Requests-HTML: HTML Parsing for Humans!¶
This library intends to make parsing HTML (e.g. scraping the web) as simple and intuitive as possible.
When using this library you automatically get:
- Full JavaScript support!
- CSS Selectors (a.k.a jQuery-style, thanks to PyQuery).
- XPath Selectors, for the faint at heart.
- Mocked user-agent (like a real web browser).
- Automatic following of redirects.
- Connection–pooling and cookie persistence.
- The Requests experience you know and love, with magical parsing abilities.
Installation¶
$ pipenv install requests-html ✨🍰✨
Only later versions of Python 3 are supported.
Tutorial & Usage¶
Make a GET request to ‘python.org’, using Requests:
>>> from requests_html import HTMLSession >>> session = HTMLSession() >>> r = session.get('https://python.org/')
Grab a list of all links on the page, as–is (anchors excluded):
Grab a list of all links on the page, in absolute form (anchors excluded):
Select an Element with a CSS Selector (learn more):
>>> about = r.html.find('#about', first=True)
Grab an Element ’s text contents:
>>> print(about.text) About Applications Quotes Getting Started Help Python Brochure
Introspect an Element ’s attributes (learn more):
Render out an Element ’s HTML:
Select an Element list within an Element :
Search for links within an element:
Search for text on the page:
>>> r.html.search('Python is a <> language')[0] programming
More complex CSS Selector example (copied from Chrome dev tools):
>>> r = session.get('https://github.com/') >>> sel = 'body > div.application-main > div.jumbotron.jumbotron-codelines > div > div > div.col-md-7.text-center.text-md-left > p' >>> print(r.html.find(sel, first=True).text) GitHub is a development platform inspired by the way you work. From open source to business, you can host and review code, manage projects, and build software alongside millions of other developers.
JavaScript Support¶
Let’s grab some text that’s rendered by JavaScript:
>>> r = session.get('http://python-requests.org/') >>> r.html.render() >>> r.html.search('Python 2 will retire in only months!')['months'] ''
Note, the first time you ever run the render() method, it will download Chromium into your home directory (e.g. ~/.pyppeteer/ ). This only happens once.
Using without Requests¶
You can also use this library without Requests:
>>> from requests_html import HTML >>> doc = """""" >>> html = HTML(html=doc) >>> html.links
API Documentation¶
Main Classes¶
These classes are the main interface to requests-html :
class requests_html. HTML ( *, url=’https://example.org/’, html, default_encoding=’utf-8′ ) → None¶
An HTML document, ready for parsing.
All found links on page, in absolute form (learn more).
The base URL for the page. Supports the tag (learn more).
The encoding string to be used, extracted from the HTML and HTMLResponse headers.
find ( selector: str, first: bool = False, _encoding: str = None ) ¶
Given a CSS Selector, returns a list of Element objects.
See W3School’s CSS Selectors Reference for more details.
If first is True , only returns the first Element found.
The full text content (including links) of the Element or HTML ..
Unicode representation of the HTML content (learn more).
All found links on page, in as–is form.
lxml representation of the Element or HTML .
PyQuery representation of the Element or HTML .
Bytes representation of the HTML content (learn more).
render ( retries: int = 8, script: str = None, scrolldown=False, sleep: int = 0 ) ¶
Reloads the response in Chromium, and replaces HTML content with an updated version, with JavaScript executed.
If scrolldown is specified, the page will scrolldown the specified number of times, after sleeping the specified amount of time (e.g. scrolldown=10, sleep=1 ).
If just sleep is provided, the rendering will wait n seconds, before returning.
If script is specified, it will execute the provided JavaScript at runtime. Example:
script = """ () => return width: document.documentElement.clientWidth, height: document.documentElement.clientHeight, deviceScaleFactor: window.devicePixelRatio, > > """
Returns the return value of the executed script , if any is provided:
Warning: the first time you run this method, it will download Chromium into your home directory ( ~/.pyppeteer ).
search ( template: str ) → parse.Result¶
Searches the Element for the given parse template.
search_all ( template: str ) → parse.Result¶
Searches the Element (multiple times) for the given parse template.
Unicode representation of the HTML content (learn more).
The text content of the Element or HTML .
xpath ( selector: str, first: bool = False, _encoding: str = None ) ¶
Given an XPath selector, returns a list of Element objects.
If a sub-selector is specified (e.g. //a/@href ), a simple list of results is returned.
See W3School’s XPath Examples for more details.
If first is True , only returns the first Element found.
class requests_html. Element ( *, element, url, default_encoding ) → None¶
All found links on page, in absolute form (learn more).
Returns a dictionary of the attributes of the Element (learn more).
The base URL for the page. Supports the tag (learn more).
The encoding string to be used, extracted from the HTML and HTMLResponse headers.
find ( selector: str, first: bool = False, _encoding: str = None ) ¶
Given a CSS Selector, returns a list of Element objects.
See W3School’s CSS Selectors Reference for more details.
If first is True , only returns the first Element found.
The full text content (including links) of the Element or HTML ..
Unicode representation of the HTML content (learn more).
All found links on page, in as–is form.
lxml representation of the Element or HTML .
PyQuery representation of the Element or HTML .
Bytes representation of the HTML content (learn more).
search ( template: str ) → parse.Result¶
Searches the Element for the given parse template.
search_all ( template: str ) → parse.Result¶
Searches the Element (multiple times) for the given parse template.
Unicode representation of the HTML content (learn more).
The text content of the Element or HTML .
xpath ( selector: str, first: bool = False, _encoding: str = None ) ¶
Given an XPath selector, returns a list of Element objects.
If a sub-selector is specified (e.g. //a/@href ), a simple list of results is returned.
See W3School’s XPath Examples for more details.
If first is True , only returns the first Element found.
Utility Functions¶
Returns a random user-agent, if not requested one of a specific style. Defaults to a Chrome-style User-Agent.
HTML Sessions¶
These sessions are for making HTTP requests:
class requests_html. HTMLSession ( mock_browser=True, *args, **kwargs ) ¶
A consumable session, for cookie persistence and connection pooling, amongst other things.
Closes all adapters and as such the session
Sends a DELETE request. Returns Response object.
Sends a GET request. Returns Response object.
Returns the appropriate connection adapter for the given URL.
| Return type: | requests.adapters.BaseAdapter |
|---|
get_redirect_target ( resp ) ¶
Receives a Response. Returns a redirect URI or None
Sends a HEAD request. Returns Response object.
Check the environment and merge it with some settings.
| Return type: | dict |
|---|
mount ( prefix, adapter ) ¶
Registers a connection adapter to a prefix.
Adapters are sorted in descending order by prefix length.
Sends a OPTIONS request. Returns Response object.
Sends a PATCH request. Returns Response object.
- url – URL for the new Request object.
- data – (optional) Dictionary, bytes, or file-like object to send in the body of the Request .
- **kwargs – Optional arguments that request takes.
Sends a POST request. Returns Response object.
- url – URL for the new Request object.
- data – (optional) Dictionary, bytes, or file-like object to send in the body of the Request .
- json – (optional) json to send in the body of the Request .
- **kwargs – Optional arguments that request takes.
Constructs a PreparedRequest for transmission and returns it. The PreparedRequest has settings merged from the Request instance and those of the Session .
| Parameters: | request – Request instance to prepare with this session’s settings. |
|---|---|
| Return type: | requests.PreparedRequest |
put ( url, data=None, **kwargs ) ¶
Sends a PUT request. Returns Response object.
- url – URL for the new Request object.
- data – (optional) Dictionary, bytes, or file-like object to send in the body of the Request .
- **kwargs – Optional arguments that request takes.
When being redirected we may want to strip authentication from the request to avoid leaking credentials. This method intelligently removes and reapplies authentication where possible to avoid credential loss.
rebuild_method ( prepared_request, response ) ¶
When being redirected we may want to change the method of the request based on certain specs or browser behavior.
rebuild_proxies ( prepared_request, proxies ) ¶
This method re-evaluates the proxy configuration by considering the environment variables. If we are redirected to a URL covered by NO_PROXY, we strip the proxy configuration. Otherwise, we set missing proxy keys for this URL (in case they were stripped by a previous redirect).
This method also replaces the Proxy-Authorization header where necessary.
| Return type: | dict |
|---|
resolve_redirects ( resp, req, stream=False, timeout=None, verify=True, cert=None, proxies=None, yield_requests=False, **adapter_kwargs ) ¶
Receives a Response. Returns a generator of Responses or Requests.
Send a given PreparedRequest.
| Return type: | requests.Response |
|---|
Как получить полный html код страницы с помощью requests.get()?

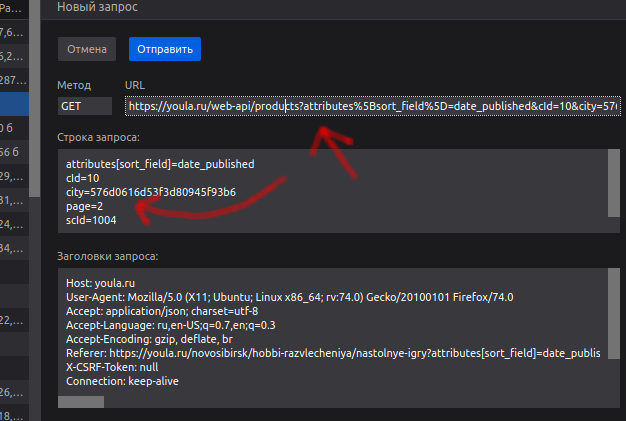
Откройте инструменты разработчика и полистайте страницу вниз. Обратите внимание на url и параметр page:
не могли бы показать полный скриншот или сделать похожий?
возникла проблема с парсингом страниц вида https://www.vfbank.ru/fizicheskim-licam/monety/pam.
'BX-ACTION-TYPE':'get_dynamic', 'BX-CACHE-MODE':'HTMLCACHE',на выходе получите что-то похожее на json. Эти данные я прогнал через online сервисы, они определили что это json, только с кучей ошибок. Я немного схитрил, и вырезал нужные мне данные и удалил из них не нужные символы.
import requests from bs4 import BeautifulSoup headers = url = 'https://www.vfbank.ru/fizicheskim-licam/monety/pamyatnye-monety/' def parsing(html): start = html.find('bxdynamic_moneti_inner') end = html.find("'HASH':'844584f9f4f7',") data = html[start:end].replace('\\n','').replace('\\','') soup = BeautifulSoup(data,"html.parser") coins = soup.find_all('div',class_='col col--lg-6') for coin in coins: title = coin.find('a').text.strip() _id = coin.find('a').get('data-id') print(title,_id) response = requests.get(url,headers=headers) parsing(response.text) 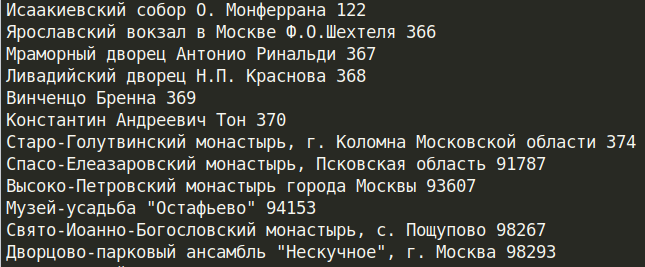
sunsexsurf, Теперь, зная id монеты, сможем узнать всю информацию о ней, просто передав get-запрос по адресу
https://www.vfbank.ru/local/ajax/moneta.php?ELEMENT_ID=import requests from bs4 import BeautifulSoup headers = url = 'https://www.vfbank.ru/local/ajax/moneta.php?ELEMENT_ID=' def parsing(_id): response = requests.get(url+_id,headers=headers) soup = BeautifulSoup(response.text,"html.parser") title = soup.find('h3').text.strip() full_content = soup.find('div',class_='coin-content__info coin-content-info coin-content-info--b-offset') contents = full_content.find_all('div',class_='coin-content-info__item coin-content-info__item--b-offset') print(title+'\n') for content in contents: _key = content.find('span',class_='coin-content-info__key').text.strip() val = content.find('span',class_='coin-content-info__val').text.strip() print(_key+' = '+ val) parsing('370') # id монеты