- Rukovodstvo
- статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
- Диаграмма рассеяния Seaborn — Учебное пособие и примеры
- Введение Seaborn — одна из наиболее широко используемых библиотек визуализации данных в Python как расширение Matplotlib. Он предлагает простой, интуитивно понятный, но настраиваемый API для визуализации данных. В этом уроке мы рассмотрим, как построить диаграмму рассеяния в Seaborn. Мы рассмотрим простые точечные диаграммы, множественные точечные диаграммы с FacetGrid, а также трехмерные точечные диаграммы. Импортировать данные Мы будем использовать набор данных World Happiness [https://www.kaggle.com/unsdsn/world-happiness] и сравним
- Вступление
- Импортировать данные
- Создайте точечную диаграмму в Seaborn
- Построение множественных точечных диаграмм в Seaborn с помощью FacetGrid
- Построение трехмерной точечной диаграммы в Seaborn
- Настройка точечных диаграмм в Seaborn
- Заключение
- Визуализация данных в Python
- Диаграмма рассеивания Matplotlib — Учебное пособие и примеры
- Импортировать данные
- Постройте диаграмму рассеивания в Matplotlib
- Построение графиков множественного разброса в Matplotlib
- Построение трехмерной диаграммы рассеяния в Matplotlib
- Настройка точечной диаграммы в Matplotlib
- Вывод
Rukovodstvo
статьи и идеи для разработчиков программного обеспечения и веб-разработчиков.
Диаграмма рассеяния Seaborn — Учебное пособие и примеры
Введение Seaborn — одна из наиболее широко используемых библиотек визуализации данных в Python как расширение Matplotlib. Он предлагает простой, интуитивно понятный, но настраиваемый API для визуализации данных. В этом уроке мы рассмотрим, как построить диаграмму рассеяния в Seaborn. Мы рассмотрим простые точечные диаграммы, множественные точечные диаграммы с FacetGrid, а также трехмерные точечные диаграммы. Импортировать данные Мы будем использовать набор данных World Happiness [https://www.kaggle.com/unsdsn/world-happiness] и сравним
Вступление
Seaborn — одна из наиболее широко используемых библиотек визуализации данных в Python как расширение Matplotlib . Он предлагает простой, интуитивно понятный, но настраиваемый API для визуализации данных.
В этом уроке мы рассмотрим, как построить диаграмму рассеяния в Seaborn . Мы рассмотрим простые точечные диаграммы, множественные точечные диаграммы с FacetGrid, а также трехмерные точечные диаграммы.
Импортировать данные
Мы воспользуемся набором данных World Happiness и сравним показатель счастья с различными характеристиками, чтобы увидеть, что влияет на восприятие счастья в мире:
import pandas as pd df = pd.read_csv('worldHappiness2016.csv') Создайте точечную диаграмму в Seaborn
Теперь, когда набор данных загружен, давайте импортируем PyPlot, который мы будем использовать для отображения графика, а также Seaborn. Построим график оценки счастья в зависимости от экономики страны (ВВП на душу населения) :
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd df = pd.read_csv('worldHappiness2016.csv') sns.scatterplot(data = df, x = "Economy (GDP per Capita)", y = "Happiness Score") plt.show() Seaborn упрощает построение базовых графиков, например диаграмм рассеяния. Нам не нужно возиться с объектом Figure Axes или настраивать что-либо, хотя мы можем, если захотим. Здесь мы предоставили df в качестве data и предоставили функции, которые мы хотим визуализировать, в качестве аргументов x и y
Они должны соответствовать данным, представленным в наборе данных, и метками по умолчанию будут их имена. Мы настроим это в следующем разделе.
Теперь, если мы запустим этот код, нас встретят:
Здесь существует сильная положительная корреляция между экономикой (ВВП на душу населения) и ощущением счастья жителей страны / региона.
Построение множественных точечных диаграмм в Seaborn с помощью FacetGrid
Если вы хотите сравнить более одной переменной с другой, например — среднюю продолжительность жизни, а также оценку счастья в сравнении с экономикой или любые ее вариации, нет необходимости создавать для этого трехмерный график.
Хотя существуют 2D-графики, которые визуализируют корреляции между более чем двумя переменными, некоторые из них не совсем подходят для начинающих.
Seaborn позволяет нам FacetGrid объект FacetGrid, который мы можем использовать для фасетирования данных и построения нескольких связанных графиков, один рядом с другим.
Давайте посмотрим, как это сделать:
import matplotlib.pyplot as plt import pandas as pd import seaborn as sns df = pd.read_csv('worldHappiness2016.csv') grid = sns.FacetGrid(df, col = "Region", hue = "Region", col_wrap=5) grid.map(sns.scatterplot, "Economy (GDP per Capita)", "Health (Life Expectancy)") grid.add_legend() plt.show() Здесь мы создали FacetGrid , передав ему наши данные ( df ). Указав аргумент col «Region» , мы сказали Seaborn, что хотим разбить данные на регионы и построить диаграмму рассеяния для каждого региона в наборе данных.
Мы также назначили hue в зависимости от региона, поэтому каждый регион имеет свой цвет. Наконец, мы установили аргумент col_wrap 5 чтобы весь рисунок не был слишком широким — он разбивается на каждые 5 столбцов в новую строку.
К этому объекту grid map() наши аргументы. В частности, мы указали sns.scatterplot как тип графика, который нам нужен, а также x и y мы хотим отобразить на этих графиках разброса.
В результате получается 10 различных графиков разброса, каждый со связанными x и y , разделенными по регионам.
В конце мы также добавили легенду, чтобы помочь идентифицировать цвета.
Построение трехмерной точечной диаграммы в Seaborn
К сожалению, в Seaborn нет встроенных функций 3D. Это расширение Matplotlib и полагается на него для тяжелой работы в 3D. Тем не менее, мы можем стилизовать 3D-график Matplotlib с помощью Seaborn.
Давайте зададим стиль с помощью Seaborn и визуализируем трехмерный график рассеяния счастья, экономики и здоровья:
import matplotlib.pyplot as plt import pandas as pd import seaborn as sns from mpl_toolkits.mplot3d import Axes3D df = pd.read_csv('2016.csv') sns.set(style = "darkgrid") fig = plt.figure() ax = fig.add_subplot(111, projection = '3d') x = df['Happiness Score'] y = df['Economy (GDP per Capita)'] z = df['Health (Life Expectancy)'] ax.set_xlabel("Happiness") ax.set_ylabel("Economy") ax.set_zlabel("Health") ax.scatter(x, y, z) plt.show() Выполнение этого кода приводит к интерактивной трехмерной визуализации, которую мы можем панорамировать и исследовать в трехмерном пространстве, стилизованной под график Сиборна:
Настройка точечных диаграмм в Seaborn
Используя Seaborn, легко настраивать различные элементы создаваемых вами сюжетов. Например, вы можете установить hue и size каждого маркера на точечной диаграмме.
Давайте изменим некоторые параметры и посмотрим, как будет выглядеть график после внесения изменений:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd df = pd.read_csv('2016.csv') sns.scatterplot(data = df, x = "Economy (GDP per Capita)", y = "Happiness Score", hue = "Region", size = "Freedom") plt.show() Здесь мы установили hue на Region что означает, что данные из разных регионов будут иметь разные цвета. Кроме того, мы установили size пропорциональный функции свободы . Чем выше коэффициент свободы, тем крупнее точки:
Или вы можете установить фиксированный размер для всех маркеров, а также цвет:
sns.scatterplot(data = df, x = "Economy (GDP per Capita)", y = "Happiness Score", hue = "red", size = 5) Заключение
В этом уроке мы рассмотрели несколько способов построения диаграммы рассеяния с использованием Seaborn и Python.
Если вас интересует визуализация данных и вы не знаете, с чего начать, обязательно ознакомьтесь с нашим комплектом книг по визуализации данных в Python :
Визуализация данных в Python
. Станьте опасными с визуализацией данных
✅ 30-дневная гарантия возврата денег без вопросов
✅ от начального до продвинутого
✅ Регулярно обновляется бесплатно (последнее обновление в апреле 2021 г.)
✅ Обновлено с бонусными ресурсами и руководствами . . .
Визуализация данных в Python с помощью Matplotlib и Pandas — это книга, предназначенная для абсолютных новичков в работе с Pandas и Matplotlib с базовыми знаниями Python и позволяющая им создать прочную основу для расширенной работы с этими библиотеками — от простых графиков до анимированных трехмерных графиков с интерактивными кнопки.
Он служит подробным руководством, которое научит вас всему, что вам нужно знать о Pandas и Matplotlib, в том числе о том, как создавать типы графиков, которые не встроены в саму библиотеку.
Книга «Визуализация данных в Python» , книга для начинающих и средних разработчиков Python, проведет вас через простые манипуляции с данными с помощью Pandas, охватит основные библиотеки построения графиков, такие как Matplotlib и Seaborn, и покажет, как использовать преимущества декларативных и экспериментальных библиотек, таких как Altair. В частности, на протяжении 11 глав эта книга охватывает 9 библиотек Python: Pandas, Matplotlib, Seaborn, Bokeh, Altair, Plotly, GGPlot, GeoPandas и VisPy.
Он служит уникальным практическим руководством по визуализации данных в виде множества инструментов, которые вы можете использовать в своей карьере.
Licensed under CC BY-NC-SA 4.0
Диаграмма рассеивания Matplotlib — Учебное пособие и примеры
Matplotlib — одна из наиболее широко используемых библиотек визуализации данных в Python. От простых до сложных визуализаций — это библиотека для большинства.
В этом уроке мы рассмотрим, как построить график рассеивания в Matplotlib.
Импортировать данные
Мы будем использовать набор данных Ames Housing и визуализировать корреляции между объектами из него.
Давайте импортируем Pandas и загрузим набор данных:
import pandas as pd df = pd.read_csv('AmesHousing.csv') Постройте диаграмму рассеивания в Matplotlib
Теперь, когда набор данных загружен, давайте импортируем Matplotlib, определимся с функциями, которые мы хотим визуализировать, и построим диаграмму рассеивания:
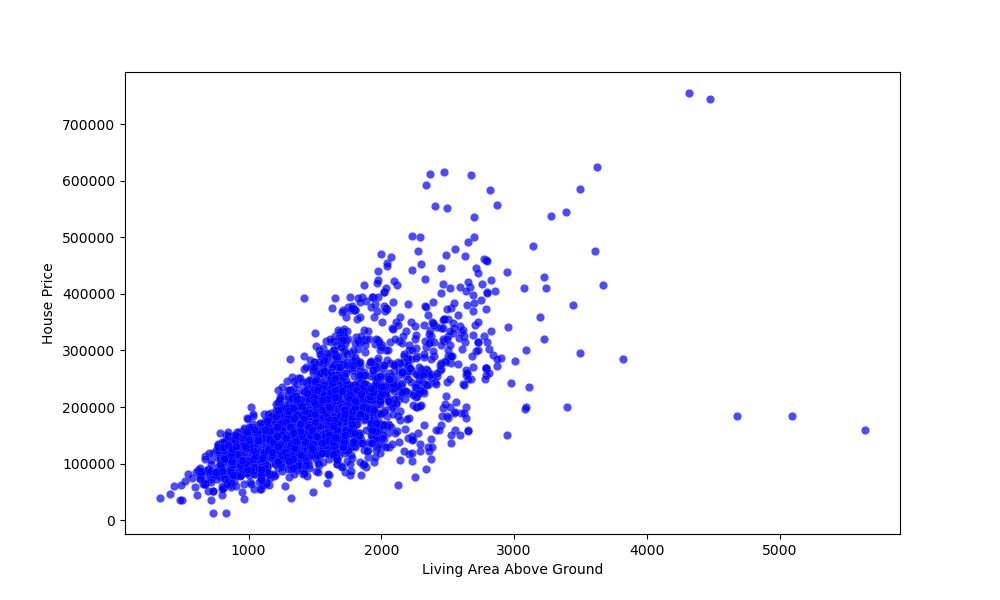
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(figsize=(10, 6)) ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice']) plt.xlabel("Living Area Above Ground") plt.ylabel("House Price") plt.show() Здесь мы создали график, используя экземпляр PyPlot, и установили размер фигуры. Используя возвращенный объект Axes , который возвращается из функции subplots() , мы вызвали функцию scatter() .
Мы должны поставить аргументы x и y , которые мы хотели бы использовать, чтобы заполнить участок. Выполнение этого кода приводит к:
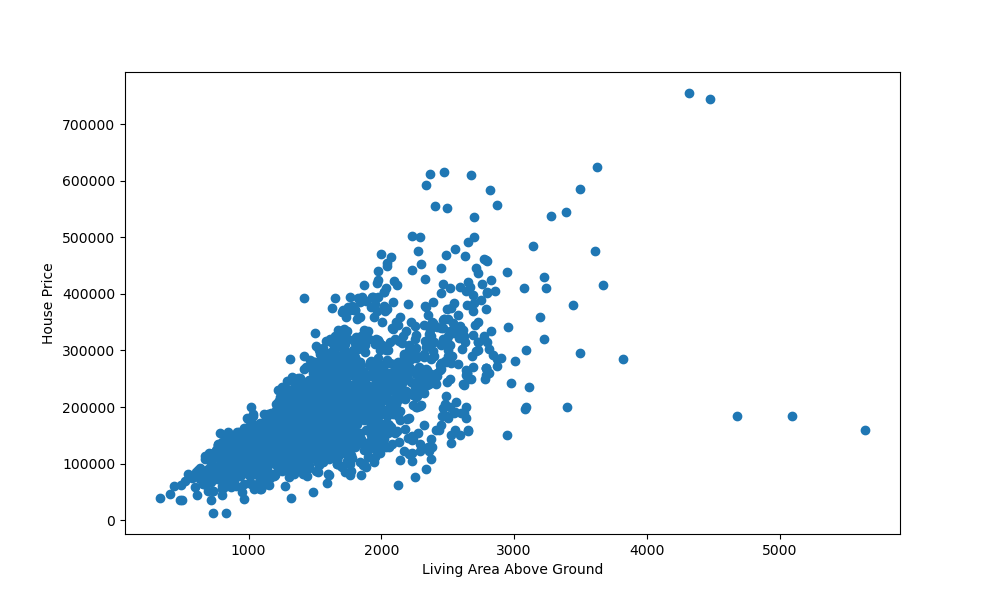
Мы также установили метки x и y, чтобы указать, что представляют собой переменные. Между этими двумя переменными существует явная положительная корреляция. Чем больше площадь над землей, тем выше была цена дома.
Есть несколько отклонений, но подавляющее большинство следует этой гипотезе.
Построение графиков множественного разброса в Matplotlib
Если вы хотите сравнить более одной переменной с другой, например — проверьте корреляцию между общим качеством дома и продажной ценой, а также площадью над уровнем земли — нет необходимости создавать трехмерный график для этого.
Хотя существуют 2D-графики, которые визуализируют корреляции между более чем двумя переменными, некоторые из них не совсем подходят для начинающих.
Самый простой способ сделать это — построить два участка: на одном мы построим график площади над уровнем земли в зависимости от продажной цены, а на другом — общее качество в зависимости от продажной цены.
Давайте посмотрим, как это сделать:
import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('AmesHousing.csv') fig, ax = plt.subplots(2, figsize=(10, 6)) ax[0].scatter(x = df['Gr Liv Area'], y = df['SalePrice']) ax[0].set_xlabel("Living Area Above Ground") ax[0].set_ylabel("House Price") ax[1].scatter(x = df['Overall Qual'], y = df['SalePrice']) ax[1].set_xlabel("Overall Quality") ax[1].set_ylabel("House Price") plt.show() Здесь мы вызвали plt.subplots() , с параметром 2 , чтобы указать, что мы хотели бы создать экземпляры двух подзаголовков на рисунке.
Мы можем получить к ним доступ через экземпляр Axes — ax . ax[0] относится к осям первого подзаголовка, а ax[1] относится к осям второго подзаголовка.
Здесь мы вызвали функцию scatter() для каждого из них, снабдив их метками. Выполнение этого кода приводит к:
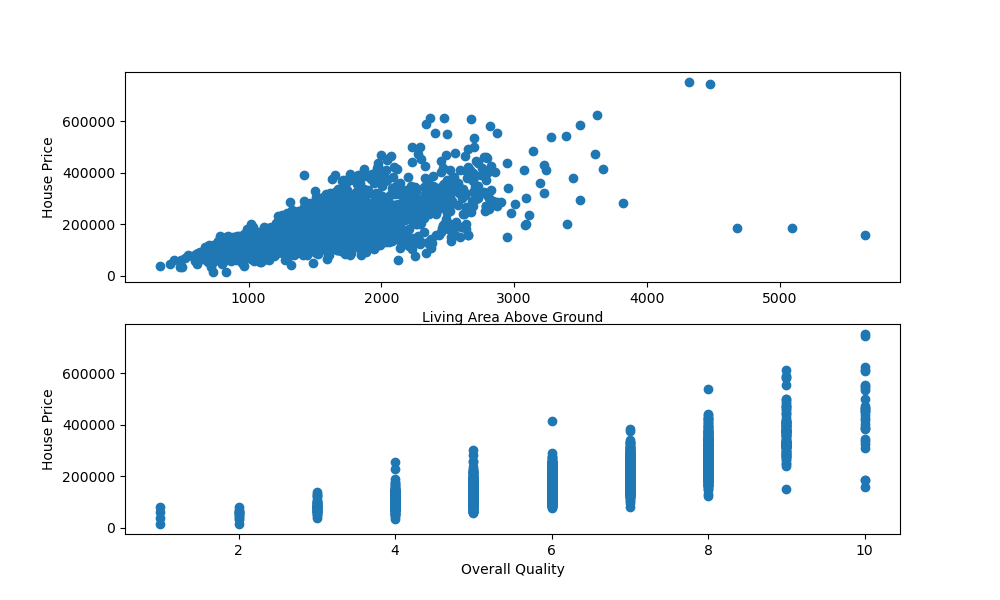
Построение трехмерной диаграммы рассеяния в Matplotlib
Если вы не хотите визуализировать это в двух отдельных подзаголовках, вы можете построить корреляцию между этими переменными в 3D. Matplotlib имеет встроенную функцию трехмерного построения графиков, так что сделать это очень просто.
Во-первых, нам нужно импортировать класс Axes3D из mpl_toolkits.mplot3d . Этот специальный тип необходим для 3D-визуализации. С его помощью мы можем передать другой аргумент z — это третья функция, которую мы хотели бы визуализировать.
Давайте продолжим и импортируем объект Axes3D и построим диаграмму рассеяния для трех предыдущих функций:
import matplotlib.pyplot as plt import pandas as pd from mpl_toolkits.mplot3d import Axes3D df = pd.read_csv('AmesHousing.csv') fig = plt.figure() ax = fig.add_subplot(111, projection = '3d') x = df['SalePrice'] y = df['Gr Liv Area'] z = df['Overall Qual'] ax.scatter(x, y, z) ax.set_xlabel("Sale price") ax.set_ylabel("Living area above ground level") ax.set_zlabel("Overall quality") plt.show() Запуск этого кода приводит к интерактивной трехмерной визуализации, которую мы можем панорамировать и исследовать в трехмерном пространстве:
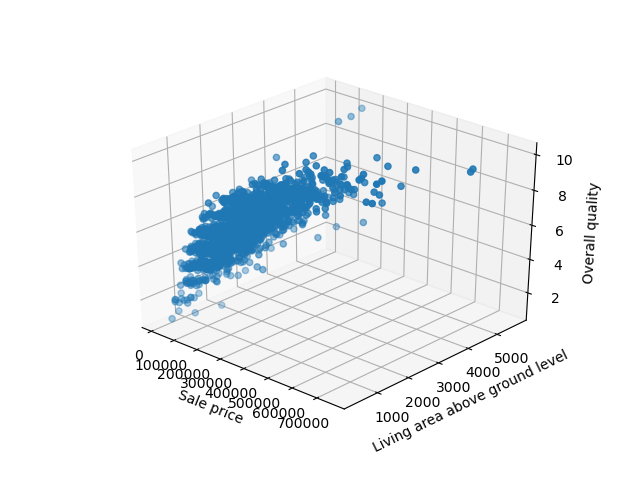
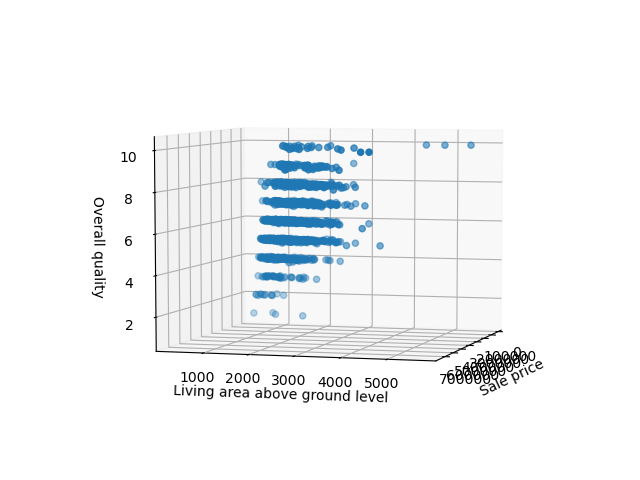
Настройка точечной диаграммы в Matplotlib
Вы можете изменить внешний вид графика, снабдив функцию scatter() дополнительными аргументами, такими как color , alpha и т.д.:
ax.scatter(x = df['Gr Liv Area'], y = df['SalePrice'], color = "blue", edgecolors = "white", linewidths = 0.1, alpha = 0.7) Выполнение этого кода приведет к:
Вывод
В этом руководстве мы рассмотрели несколько способов построения графика рассеяния с использованием Matplotlib и Python