', options=options, toc=toc, cover=cover, cover_first=True)
You can specify external CSS files when converting files or strings using css option.
Warning This is a workaround for this bug in wkhtmltopdf. You should try —user-style-sheet option first.
# Single CSS file css = 'example.css' pdfkit.from_file('file.html', options=options, css=css) # Multiple CSS files css = ['example.css', 'example2.css'] pdfkit.from_file('file.html', options=options, css=css)
You can also pass any options through meta tags in your HTML:
body = """ Hello World! """ pdfkit.from_string(body, 'out.pdf') #with --page-size=Legal and --orientation=Landscape
Each API call takes an optional configuration parameter. This should be an instance of pdfkit.configuration() API call. It takes the configuration options as initial parameters. The available options are:
- wkhtmltopdf — the location of the wkhtmltopdf binary. By default pdfkit will attempt to locate this using which (on UNIX type systems) or where (on Windows).
- meta_tag_prefix — the prefix for pdfkit specific meta tags — by default this is pdfkit-
Example — for when wkhtmltopdf is not on $PATH :
config = pdfkit.configuration(wkhtmltopdf='/opt/bin/wkhtmltopdf') pdfkit.from_string(html_string, output_file, configuration=config)
Also you can use configuration() call to check if wkhtmltopdf is present in $PATH :
try: config = pdfkit.configuration() pdfkit.from_string(html_string, output_file) except OSError: #not present in PATH
Debugging issues with PDF generation
If you struggling to generate correct PDF firstly you should check wkhtmltopdf output for some clues, you can get it by passing verbose=True to API calls:
pdfkit.from_url('http://google.com', 'out.pdf', verbose=True)
If you are getting strange results in PDF or some option looks like its ignored you should try to run wkhtmltopdf directly to see if it produces the same result. You can get CLI command by creating pdfkit.PDFKit class directly and then calling its command() method:
import pdfkit r = pdfkit.PDFKit('html', 'string', verbose=True) print(' '.join(r.command())) # try running wkhtmltopdf to create PDF output = r.to_pdf()
- IOError: ‘No wkhtmltopdf executable found’ : Make sure that you have wkhtmltopdf in your $PATH or set via custom configuration (see preceding section). where wkhtmltopdf in Windows or which wkhtmltopdf on Linux should return actual path to binary.
- IOError: ‘Command Failed’ This error means that PDFKit was unable to process an input. You can try to directly run a command from error message and see what error caused failure (on some wkhtmltopdf versions this can be cause by segmentation faults)
About
Wkhtmltopdf python wrapper to convert html to pdf
Создание PDF из HTML шаблона с помощью Python
Довольно часто возникает необходимость сгенерировать PDF файл скриптом на Python, например у меня недавно возникла такая задача:
Необходимо добавить в систему управления предприятием функционал формирования дипломов для наград сотрудников в виде PDF файлов, чтобы можно было их распечатать или послать по почте.
Порядок работы должен быть таким:
- Менеджер, через веб-форму, вводит необходимые данные (имя сотрудника, должность и т.п.);
- Далее он выбирает шаблон диплома (шаблоны заранее подготавливаются в системе);
- Получает сформированный PDF файл.
Погуглив нашел для себя несколько способов решить задачу:
1. Использовать Python библиотеку для формирования PDF, например reportlab;
2. Сначала сформировать HTML страницу с помощью какого-нибудь шаблонизатора, а потом уже конвертировать HTML в PDF.
Первый вариант мне показался сложноватым из-за форматирования, нужно будет рисовать и позиционировать каждый элемент шаблона используя код python. По этой же причине в будущем будут сложности с поддержкой шаблонов.
Я выбрал второй вариант, поскольку HTML шаблон для моей задачи был простой и не должно было возникнуть сложности в его конвертации в PDF. В качестве шаблонизатора, я использовал Jinja
Для конвертации HTML в PDF я использовал Python-PDFKit (для его работы в вашу систему необходимо установить wkhtmltopdf).
Чтобы показать пример, я максимально упрощу задачу. Пусть нам необходимо, чтобы скрипт брал имя пользователя из переменной и подставлял его в HTML шаблон, а дальше мы бы получали PDF файл с текстом «Привет »!
Для начала установим все необходимое:
Так же необходимо скачать и установить в систему wkhtmltopdf.
Для этой заметки, я устанавливать не стал, а скачал portable версию для Windows и распаковал ее в D:\wkhtmltox (этот путь понадобится в дальнейшем).
Создаем шаблон для формирования PDF
Для нашей задачи HTML шаблон будет максимально примитивный, создадим файл pdf_template.html:
Здесь name — это переменная, которую мы будем передавать в шаблон.
Теперь нужно написать код python, который сгенерирует html шаблон. Как я уже писал мы используем шаблонизатор Jinja.
from jinja2 import Environment, FileSystemLoader name = 'Александр' env = Environment(loader=FileSystemLoader('.')) template = env.get_template("pdf_template.html") pdf_template = template.render()Сейчас в переменной pdf_template генерируется HTML шаблон:
Осталось сделать из него пдф.
Создаем PDF используя pdfkit
Осталось добавить к нашему скрипту пару строк и уже можно получить готовый пдф файл по нашему шаблону:
Сначала импортируем pdfkit:
И одной строчкой сформируем pdf:
Теперь, если выполнить скрипт, в папке появиться файл out.pdf созданный по нашему шаблону.
Поскольку я скачал portable версию wkhtmltopdf и пути к нему нет в переменной PATH, код нужно немного изменить, добавив путь к wkhtmltopdf.exe:
config = pdfkit.configuration(wkhtmltopdf=r’D:\wkhtmltox\bin\wkhtmltopdf.exe’)
pdfkit.from_string(pdf_template, ‘out.pdf’, configuration=config)
Итоговый код выглядит так:
from jinja2 import Environment, FileSystemLoader import pdfkit name = 'Александр' env = Environment(loader=FileSystemLoader('.')) template = env.get_template("pdf_template.html") pdf_template = template.render() pdfkit.from_string(pdf_template, 'out.pdf') # config = pdfkit.configuration(wkhtmltopdf=r'D:\wkhtmltox\bin\wkhtmltopdf.exe') # pdfkit.from_string(pdf_template, 'out.pdf', configuration=config) Категории
Свежие записи
Python – Convert HTML Page to PDF
PDF is one of the most used digital format to save or transfer documents. In this article, we will learn how to convert HTML page to PDF.
What additional libraries or software do we need?
We will use pdfkit library and wkhtmltopdf.
Install pdfkit
To install pdfkit, run the following pip command.
Run Code Online
Install wkhtmltopdf
Ubuntu or Debian users can install wkhtmltopdf using below apt-get command.
sudo apt-get install wkhtmltopdfProvide the password if prompted.
Windows users can download wkhtmltopdf from this official github repository wkhtmltopdf. The file size would be around 25MB and takes a moment to download.
Once downloaded, double click on the binary file and continue with the installation. It would be mostly installed at the path C:\Program Files\wkhtmltopdf. We should add bin folder to the system PATH variable in Environment Variables. For example, C:\Program Files\wkhtmltopdf\bin.
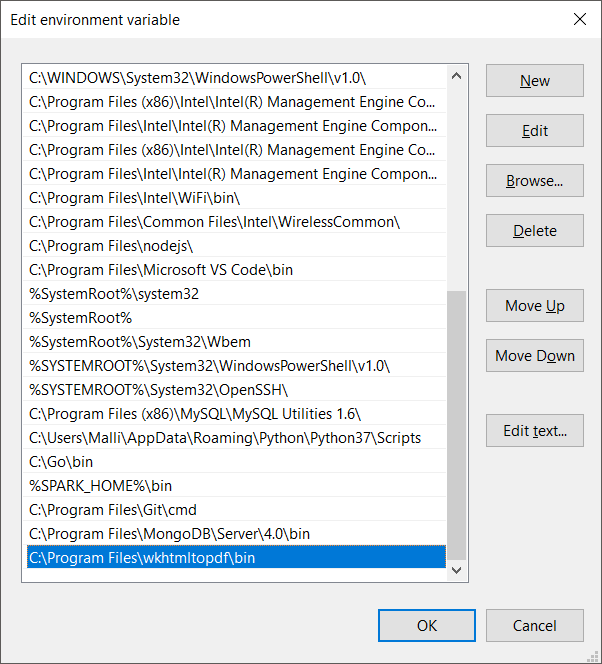
Restart the command prompt, if you are running the python program using command prompt python command for the Path to take effect.
Example 1: HTML to PDF using URL
Now that the environment is setup, following is a simple example to convert HTML to PDF, where HTML is downloaded from a URL. We use the function from_url().
import pdfkit pdfkit.from_url('https://www.google.com/','sample.pdf') The converted PDF file is saved to the current path in the command prompt or terminal.
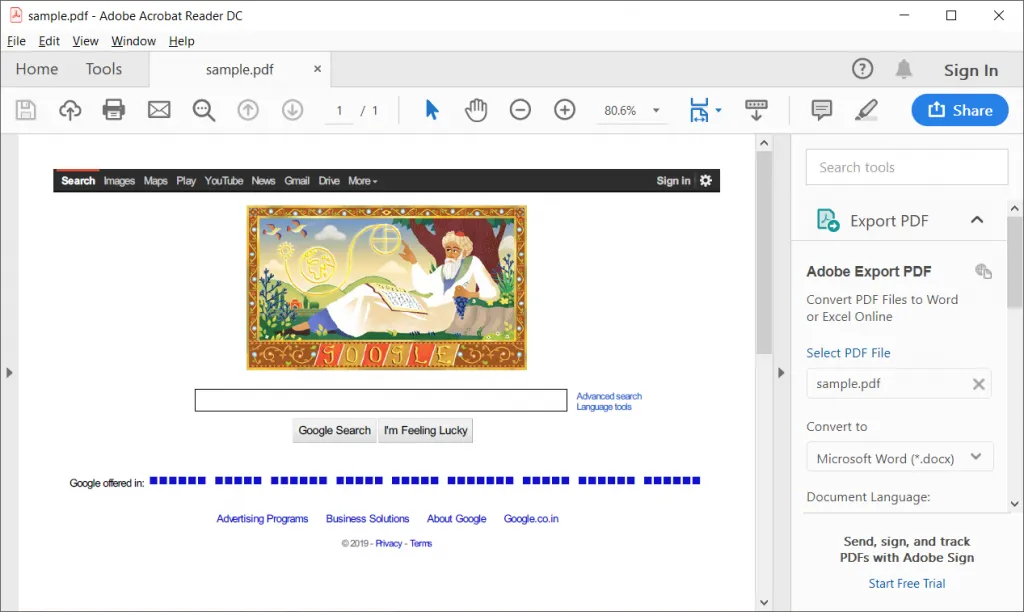
Output pdf file would look like
Example 2: Convert HTML to PDF from Local File
If your HTML file is stored locally, you can use from_file() function and convert the local HTML file to PDF.
import pdfkit pdfkit.from_file('local.html', 'sample.pdf') Example 2: Convert HTML String to PDF
If your HTML data is stored in a Python variable, you can use from_string() function and convert the HTML string to PDF.
import pdfkit var htmlstr = 'Heading 2
Sample paragraph.
' pdfkit.from_string(htmlstr, 'sample.pdf') 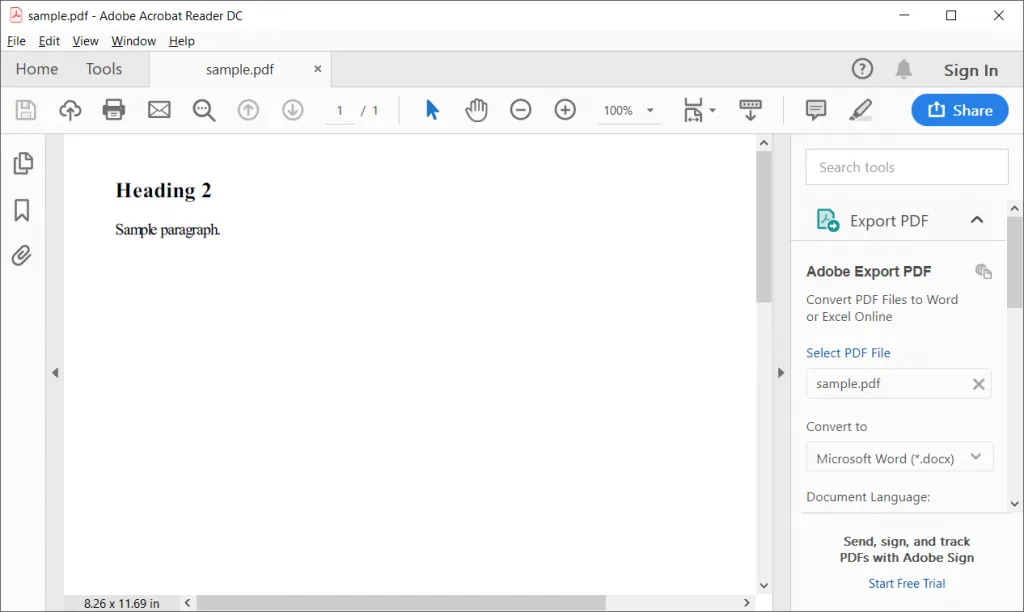
Run Code Online
Summary
We have successfully converted a HTML data to PDF. We have considered HTML data to be from a URL, local file or a string.