- Как с помощью php
- 1. Синтаксис
- XAMPP
- 14. Собираем страничку
- Литература
- Шпаргалки
- YouTube-каналы и курсы
- PHP в «Библиотеке Программиста»
- Итог
- Веб-парсинг на PHP: пошаговое руководство
- Зачем использовать PHP
- Как начать работать с PHP
- Веб-парсинг на PHP за 3 простых шага
- Шаг первый: Сбор кода вашего целевого веб-сайта
- Шаг второй: Парсинг веб-страницы
- Шаг третий: Получение читаемого текста
- Подведем итоги
- Отдаем файлы эффективно с помощью PHP
- 2. Читаем и отправляем файл вручную
- 3. Используем модуль веб сервера
Как с помощью php

1. Синтаксис
Код в PHP заключается в открывающий теги. Согласно стандарту кодирования PSR-12, закрывающий тег должен быть опущен в файлах, содержащих только код PHP . В конце строки ставят разделитель строк – точку с запятой ; . Если забыть поставить разделитель, то следующая строка кода соединится с предыдущей и интерпретатор PHP выдаст ошибку.
Выведем на экран строку Hello World (заключена в кавычки) с помощью команды echo :
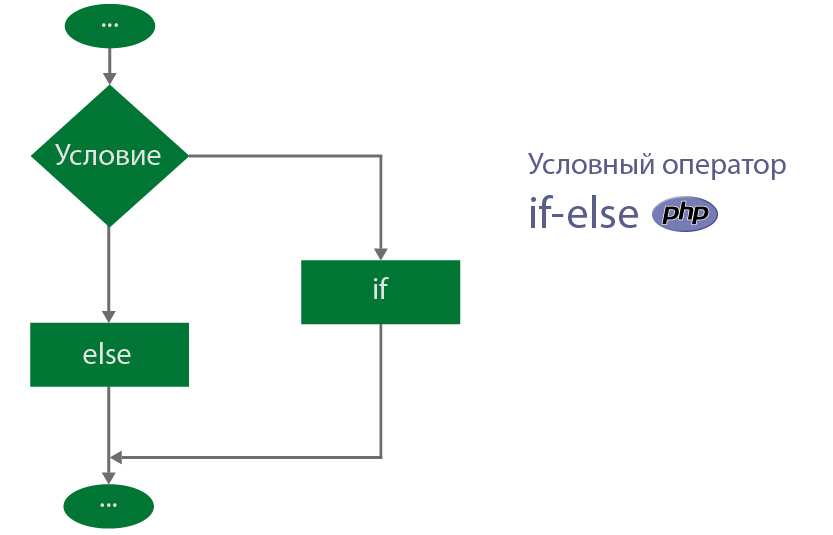
Оператор if выполняет код, если выполняется условие. В противном случае выполняется код после else, который переводится, как «иначе», «в другом случае».
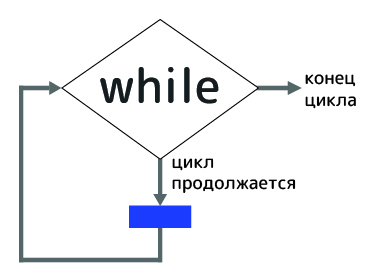
Оператор while выполняет код до тех пор, пока значение условия не станет ложным.
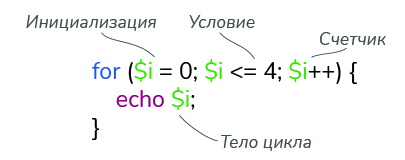
Когда нам известно количество итераций, вместо цикла while лучше использовать цикл for .
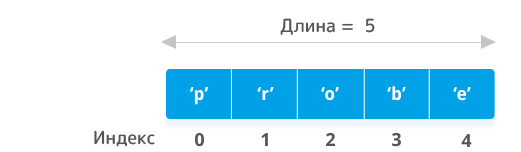
Массивы – упорядоченная коллекция элементов с доступом по индексу или ключу. Индексный массив создается двумя способами:
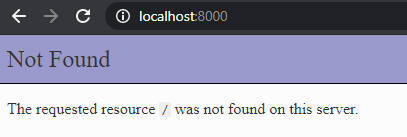
Если мы получили ошибку 404, значит сервер запущен.
XAMPP
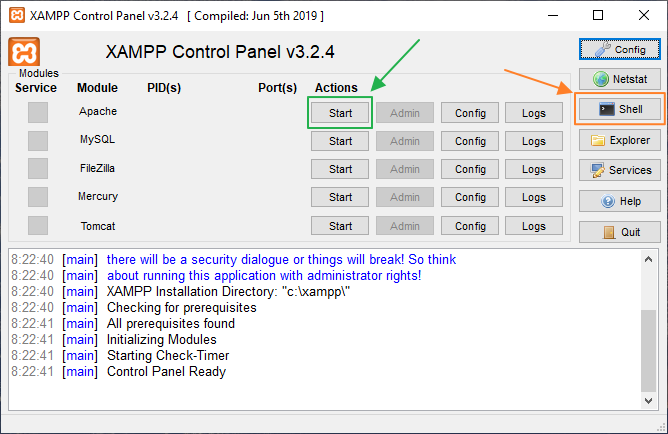
Скачаем и установим XAMPP . В папке C:\xampp\htdocs\ создадим папку нашей странички page . Запустим веб-сервер Apache, кликнув по кнопке Start . Узнаем версию PHP, введя в консоли (Shell) команду php -v .
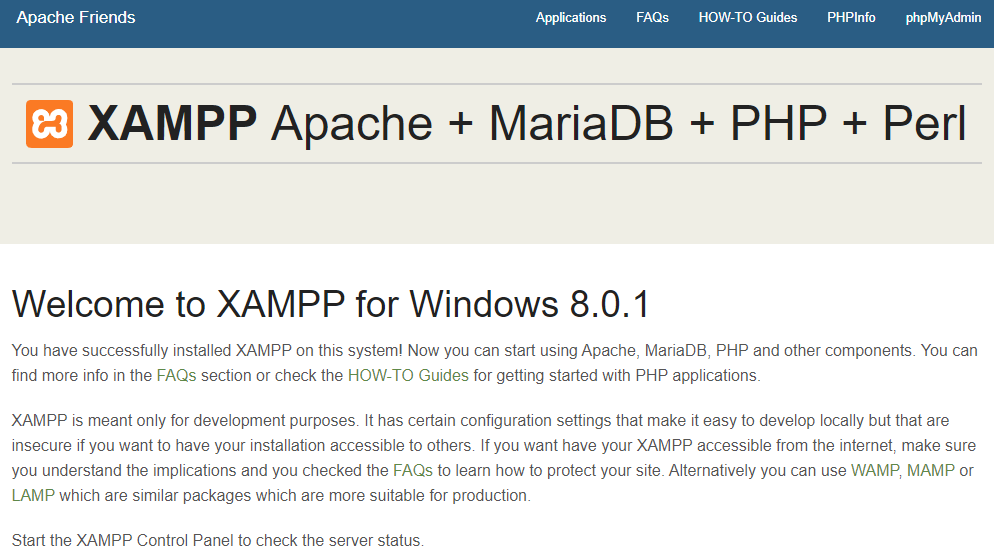
Проверим, запущен ли сервер, перейдя по адресу http://localhost/ . Если появилось приветственное сообщение, значит сервер запущен.
14. Собираем страничку
Теперь создадим несколько PHP-файлов, из которых соберем страничку. Перейдем в папку page и создадим четыре файла: index.php , header.php , body.php , footer.php .
Структура простого HTML-документа выглядит следующим образом:
Литература
- Робин Никсон. Создаем динамические веб-сайты с помощью PHP, MySQL, JavaScript, CSS и HTML5;
- Котеров, Симдянов. PHP 7;
- Веллинг, Томсон. Разработка веб-приложений с помощью PHP и MySQL;
Шпаргалки
YouTube-каналы и курсы
Бесплатные курсы на русском языке:
- Основы php с нуля. Новейший курс 2020 – двадцать четыре урока от основ до регулярных выражений и функций;
- Базовый курс по PHP 7 – узнаете про базовые понятия, GET-параметры, методы, функции и ООП;
- Учим PHP за 1 Час – основы за полтора часа;
- Изучение PHP для начинающих – научитесь работать с массивами, подключать файлы, обрабатывать формы, работать с куки и базой данных MySQL;
- Уроки PHP 7 – много уроков по ООП;
- PHP для начинающих – курс на Stepik для начинающих разработчиков, не требует специальных знаний;
- PHP – первое знакомство – азы программирования на PHP (Stepik).
PHP в «Библиотеке Программиста»
- подписывайтесь на тег PHP , чтобы получать уведомления о новых статьях;
- телеграм-канал «Библиотека пхпшника»;
- книги по программированию в нашем телеграм-канале «Книги для программистов».
Итог
- вы познакомились с синтаксисом PHP и типами данных;
- узнали, как работают условные операторы и циклы;
- запустили веб-сервер в Ubuntu и Windows;
- собрали страничку HTML из файлов PHP.
Веб-парсинг на PHP: пошаговое руководство
Не знаете, как парсить веб-страницы с помощью PHP? Это единственное руководство, которое вам понадобится!
Зачем использовать PHP
На PHP в настоящее время работает около 40% веб-ресурсов, включая такие сайты, как WordPress и Slack. Это один из самых популярных языков сценариев на стороне сервера, когда речь идет о веб-разработке. Для тех, кто работает с MySQL, их базы данных тесно связаны. Это относительно простой язык для изучения, с хорошей документацией и библиотеками, которые могут сократить время разработки.
Как начать работать с PHP
В этом руководстве мы представим метод ручного парсинга веб-страниц, при котором вы отправляете бота на веб-сервер и собираете данные, используя PHP в качестве основного языка программирования. Это отличается от использования полностью автоматизированного инструмента сбора данных, который может упростить и оптимизировать процесс.
Веб-парсер будет работать, отправляя HTTP-запрос на сервер, а затем собирая код веб-сайта. Затем мы научим вас анализировать полученную информацию.
Вот пример фрагмента кода, который может появиться в заголовке вашего сайта для парсинга:
После извлечения этот код необходимо проанализировать, чтобы текст мог быть прочитан и понят аналитиками. В этом примере после анализа вы получите простой текст:
Прежде чем начать, убедитесь, что на вашем компьютере установлен PHP.
Веб-парсинг на PHP за 3 простых шага
Шаг первый: Сбор кода вашего целевого веб-сайта
Начните с ввода следующего кода:
Что касается конвенций кодирования:
- «» используются во всей документации по PHP в начале и в конце команд.
- Вторая строка устанавливает переменную с именем «$ code», которая относится к содержимому рассматриваемого URL-адреса, в этом примере мы будем ориентироваться на: «http://quotes.toscrape.com». Это помогает хранить код URL внутри переменной «$code».
Предпочитаете полностью автоматизированное решение для парсинга?
Шаг второй: Парсинг веб-страницы
Цель работы – собрать все цитаты с этого сайта:

Щелкните правой кнопкой мыши на целевой странице и нажмите «Просмотреть исходный код страницы», откроется новое окно с исходным кодом. В нашем примере все цитаты содержатся в тегах с классом «text» и атрибутом itemprop, также установленным в «text», как показано ниже:

Мы начнем с использования PHP, чтобы избавиться от всего нежелательного текста в коде, за исключением цитат в тегах , а затем выведем его на экран с помощью функции «echo»:
", "<>", $code); $splitCode = explode(" $final = substr($total, 37); echo $final; ?> В строке 2 он заменяет все вхождения «>» в коде на «». Это сделано для того, чтобы его можно было разделить вместе с «, а в строке 11 — закрывающего тега .
Все, что нужно сделать сейчас, это получить текст между этими двумя вхождениями. Для этого создается переменная “i” со значением местоположения переменной открывающего тега. Затем создается переменная для последующего ввода результата. В строке 16 он начинает перебирать каждую букву после открывающего тега, добавляя ее к общему значению, а затем увеличивает переменную «i». После прохождения закрывающего тега цикл останавливается.
Затем он удаляет первые 37 цифр окончательной строки, потому что эти первые 37 цифр находятся в теге, который мы анализируем, — теге . И наконец, он извлекает конечный результат с помощью функции ‘echo’.
Когда вы запустите программу, она будет выглядеть примерно так:
“The world we have created it is a process of our thinking. It cannot be changed without changing our thinking.” Это первая цитата, показанная на сайте, которую мы парсим без какого-либо «неудобного для человека» кода.
Шаг третий: Получение читаемого текста
Вы могли заметить, что он собирает только первое вхождение и ничего после него. Чтобы исправить это, мы можем просто удалить вхождения, которые мы только что вернули, а затем повторять процесс, пока не получим их все. Кроме того, мы можем упростить наш код, поместив процесс парсинга в функцию, чтобы его можно было запускать всякий раз, когда он нам нужен. Попробуйте использовать этот код:
", "<>", $code); $splitCode = explode(" // Run the function, then update splitCode to delete the previous occurance // that it can be repeated for the next quote, then loop through 3 times // (You can change how many times): parseCode($splitCode); $splitCode = array_slice($splitCode, $GLOBALS["closingTag"]-1, NULL, TRUE); parseCode($splitCode); $splitCode = array_slice($splitCode, $GLOBALS["closingTag"]-1, NULL, TRUE); parseCode($splitCode); $splitCode = array_slice($splitCode, $GLOBALS["closingTag"]-1, NULL, TRUE); parseCode($splitCode); ?>Как видите, наш предыдущий код был введен в функцию под названием «parseCode» с параметром «$splitCode», чтобы можно было получить доступ к коду, а затем ‘echo’ результат. Функция «parseCode» запускается в строке 27, а затем в строке 28 наша программа удаляет предыдущее вхождение закрывающего тега, чтобы его можно было повторить. Строки 27 и 28 просто повторяются ~ 3 раза, чтобы программа могла определить шаблон и обнаружить следующее вхождение.
Наконец, мы вводим закрывающий тег как «глобальную переменную» с суперглобальной областью видимости «$ GLOBALS», а в строке 21 мы вводим теги
вокруг каждой строки, которую он возвращает, чтобы он создавал новую строку для каждой новой цитаты. Вот результат:
“The world we have created it is a process of our thinking. It cannot be changed without changing our thinking.” “There are only two ways to live your life. One is as though nothing is a miracle. The Other is as though everything is a miracle.” “Try not to become a man of success. Rather become a man of value.” Результат именно то, что мы искали. Никакого кода, только читаемый текст. Этот процесс можно воспроизвести практически для любого целевого сайта, например, для парсинга на eBay целевых точек данных, таких как цены на продукты, обзоры и SKU (единицы хранения).
Подведем итоги
Использование PHP для поиска целевых данных может быть эффективным, хоть и медленным/ручным процессом. Достойная альтернатива, которую могут захотеть рассмотреть компании, — это покупка готовых к использованию наборов данных. Они экономят время и ресурсы, позволяя вам и вашей команде переключить внимание на расширение бизнеса, обеспечение удовлетворенности клиентов и разработку основных продуктов. Вы всегда можете начать с нашей продвинутой среды разработки веб-парсера. Просто нажмите кнопку ниже, чтобы начать.
Отдаем файлы эффективно с помощью PHP
Метод хорош тем, что работает с коробки. Надо только написать свою функцию отправки файла (немного измененный пример из официальной документации):
function file_force_download($file) < if (file_exists($file)) < // сбрасываем буфер вывода PHP, чтобы избежать переполнения памяти выделенной под скрипт // если этого не сделать файл будет читаться в память полностью! if (ob_get_level()) < ob_end_clean(); >// заставляем браузер показать окно сохранения файла header('Content-Description: File Transfer'); header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename=' . basename($file)); header('Content-Transfer-Encoding: binary'); header('Expires: 0'); header('Cache-Control: must-revalidate'); header('Pragma: public'); header('Content-Length: ' . filesize($file)); // читаем файл и отправляем его пользователю readfile($file); exit; > > Таким способом можно отправлять даже большие файлы, так как PHP будет читать файл и сразу отдавать его пользователю по частям. В документации четко сказано, что readfile() не должен создавать проблемы с памятью.
- Скрипт ждет пока весь файл будет прочитан и отдан пользователю.
- Файл читается в внутренний буфер функции readfile(), размер которого составляет 8кБ (спасибо 2fast4rabbit)
2. Читаем и отправляем файл вручную
Метод использует тот же Drupal при отправке файлов из приватной файловой системы (файлы недоступны напрямую по ссылкам):
function file_force_download($file) < if (file_exists($file)) < // сбрасываем буфер вывода PHP, чтобы избежать переполнения памяти выделенной под скрипт // если этого не сделать файл будет читаться в память полностью! if (ob_get_level()) < ob_end_clean(); >// заставляем браузер показать окно сохранения файла header('Content-Description: File Transfer'); header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename=' . basename($file)); header('Content-Transfer-Encoding: binary'); header('Expires: 0'); header('Cache-Control: must-revalidate'); header('Pragma: public'); header('Content-Length: ' . filesize($file)); // читаем файл и отправляем его пользователю if ($fd = fopen($file, 'rb')) < while (!feof($fd)) < print fread($fd, 1024); >fclose($fd); > exit; > > - Скрипт ждет пока весь файл будет прочитан и отдан пользователю.
- Позволяет сэкономить память сервера
3. Используем модуль веб сервера
3a. Apache
Модуль XSendFile позволяет с помощью специального заголовка передать отправку файла самому Apache. Существуют версии по Unix и Windows, под версии 2.0.*, 2.2.* и 2.4.*
В настройках хоста нужно включить перехват заголовка с помощью директивы:
Также можно указать белый список директорий, файлы в которых могут быть обработаны. Важно: если у Вас сервер на базе Windows путь должен включать букву диска в верхнем регистре.
Описание возможных опций на сайте разработчика: https://tn123.org/mod_xsendfile/
function file_force_download($file) < if (file_exists($file)) < header('X-SendFile: ' . realpath($file)); header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename=' . basename($file)); exit; >> 3b. Nginx
Nginx умеет отправлять файлы из коробки через специальный заголовок.
Для корректной работы нужно запретить доступ к папку напрямую через конфигурационный файл:
Пример отправки файла (файл должен находиться в директории /some/path/protected):
function file_force_download($file) < if (file_exists($file)) < header('X-Accel-Redirect: ' . $file); header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename=' . basename($file)); exit; >> Больше информации на странице официальной документации
- Скрипт завершается сразу после выполнения всех инструкций
- Физически файл отправляется модулем самого веб сервера, а не PHP
- Минимальное потребление памяти и ресурсов сервера
- Максимальное быстродействие
Update: Хабраюзер ilyaplot дает дельный совет, что лучше слать не application/octet-stream , а реальный mime type файла. Например, это позволит браузеру подставить нужные программы в диалог сохранение файла.