- Парсим HTML: Игнорирование подобных вложенных конструкций, или рекурсия в регулярных выражениях
- How To Parse HTML With Regex
- What is Regular Expression?
- Here is how regex can be used for data extraction
- Example
- Python Code
- Parsing HTML with Regex
- What are we going to scrape?
- Let’s Download the data
- Let’s parse the data with Regex
- : This is a literal string that matches the opening tag in the HTML content. : This part of the pattern matches the tag with any additional attributes that might be present in between the opening tag and the closing > . The .*? is a non-greedy quantifier that matches zero or more characters in a non-greedy (minimal) way, meaning it will match as few characters as possible. (.*?) : This part of the pattern uses parentheses to capture the text within the tags. The .*? inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way. : This is a literal string that matches the closing tag in the HTML content. : This is a literal string that matches the closing tag in the HTML content. So, the title_pattern is designed to match the entire HTML element for the book title, including the opening and closing tags, the tag with any attributes, and the text within the tags, which represent the book title. The captured text within the parentheses (.*?) is then used to extract the actual title of the book using the re.findall() function in Python. Now, let’s shift our focus to the price of the book. The price is stored inside the p tag with class price_color . So, we have to create a pattern that starts with and ends with . This one is pretty straightforward compared to the other one. But let me again break it down for you. : This is a literal string that matches the opening tag with the attribute class=»price_color» , which represents the HTML element that contains the book price. (.*?) : This part of the pattern uses parentheses to capture the text within the tags. The .*? inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way. : This is a literal string that matches the closing tag in the HTML content. So, the price_pattern is designed to match the entire HTML element for the book price, including the opening tag with the class=»price_color» attribute, the text within the tags, which represent the book price, and the closing tag. The captured text within the parentheses (.*?) is then used to extract the actual price of the book using the re.findall() function in Python. import requests import re l=[] o=<> # Send a GET request to the website target_url = 'http://books.toscrape.com/' response = requests.get(target_url) # Extract the HTML content from the response html_content = response.text # Define regular expression patterns for title and price title_pattern = r'(.*?)' price_pattern = r'(.*?)' # Find all matches of title and price patterns in the HTML content titles = re.findall(title_pattern, html_content) prices = re.findall(price_pattern, html_content) Since titles and price variables are lists, we have to run a for loop to extract the corresponding titles and prices and store them inside a list l . for i in range(len(titles)): o["Title"]=titles[i] o["Price"]=prices[i] l.append(o) o=<> print(l) This way we will get all the prices and titles of all the books present on the page. Complete Code You can scrape many more things like ratings, product URLs, etc using regex. But for the current scenario, the code will look like this. import requests import re l=[] o=<> # Send a GET request to the website target_url = 'http://books.toscrape.com/' response = requests.get(target_url) # Extract the HTML content from the response html_content = response.text # Define regular expression patterns for title and price title_pattern = r'(.*?)' price_pattern = r'(.*?)' # Find all matches of title and price patterns in the HTML content titles = re.findall(title_pattern, html_content) prices = re.findall(price_pattern, html_content) for i in range(len(titles)): o["Title"]=titles[i] o["Price"]=prices[i] l.append(o) o=<> print(l) Conclusion In this tutorial, we learned how we can quickly parse complex HTML data using regex patterns without using parsing libraries like Beautiful Soup or lxml . In the beginning, you might find regex a little hard to understand but once you start practicing it everything becomes very handy. Regex is a very powerful tool to parse complex data. We wrote an article on web scraping Amazon with Python where we used regex to extract the images of the product. Do read this article for more examples of regex. I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media. Additional Resources Manthan Koolwal My name is Manthan Koolwal and I am the founder of scrapingdog.com. I love creating scraper and seamless data pipelines. Free 1000 API calls of testing. Источник
- tag in the HTML content. : This part of the pattern matches the tag with any additional attributes that might be present in between the opening tag and the closing > . The .*? is a non-greedy quantifier that matches zero or more characters in a non-greedy (minimal) way, meaning it will match as few characters as possible. (.*?) : This part of the pattern uses parentheses to capture the text within the tags. The .*? inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way. : This is a literal string that matches the closing tag in the HTML content. : This is a literal string that matches the closing
- Complete Code
- Conclusion
- Additional Resources
- Manthan Koolwal
Парсим HTML: Игнорирование подобных вложенных конструкций, или рекурсия в регулярных выражениях
Здесь и в других темах, касающихся использования регулярных выражений, очень сильно помогают Regex-помощники — простые программы по тестированию регулярных выражений. О такой программе, написанной автором, можно почитать в статье Codius RegexTester v1.0 — тестирование регулярных выражений. Также там её можно скачать и пользоваться. Абсолютно бесплатно.
Эта статья, обязана своим появлением, возникшей однажды необходимости распарсить HTML. Столкнулся я с этим при работе над статьей Пишем свой Code Highlighter (раскрашиваем код). После недолгих поисков было найдено регулярное выражение, с которым можно было работать —
(?)|.?)*(?(DEPTH)(?!))
. Рассмотрим детально, как оно работает:
Нельзя забывать об установке необходимых параметров: Singleline ( s) — для игнорирования знаков переноса строки, IgnoreCase ( i) — для игнорирования регистра и IgnorePatternWhitespace — для игнорирования пробелов.
Если попытаться очень упрощенно объяснить, что происходит в данном выражении, то получится примерно следующее: в третьей строке при нахождении вложенного тега — параметр глубины увеличивается на 1 ( помещение значения в стек), при нахождении закрывающего тега — параметр глубины уменьшается на 1 ( удаление последнего добавленного значения из стека), и в итоге происходит проверка — если количество открытых тегов равно количеству закрытых тегов ( т. е. стек с именем DEPTH пуст/отсутствует), то вернуть найденное выражение. Пример:
How To Parse HTML With Regex
Regular expressions or regex can help you extract data with ease. In this tutorial, we are going to understand how regular expressions can help you pull a tremendous amount of data from HTML. This tutorial is for all no matter if you are a beginner or an advanced programmer.
What you will learn from this article?
I am assuming that you have already installed Python 3.x on your computer. If not then please install it from here.
Come, let us explore the art of HTML parsing using Python and Regex!
What is Regular Expression?
Regular expression or regex is like a sequence of characters that forms a search pattern that can be used for matching strings. It is a very powerful tool that can be used for text processing, data extraction, etc. It is supported by almost every language including Python, JavaScript, Java, etc. It has great community support which makes searching and matching using Regex super easy.
There are five types of Regular Expressions:

Here is how regex can be used for data extraction
- A sequence of characters is declared to match a pattern in the string.
- In the above sequence of characters, metacharacters like dot . or asterisk * are also often used. Here the dot (.) metacharacter matches any single character, and the asterisk (*) metacharacter represents zero or more occurrences of the preceding character or pattern.
- Quantifiers are also used while making the pattern. For example, the plus (+) quantifier indicates one or more occurrences of the preceding character or pattern, while the question mark (?) quantifier indicates zero or one occurrence.
- Character classes are used in the pattern to match the exact position of the character in the text. For example, the square brackets ([]) can be used to define a character class, such as [a-z] which matches any lowercase letter.
- Once this pattern is ready you can apply it to the HTML code you have downloaded from a website while scraping it.
- After applying the pattern you will get a list of matching strings in Python.
Example
Let’s say we have this text.
text = "I have a cat and a catcher. The cat is cute."
Our task is to search for all occurrences of the word “cat” in the above-given text string.
We are going to execute this task using the re library of Python.
In this case, the pattern will be r’\bcat\b’ . Let me explain step by step breakdown of this pattern.
- \b : This is a word boundary metacharacter, which matches the position between a word character (e.g., a letter or a digit) and a non-word character (e.g., a space or a punctuation mark). It ensures that we match the whole word “cat” and not part of a larger word that contains “cat”.
- cat : This is the literal string “cat” that we want to match in the text.
- \b : Another word boundary metacharacter, which ensures that we match the complete word “cat”. If you want to learn more about word boundaries then read this article.
Python Code
import re text = "I have a cat and a catcher. The cat is cute." pattern = r'\bcat\b' matches = re.findall(pattern, text) print(type(matches))
In this example, we used the re.findall() function from the re module in Python to find all matches of the regular expression pattern \bcat\b in the text string. The function returned a list with the matched word “cat” as the result.
The output will look like this.
This is just a simple example for beginners. Of course, regular expression becomes a little complex with complex HTML code. Now, let’s test our skill in parsing HTML using regex with a more complex example.
Parsing HTML with Regex
We are going to scrape a website in this section. We are going to download HTML code from the target website and then parse data out of it completely using Regex.
For this example, I am going to use this website. We will use two third-party libraries of Python to execute this task.
- requests – Using this library we will make an HTTP connection with the target page. It will help us to download HTML code from the page.
- re – Using this library we can apply regular expression patterns to the string.
What are we going to scrape?
It is always better to decide in advance what exactly we want to scrape from the website.
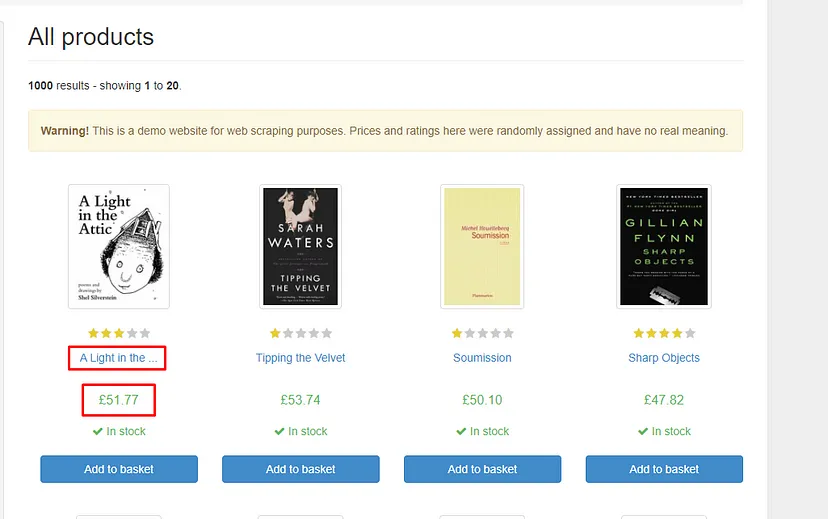
We are going to scrape two things from this page.
Let’s Download the data
I will make a GET request to the target website in order to download all the HTML data from the website. For that, I will be using the requests library.
import requests import re l=[] o=<> # Send a GET request to the website target_url = 'http://books.toscrape.com/' response = requests.get(target_url) # Extract the HTML content from the response html_content = response.text
Here is what we have done in the above code.
- We first downloaded both the libraries requests and re.
- Then empty list l and object o were declared.
- Then the target URL was declared.
- HTTP GET request was made using the requests library.
- All the HTML data is stored inside the html_content variable.
Let’s parse the data with Regex
Now, we have to design a pattern through which we can extract the title and the price of the book from the HTML content. First, let’s focus on the title of the book.
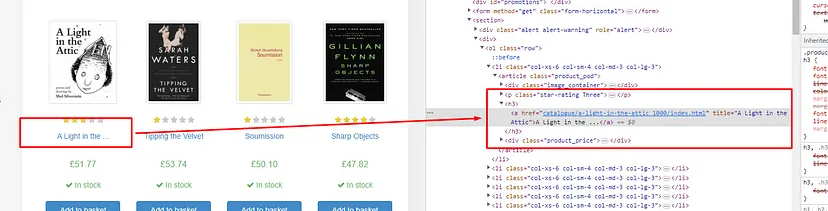
The title is stored inside the h3 tag . Then inside there is a a tag which holds the title. So, the title pattern should look like this.
I know you might be wondering how I created this pattern, right? Let me explain to you this pattern by breaking it down.
-
: This is a literal string that matches the opening
tag in the HTML content.
- : This part of the pattern matches the tag with any additional attributes that might be present in between the opening tag and the closing > . The .*? is a non-greedy quantifier that matches zero or more characters in a non-greedy (minimal) way, meaning it will match as few characters as possible.
- (.*?) : This part of the pattern uses parentheses to capture the text within the tags. The .*? inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way.
- : This is a literal string that matches the closing tag in the HTML content.
- : This is a literal string that matches the closing
tag in the HTML content.
So, the title_pattern is designed to match the entire HTML element for the book title, including the opening and closing tags, the tag with any attributes, and the text within the tags, which represent the book title. The captured text within the parentheses (.*?) is then used to extract the actual title of the book using the re.findall() function in Python.
Now, let’s shift our focus to the price of the book.

The price is stored inside the p tag with class price_color . So, we have to create a pattern that starts with
and ends with
.
This one is pretty straightforward compared to the other one. But let me again break it down for you.
-
: This is a literal string that matches the opening
tag with the attribute class=»price_color» , which represents the HTML element that contains the book price.
- (.*?) : This part of the pattern uses parentheses to capture the text within the
tags. The .*? inside the parentheses is a non-greedy quantifier that captures any characters (except for newline) in a non-greedy (minimal) way.
- : This is a literal string that matches the closing
tag in the HTML content.
So, the price_pattern is designed to match the entire HTML element for the book price, including the opening
tag with the class=»price_color» attribute, the text within the
tags, which represent the book price, and the closing
tag. The captured text within the parentheses (.*?) is then used to extract the actual price of the book using the re.findall() function in Python.
import requests import re l=[] o=<> # Send a GET request to the website target_url = 'http://books.toscrape.com/' response = requests.get(target_url) # Extract the HTML content from the response html_content = response.text # Define regular expression patterns for title and price title_pattern = r'(.*?)' price_pattern = r'(.*?)' # Find all matches of title and price patterns in the HTML content titles = re.findall(title_pattern, html_content) prices = re.findall(price_pattern, html_content)
Since titles and price variables are lists, we have to run a for loop to extract the corresponding titles and prices and store them inside a list l .
for i in range(len(titles)): o["Title"]=titles[i] o["Price"]=prices[i] l.append(o) o=<> print(l)
This way we will get all the prices and titles of all the books present on the page.
Complete Code
You can scrape many more things like ratings, product URLs, etc using regex. But for the current scenario, the code will look like this.
import requests import re l=[] o=<> # Send a GET request to the website target_url = 'http://books.toscrape.com/' response = requests.get(target_url) # Extract the HTML content from the response html_content = response.text # Define regular expression patterns for title and price title_pattern = r'(.*?)' price_pattern = r'(.*?)' # Find all matches of title and price patterns in the HTML content titles = re.findall(title_pattern, html_content) prices = re.findall(price_pattern, html_content) for i in range(len(titles)): o["Title"]=titles[i] o["Price"]=prices[i] l.append(o) o=<> print(l)
Conclusion
In this tutorial, we learned how we can quickly parse complex HTML data using regex patterns without using parsing libraries like Beautiful Soup or lxml . In the beginning, you might find regex a little hard to understand but once you start practicing it everything becomes very handy.
Regex is a very powerful tool to parse complex data. We wrote an article on web scraping Amazon with Python where we used regex to extract the images of the product. Do read this article for more examples of regex.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Manthan Koolwal
My name is Manthan Koolwal and I am the founder of scrapingdog.com. I love creating scraper and seamless data pipelines.
Free 1000 API calls of testing.