- Saved searches
- Use saved searches to filter your results more quickly
- License
- andrewgross/json2parquet
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.rst
- About
- JSON to parquet : How to perform in Python with example ?
- JSON to parquet ( Conversion ) –
- Step 1: Prerequisite JSON object creation –
- Step 2: Converting JSON to dataframe –
- Step 3 : Dataframe to parquet file –
- Limitations –
- JSON to Parquet in Pyspark –
- Conclusion –
- Join our list
- How to convert a json result to parquet in python?
- Method 1: Using PyArrow
- Converting JSON to Parquet using PyArrow
- Method 2: Using Pandas and Fastparquet
- Method 3: Using Dask
- How to Convert a JSON Result to Parquet in Python?
- Step 1: Import Required Libraries
- Step 2: Read JSON Data
- Step 3: Convert JSON to Parquet
- Step 4: Verify the Parquet File
- Conclusion
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Convert JSON files to Parquet using PyArrow
License
andrewgross/json2parquet
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.rst
This library wraps pyarrow to provide some tools to easily convert JSON data into Parquet format. It is mostly in Python. It iterates over files. It copies the data several times in memory. It is not meant to be the fastest thing available. However, it is convenient for smaller data sets, or people who don’t have a huge issue with speed.
conda install -c conda-forge json2parquet
Here’s how to load a random JSON dataset.
from json2parquet import convert_json # Infer Schema (requires reading dataset for column names) convert_json(input_filename, output_filename) # Given columns convert_json(input_filename, output_filename, ["my_column", "my_int"]) # Given columns and custom field names field_aliases = 'my_column': 'my_updated_column_name', "my_int": "my_integer"> convert_json(input_filename, output_filename, ["my_column", "my_int"], field_aliases=field_aliases) # Given PyArrow schema import pyarrow as pa schema = pa.schema([ pa.field('my_column', pa.string), pa.field('my_int', pa.int64), ]) convert_json(input_filename, output_filename, schema)
You can also work with Python data structures directly
from json2parquet import load_json, ingest_data, write_parquet, write_parquet_dataset # Loading JSON to a PyArrow RecordBatch (schema is optional as above) load_json(input_filename, schema) # Working with a list of dictionaries ingest_data(input_data, schema) # Working with a list of dictionaries and custom field names field_aliases = 'my_column': 'my_updated_column_name', "my_int": "my_integer"> ingest_data(input_data, schema, field_aliases) # Writing Parquet Files from PyArrow Record Batches write_parquet(data, destination) # You can also pass any keyword arguments that PyArrow accepts write_parquet(data, destination, compression='snappy') # You can also write partitioned date write_parquet_dataset(data, destination_dir, partition_cols=["foo", "bar", "baz"])
If you know your schema, you can specify custom datetime formats (only one for now). This formatting will be ignored if you don’t pass a PyArrow schema.
from json2parquet import convert_json # Given PyArrow schema import pyarrow as pa schema = pa.schema([ pa.field('my_column', pa.string), pa.field('my_int', pa.int64), ]) date_format = "%Y-%m-%dT%H:%M:%S.%fZ" convert_json(input_filename, output_filename, schema, date_format=date_format)
Although json2parquet can infer schemas, it has helpers to pull in external ones as well
from json2parquet import load_json from json2parquet.helpers import get_schema_from_redshift # Fetch the schema from Redshift (requires psycopg2) schema = get_schema_from_redshift(redshift_schema, redshift_table, redshift_uri) # Load JSON with the Redshift schema load_json(input_filename, schema)
If you are using this library to convert JSON data to be read by Spark , Athena , Spectrum or Presto make sure you use use_deprecated_int96_timestamps when writing your Parquet files, otherwise you will see some really screwy dates.
- Clone a fork of the library
- Run make setup
- Run make test
- Apply your changes (don’t bump version)
- Add tests if needed
- Run make test to ensure nothing broke
- Submit PR
It is always a struggle to keep documentation correct and up to date. Any fixes are welcome. If you don’t want to clone the repo to work locally, please feel free to edit using Github and to submit Pull Requests via Github’s built in features.
About
Convert JSON files to Parquet using PyArrow
JSON to parquet : How to perform in Python with example ?
JSON to parquet conversion is possible in multiple ways but I prefer via dataframe. Firstly convert JSON to dataframe and then to parquet file. In this article, we will explore the complete same process with an easy example.
JSON to parquet ( Conversion ) –
Let’s break this into steps.
Step 1: Prerequisite JSON object creation –
Here is the code for dummy json creation which we will use for converting into parquet.
Step 2: Converting JSON to dataframe –
We will first import pandas framework and then load the json. After it, We will convert the same into pandas dataframe.
, "1":< "Identity": "Tom", "Age": "14" >, "2": < "Identity": "Mac", "Age":"11" >> ''' df = pd.read_json(record, orient ='index') print(df)
This read_json() function from Pandas helps convert JSON to pandas dataframe.
Step 3 : Dataframe to parquet file –
This is the last step, Here we will create parquet file from dataframe. We can use to_parquet() function for converting dataframe to parquet file. Here is the code for the same.
When we integrate this piece of code with above master code. We get the parquet file.
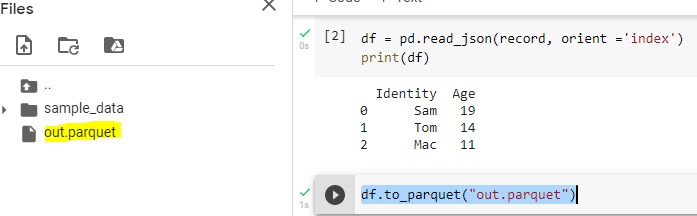
Limitations –
All the JSON does not follow the structure which we can convert to dataframe. Hence this approach will only applicable with JSON format where is convertible to data frame.
JSON to Parquet in Pyspark –
Just like pandas, we can first create Pyspark Dataframe using JSON. IN order to do that here is the code-
df = spark.read.json("sample.json")Once we have pyspark dataframe inplace, we can convert the pyspark dataframe to parquet using below way.
pyspark_df.write.parquet("data.parquet")Conclusion –
Parquet file is a more popular file format for a table-like data structure. Also, it offers fast data processing performance than CSV file format. In the same way, Parquet file format contains the big volume of data than the CSV file format. I hope this article must help our readers, please feel free to put any concerns related to this topic. Same you can either comment or write back to us via email etc. Please subscribe to us for more related topics.
Data Science Learner Team
Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox.
We respect your privacy and take protecting it seriously
Thank you for signup. A Confirmation Email has been sent to your Email Address.
How to convert a json result to parquet in python?
When working with large datasets, it can be beneficial to store and read data in a more efficient format. One popular format for storing and reading large datasets is Parquet. Parquet is a columnar storage format that is optimized for use with big data processing frameworks like Apache Spark and Apache Hive. In this guide, we will show you how to convert a JSON result to Parquet in Python.
Method 1: Using PyArrow
Converting JSON to Parquet using PyArrow
Here’s a step-by-step guide on how to convert a JSON result to Parquet in Python using PyArrow:
import json import pyarrow as pa import pyarrow.parquet as pqwith open('data.json', 'r') as f: data = json.load(f)table = pa.Table.from_pydict(data)pq.write_table(table, 'data.parquet')That’s it! You’ve successfully converted a JSON result to Parquet using PyArrow. Here’s the full code:
import json import pyarrow as pa import pyarrow.parquet as pq with open('data.json', 'r') as f: data = json.load(f) table = pa.Table.from_pydict(data) pq.write_table(table, 'data.parquet')Method 2: Using Pandas and Fastparquet
Here is an example code to convert a JSON result to Parquet in Python using Pandas and Fastparquet:
import pandas as pd import fastparquet as fp json_data = '[, ]' df = pd.read_json(json_data) fp.write('output.parquet', df)In this example, we first load the JSON data into a Pandas DataFrame using the read_json function. We then use the write function from Fastparquet to write the DataFrame to a Parquet file. The write function automatically infers the schema of the DataFrame and writes it to the Parquet file.
If you want to specify the schema manually, you can use the fastparquet.api.ParquetFile class to create a schema object and pass it to the write function:
import pandas as pd import fastparquet as fp from fastparquet.api import ParquetFile, schema_from_pandas json_data = '[, ]' df = pd.read_json(json_data) schema = schema_from_pandas(df) fp.write('output.parquet', df, schema=schema)In this example, we create a schema object using the schema_from_pandas function from Fastparquet. We then pass the schema object to the write function along with the DataFrame.
Overall, the process of converting a JSON result to Parquet in Python using Pandas and Fastparquet involves loading the JSON data into a Pandas DataFrame and then using the write function from Fastparquet to write the DataFrame to a Parquet file. You can optionally specify the schema manually using the schema_from_pandas function and passing it to the write function.
Method 3: Using Dask
Dask is a parallel computing library that can be used to process large datasets in parallel. It is designed to scale up to clusters of thousands of machines, making it an ideal tool for processing big data.
To convert a JSON result to Parquet using Dask, you can follow these steps:
import dask.dataframe as dd import pandas as pdHow to Convert a JSON Result to Parquet in Python?
Parquet is a columnar storage format that is highly efficient for working with large datasets. It is designed to work with a variety of data sources, including JSON. In this guide, we will walk through the steps required to convert a JSON result to Parquet in Python.
Step 1: Import Required Libraries
The first step is to import the required libraries for working with JSON and Parquet formats. We will be using the pandas and pyarrow libraries for this purpose.
import pandas as pd import pyarrow as pa import pyarrow.parquet as pq Step 2: Read JSON Data
Next, we need to read in the JSON data that we want to convert to Parquet. In this example, we will be using a sample JSON file containing information about employees.
json_data = pd.read_json('employees.json') Step 3: Convert JSON to Parquet
Once we have the JSON data loaded, we can convert it to Parquet format using the pyarrow library.
table = pa.Table.from_pandas(json_data) pq.write_table(table, 'employees.parquet') This code creates a PyArrow table from the pandas dataframe and then writes it to a Parquet file named `employees.parquet`.
Step 4: Verify the Parquet File
Finally, we can verify that the Parquet file was created successfully by reading it back into a pandas dataframe and inspecting the data.
parquet_data = pd.read_parquet('employees.parquet') print(parquet_data.head()) This code reads the `employees.parquet` file into a pandas dataframe and then prints the first five rows of data to the console.
Conclusion
In this guide, we have walked through the process of converting a JSON result to Parquet in Python. By following these steps, you can efficiently work with large datasets and take advantage of the benefits that Parquet provides.