File и FileReader
Объект File наследуется от объекта Blob и обладает возможностями по взаимодействию с файловой системой.
Есть два способа его получить.
Во-первых, есть конструктор, похожий на Blob :
new File(fileParts, fileName, [options])- fileParts – массив значений Blob / BufferSource /строки.
- fileName – имя файла, строка.
- options – необязательный объект со свойством:
- lastModified – дата последнего изменения в формате таймстамп (целое число).
Во-вторых, чаще всего мы получаем файл из или через перетаскивание с помощью мыши, или из других интерфейсов браузера. В этом случае файл получает эту информацию из ОС.
Так как File наследует от Blob , у объектов File есть те же свойства плюс:
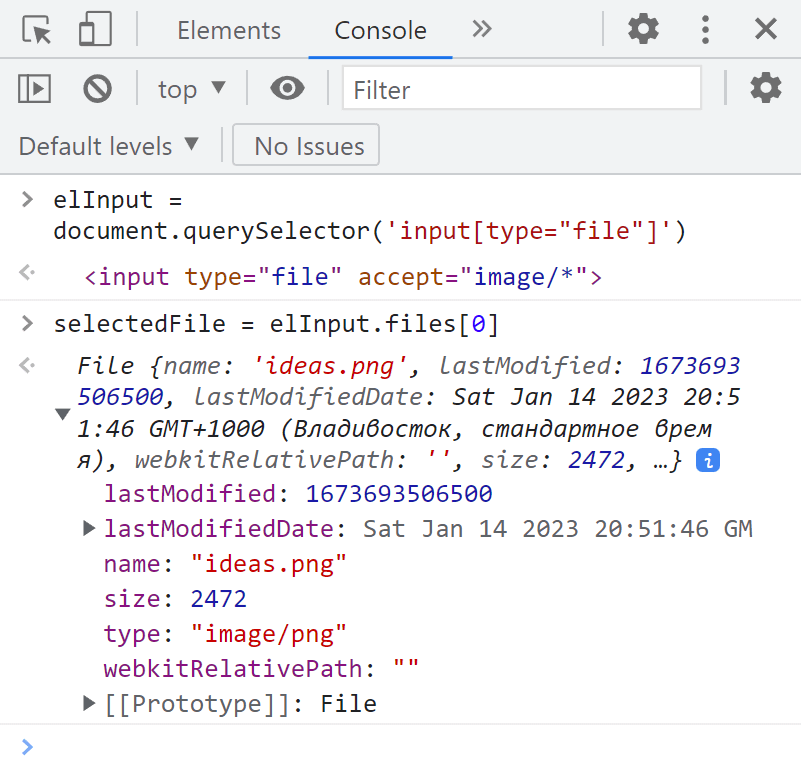
В этом примере мы получаем объект File из :
Через можно выбрать несколько файлов, поэтому input.files – псевдомассив выбранных файлов. Здесь у нас только один файл, поэтому мы просто берём input.files[0] .
FileReader
FileReader объект, цель которого читать данные из Blob (и, следовательно, из File тоже).
Данные передаются при помощи событий, так как чтение с диска может занять время.
let reader = new FileReader(); // без аргументов- readAsArrayBuffer(blob) – считать данные как ArrayBuffer
- readAsText(blob, [encoding]) – считать данные как строку (кодировка по умолчанию: utf-8 )
- readAsDataURL(blob) – считать данные как base64-кодированный URL.
- abort() – отменить операцию.
Выбор метода для чтения зависит от того, какой формат мы предпочитаем, как мы хотим далее использовать данные.
- readAsArrayBuffer – для бинарных файлов, для низкоуровневой побайтовой работы с бинарными данными. Для высокоуровневых операций у File есть свои методы, унаследованные от Blob , например, slice , мы можем вызвать их напрямую.
- readAsText – для текстовых файлов, когда мы хотим получить строку.
- readAsDataURL – когда мы хотим использовать данные в src для img или другого тега. Есть альтернатива – можно не читать файл, а вызвать URL.createObjectURL(file) , детали в главе Blob.
В процессе чтения происходят следующие события:
- loadstart – чтение начато.
- progress – срабатывает во время чтения данных.
- load – нет ошибок, чтение окончено.
- abort – вызван abort() .
- error – произошла ошибка.
- loadend – чтение завершено (успешно или нет).
Когда чтение закончено, мы сможем получить доступ к его результату следующим образом:
Наиболее часто используемые события – это, конечно же, load и error .
Как упоминалось в главе Blob, FileReader работает для любых объектов Blob, а не только для файлов.
Поэтому мы можем использовать его для преобразования Blob в другой формат:
- readAsArrayBuffer(blob) – в ArrayBuffer ,
- readAsText(blob, [encoding]) – в строку (альтернатива TextDecoder ),
- readAsDataURL(blob) – в формат base64-кодированного URL.
Для веб-воркеров доступен синхронный вариант FileReader , именуемый FileReaderSync.
Его методы считывания read* не генерируют события, а возвращают результат, как это делают обычные функции.
Но это только внутри веб-воркера, поскольку задержки в синхронных вызовах, которые возможны при чтении из файла, в веб-воркерах менее важны. Они не влияют на страницу.
Итого
File объекты наследуют от Blob .
Помимо методов и свойств Blob , объекты File также имеют свойства name и lastModified плюс внутреннюю возможность чтения из файловой системы. Обычно мы получаем объекты File из пользовательского ввода, например, через или перетаскиванием с помощью мыши, в событии dragend .
Объекты FileReader могут читать из файла или Blob в одном из трёх форматов:
- Строка ( readAsText ).
- ArrayBuffer ( readAsArrayBuffer ).
- URL в формате base64 ( readAsDataURL ).
Однако, во многих случаях нам не нужно читать содержимое файла. Как и в случае с Blob, мы можем создать короткий URL с помощью URL.createObjectURL(file) и использовать его в теге или
. Таким образом, файл может быть загружен или показан в виде изображения, как часть canvas и т.д.
А если мы собираемся отправить File по сети, то это также легко, поскольку в сетевые методы, такие как XMLHttpRequest или fetch , встроена возможность отсылки File .
Использование FileReader для чтения файлов в JavaScript
В этой статье изучим как использовать FileReader для чтения содержимого файлов в браузере. На практике рассмотрим несколько примеров, как с использованием элемента input, так и посредством Drag’n’Drop.
Что такое FileReader?
FileReader – это объект, который мы можем использовать для чтения содержимого файлов в браузере. При этом делает он это действие асинхронно.
При этом в браузере мы не можем напрямую работать с файловой системой операционной системы (как например в Node.js). В основном это всё то, что пользователь выбрал с помощью элемента или посредством перетаскивания, то есть через механизм Drag’n’Drop.
Например, для того чтобы организовать выбор одного файла с локального устройства нам достаточно всего лишь добавить в HTML-документ следующий код:

После выбора файла мы можем в коде JavaScript обратиться к нему. Осуществляется это через свойство files этого DOM-элемента. Но перед обращением к свойству мы должны сначала получить сам этот элемент в DOM, например, с помощью метода querySelector :
// получим элемент, используя селектор [type="file"] const elemInput = document.querySelector('[type="file"]'); // сохраним в переменную files значение свойства files const files = elemInput.files;Свойство files – это массивоподобный объект FileList . Узнать количество выбранных файлов в files можно с помощью свойства length .
// сохраним количество элементов в files в переменную countFiles const countFiles = files.length;Если мы не выбрали файл, то значение countFiles будет равно 0 . Поэтому перед тем, как обратиться к выбранному файлу нужно проверить, а выбрал ли пользователь файл:
Когда мы выбираем один файл, то он всегда находится в files в позиции 0 . Таким образом чтобы получить его мы должны использовать индекс 0 :
Таким образом, обращение к файлам в коллекции FileList осуществляется также как к элементам обычного массива. При этом каждый элемент в этой коллекции является файлом и представлен в JavaScript через экземпляр класса File .

В этом примере элемент мы записали без атрибута multiple . В этом случае, мы можем выбрать только один файл.
Заключим весь приведённый код в обработчик события change для :
// при изменении document.querySelector('[type="file"]').addEventListener('change', (e) => < // сохраним в переменную files значение свойства files const files = e.target.files; // сохраним количество элементов в files в переменную countFiles const countFiles = files.length; // если количество выбранных файлов больше 0 if (countFiles) < // присваиваем переменной selectedFile ссылку на выбранный файл const selectedFile = files[0]; >>);Теперь наш код будет выполняться всякий раз при изменении значения (в данном случае, когда выбраны файлы).
Чтение файлов с помощью FileReader
После того, как мы получили файл он нам доступен для чтения с помощью FileReader .
Чтобы эго прочитать нам необходимо:
1. Создать новый экземпляр класса FileReader :
const reader = new FileReader();2. Вызвать метод для чтения его содержимого. Это может быть readAsText , readAsDataURL , readAsBinaryString или readAsArrayBuffer . Кстати все эти методы выполняют чтение файла асинхронно.
Например, прочитаем файл посредством метода readAsDataURL :
Этот метод возвращает содержимое файла как Data URL , закодированное в формат base64. Это значит, что мы можем вывести его прямо на страницу. Так как мы будем выбирать изображение, то можем указать эту строку в качестве значения атрибута src элементу
. Но об этом ниже, сейчас же нам необходимо получить содержимое файла как Data URL.
3. Так как чтение файла reader выполняет асинхронно, то нам нужно дождаться окончание этого процесса. То есть мы не можем получить содержимое файла сразу, нам нужно дождаться завершение его чтения. Для этого можно воспользоваться событием load . Оно возникнет на объекте reader сразу как только он прочитает файл. Результат его чтения доступен через e.target.result :
reader.addEventListener('load', (e) => < // e.target.result – содержимое файла >);4. Теперь наконец-то выведем содержимое файла как Data URL в качестве значения атрибута src тега
. Но будем это делать только для изображений. Если пользователь выбрал что-то другое, то будем сообщать ему об этом. В результате у нас получился следующий код:
Для обработки ошибок подпишемся на событие error . Например, выведем с помощью alert предупреждение пользователю, если такое произойдет:
reader.addEventListener('error', () => < console.error(`Произошла ошибка при чтении файла: $`); >);Ну и последнее что сделаем – это выведем для выбранной картинки, её имя и размер. А также немного изменим код, чтобы это осуществлялось в контейнер .selected-file :
Имя файла: -
Размер: -

После выбора файла и его чтения с помощью FileReader:

Чтение файлов полученных посредством Drag’n’Drop
В HTML мы можем получить файлы ещё посредством их перетаскивания, используя HTML5 Drag and Drop API . Для получения файлов мы разместим на странице, например, следующий контейнер:
После этого добавим следующие стили для его оформления:

Для отслеживания процесса перетаскивания существуют различные события. Нас в данном случае будут интересовать только 4 из них:
// получаем элемент .drop-area const dropArea = document.querySelector('.drop-area'); // возникает при входе перетаскиваемого файла в область элемента dropArea dropArea.addEventListener('dragenter', (e) => < e.preventDefault(); // . >); // возникает при выходе перетаскиваемого файла из области элемента dropArea dropArea.addEventListener('dragleave', (e) => < e.preventDefault(); // . >); // возникает, когда перетаскиваемый файл находится в области элемента dropArea dropArea.addEventListener('dragover', (e) => < e.preventDefault(); >); // возникает при отпускании перетаскиваемого файла в dropArea dropArea.addEventListener('drop', (e) => < e.preventDefault(); // . >);Для dragenter , dragleave , dragover и drop мы отменим стандартное поведение браузера при их возникновении на dropArea .
С помощью dragenter и dragleave мы будем просто переключать класс drop-area-over HTML-элемента .drop-area и тем самым выделять область .drop-area , когда перетаскиваемый файл будет находиться над ним.
dropArea.addEventListener('dragenter', (e) => < e.preventDefault(); dropArea.classList.add('drop-area-over'); >); dropArea.addEventListener('dragleave', (e) => < e.preventDefault(); dropArea.classList.remove('drop-area-over'); >);Самое интересное из этих событий – это же конечно drop . Оно возникнет когда пользователь отпустит файл в данном случае над элементом .drop-area .
В обработчике этого события мы будем делать следующее:
dropArea.addEventListener('drop', (e) => < e.preventDefault(); dropArea.classList.remove('drop-area-over'); const transferredFiles = e.dataTransfer.files; [. transferredFiles].forEach(transferredFile => < if (!/^image/.test(transferredFile.type)) < console.log('Выбранный файл не является изображением!'); return; >const reader = new FileReader(); reader.readAsDataURL(transferredFile); reader.addEventListener('error', () => < console.error(`Произошла ошибка при чтении файла: $`); return; >); reader.addEventListener('load', (e) => < dropArea.insertAdjacentHTML('beforeend', ` $`); >); >); >);
$`); >); >); >);- удалять класс drop-area-over и тем самым убирать цветовое выделение границ элемента;
- получать перетаскиваемые файлы с помощью объекта DataTransfer , который нам доступен через e.dataTransfer ;
- перебирать полученные файлы transferredFiles с помощью метода forEach ;
- в forEach выполнять чтение файлов, которые являются изображениями, с помощью FileReader , а затем выводить их с помощью метода insertAdjacentHTML на страницу.
Добавим в код ещё некоторые улучшения. В результате:
body < font-family: consolas; line-height: 1.5; >.drop-area < display: flex; min-height: 100px; max-width: 240px; margin: 100px auto; padding: 2rem 1.5rem 1.5rem; border-radius: 0.25rem; border: 2px dashed #ccc; justify-content: center; flex-wrap: wrap; gap: 2rem; background-image: url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' width='16' height='16' fill='%23e0e0e0' viewBox='0 0 16 16'%3E%3Cpath d='M6.002 5.5a1.5 1.5 0 1 1-3 0 1.5 1.5 0 0 1 3 0z'/%3E%3Cpath d='M1.5 2A1.5 1.5 0 0 0 0 3.5v9A1.5 1.5 0 0 0 1.5 14h13a1.5 1.5 0 0 0 1.5-1.5v-9A1.5 1.5 0 0 0 14.5 2h-13zm13 1a.5.5 0 0 1 .5.5v6l-3.775-1.947a.5.5 0 0 0-.577.093l-3.71 3.71-2.66-1.772a.5.5 0 0 0-.63.062L1.002 12v.54A.505.505 0 0 1 1 12.5v-9a.5.5 0 0 1 .5-.5h13z'/%3E%3C/svg%3E"); background-position: center center; background-repeat: no-repeat; background-size: 50% 50%; >.drop-area-over < border: 2px dashed #2196f3; >.drop-area-preview < flex: 0 0 45%; position: relative; >img < display: block; max-width: 100%; height: auto; border-radius: 0.25rem; margin-bottom: 0.5rem; >.drop-area-name < text-align: center; >.drop-area-remove < position: absolute; top: 0; right: 0; transform: translate(50%, -50%); display: flex; background-color: #424242; border-radius: 0.25rem; cursor: pointer; >.drop-area-remove:hover