- Пакетная обработка в JDBC и HIBERNATE
- Преимущества
- Таблица БД
- 1. JDBC — пакетная обработка
- 1.1. Интерфейс Statement
- 1.2. Интерфейс PreparedStatement
- 1.3. Интерфейс CallableStatement
- 1.4. Класс BatchUpdateException
- 2. Hibernate — пакетная обработка
- 2.1. Изменения в конфигурационном файле
- 2.2. Примеры реализации пакетной обработки
- 2.3. Сбор статистики
- Вывод
Пакетная обработка в JDBC и HIBERNATE
В этой статье, я кратко расскажу о пакетной обработке SQL (DML) операторов: INSERT, UPDATE, DELETE, как одной из возможностей достижения увеличения производительности.
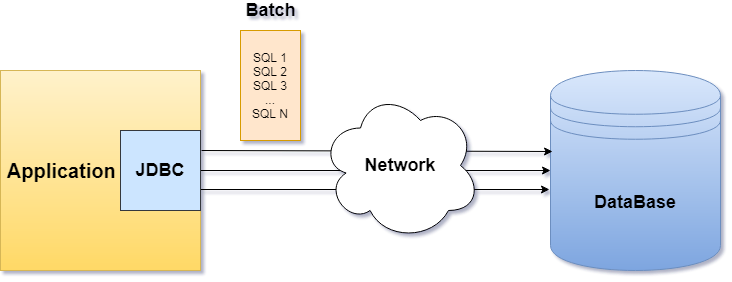
Преимущества
В отличие от последовательного выполнения каждого SQL запроса, пакетная обработка даёт возможность отправить целый набор запросов (пакет) за один вызов, тем самым уменьшая количество требуемых сетевых подключений и позволяя БД выполнять какое-то количество запросов параллельно, что может значительно увеличить скорость выполнения. Сразу оговорюсь, что заметный эффект можно увидеть при вставке, обновлении или удалении больших объёмов данных в таблицу БД.
Таблица БД
В качестве примера будет использована таблица book c полями id и title.
| id | title |
|---|---|
| 10001 | Java Persistence API и Hibernate |
| 10002 | Новая большая книга CSS |
| 10003 | Spring 5 для профессионалов |
| 10004 | Java ЭФФЕКТИВНОЕ ПРОГРАММИРОВАНИЕ |
1. JDBC — пакетная обработка
Прежде чем перейти к примерам реализации, необходимо осветить несколько важных моментов:
- Драйверы JDBC не обязаны поддерживать функцию пакетной обработки, поэтому необходимо вызвать логический метод supportsBatchUpdates() интерфейса DatabaseMetaData , чтобы определить, поддерживается ли эта функция вообще или нет. В большинстве случаев метод вернёт true, так как зачастую современные драйверы поддерживают пакетную обработку.
- Перед созданием пакета, следует отключить автоматическое завершение транзакции после выполнения каждого запроса setAutoCommit(false) . Это приведёт к тому, что завершение или откат транзакции придётся выполнять явно вызывая методы commit() или rollback() . Вызов rollback() будет приводить к откату всего пакета SQL операторов.
- Ну и последнее — это выбор интерфейса, JDBC предоставляет три интерфейса Statement, PreparedStatement и CallableStatement , которые необходимы для выполнения запросов и вызова хранимых процедур в базе данных.
Далее, я приведу небольшие примеры использования интерфейсов Statement, PreparedStatement и CallableStatement в пакетной обработке. В примерах размер пакета указывается, как BATCH_SIZE. Значение размера пакета должно быть оптимальное, то есть не слишком большое, но и не слишком маленькое (например, 10-50).
В примерах, я ограничусь и буду использовать SQL оператор INSERT. Для UPDATE, DELETE всё аналогично.
1.1. Интерфейс Statement
Пример использования Statement для добавления данных пакетами в таблицу book.
connection.setAutoCommit(false); try (Statement stmt = connection.createStatement()) < //(1) for (int i = 1; i catch (BatchUpdateException ex) < Log(ex); connection.rollback(); >> > > - Cоздаём объект Statement ;
- Cобираем пакет запросов с помощью метода void addBatch(String SQL) ;
- Посылаем пакет серверу БД вызвав метод executeBatch() . Метод executeBatch() возвращает массив обработанных строк.
Использование объекта Statement даёт возможность собирать в один пакет разные SQL операторы INSERT, UPDATE, DELETE.
Каждый SQL запрос проверяется и компилируется БД, что приводит к увеличению времени выполнения.
1.2. Интерфейс PreparedStatement
Пример использования PreparedStatement для добавления данных пакетами в таблицу book.
connection.setAutoCommit(false); try (PreparedStatement pstmt = connection.prepareStatement("INSERT INTO book (title) VALUES (?)")) < //(1) for (int i = 1; i catch (BatchUpdateException ex) < Log(ex); connection.rollback(); >> > > - Cоздаём объект PreparedStatement передав в качестве параметра SQL запрос;
- Устанавливаем все параметры, указанные в запросе;
- Собираем пакет запросов с помощью метода void addBatch() ;
- Посылаем пакет серверу БД вызвав метод executeBatch() .
Шаги 3) и 4) такие же, как и для Statement, единственное отличие — это addBatch() без параметров.
SQL запрос компилируется и оптимизируется базой данных один раз, после чего его можно использовать многократно, задавая различные значения параметров. И это серьёзное преимущество, так как не затрачивается время на компиляцию каждого последующего запроса.
Использование интерфейса PreparedStatement не предусматривает возможности собирать в один пакет разные SQL операторы (INSERT, UPDATE, DELETE) подобно как для Statement , а только какой-то один.
1.3. Интерфейс CallableStatement
Интерфейс CallableStatement используется для выполнения хранимых на сервере БД процедур.
Пакетная обработка предусматривает исполнение хранимых процедур при условии, что процедуры не содержат параметров OUT или INOUT.
Пример использования CallableStatement для добавления данных пакетами в таблицу book.
connection.setAutoCommit(false); try (CallableStatement cstmt = connection.prepareCall("call insert_book(?)")) < //(1) for (int i = 1; i catch (BatchUpdateException ex) < Log(ex); connection.rollback(); >> > > - Cоздаём объект CallableStatement передав в качестве параметра вызов хранимой процедуры;
- Устанавливаем все параметры указанные в хранимой процедуре, если таковые есть;
- Собираем пакет запросов с помощью метода void addBatch() ;
- Посылаем пакет серверу БД вызвав метод executeBatch() .
По сути шаги аналогичны, как и для PreparedStatement .
Не затрачивается время на компиляцию, так как хранимая процедура компилируется один раз при первом ее запуске, а затем сохраняется в скомпилированной форме на сервере БД.
Хранимые процедуры предоставляют возможность производить какие-либо вычисления перед тем как совершить манипуляцию с данными, выполнять сложную транзакционную логику.
Использование интерфейса CallableStatement не предусматривает возможности собирать в один пакет вызовы разных хранимых процедур, а только какой-то одной.
1.4. Класс BatchUpdateException
Осветим кратко BatchUpdateException , так как данное исключение непосредственно относиться к пакетной обработке. Получить BatchUpdateException можно в случае, если не удалось выполнить пакет SQL операторов, то есть какой-то запрос или набор запросов из пакета приводят к исключениям, либо возвращают выборку типа ResultSet . BatchUpdateException содержит массив счетчиков обновлений (метод получения getUpdateCounts() ), аналогичный массиву, возвращенному методом executeBatch. В обоих случаях счетчики обновлений находятся в том же порядке, что и SQL запросы. По этому целочисленному массиву результатов, можно отфильтровать запросы c не успешным статусом ( Statement.EXECUTE_FAILED ) и реализовать свой обработчик данного исключения.
Небольшой демонстрационный пример:
. > catch (BatchUpdateException ex) < int[] updateCount = ex.getUpdateCounts(); int count = 1; for (int i : updateCount) < if (i == Statement.EXECUTE_FAILED) < System.out.println("Request " + count + ": Execute failed"); >else < System.out.println("Request " + count + ": OK"); >count++; > > . Этот пример показывает лишь суть выше изложенного. В реальной же ситуации необходимо логировать сам запрос, который привёл к ошибке, так как сам по себе индекс малоинформативен, а для этого необходимо предусмотреть в обработчике сохранение пакета запросов перед их выполнением, чтоб в случае получения исключения уже по индексу определить запросы повлёкшие к нему. К сожалению объект BatchUpdateException не содержит методов получения SQL запросов, которые содержались в пакете и привели к исключению. Поэтому полная реализация механизма логирования и обработки ложиться на плечи разработчика.
2. Hibernate — пакетная обработка
Прежде чем включать пакетную обработку и переходить к примерам реализации, следует обратить внимание на идентификатор класса сущности отмеченный аннотацией @Id . Если используется стратегия GenerationType.IDENTITY , то пакетная вставка (INSERT) не сработает, Hibernate попросту отключит её несмотря на все указанные свойства в Hibernate.cfg.xml о которых пойдёт речь далее. Дело в том, что GenerationType.IDENTITY генерирует числовое значение идентификатора только во время выполнения INSERT в базе данных (т.е. не известно заранее), а это препятствует используемой в Hibernate стратегии write-behind. По этой причине Hibernate отключает пакетную поддержку для всех сущностей, использующих генератор IDENTITY. Выходом может служить использование другой стратегии для идентификатора, либо реализация пакетной вставки на уровне JDBC.
2.1. Изменения в конфигурационном файле
Для того чтобы включить пакетную обработку, необходимо добавить свойство hibernate.jdbc.batch_size в конфигурационный файл Hibernate.cfg.xml, и указать размер пакета. Hibernate будет накапливать пакет SQL выражениями INSERT, UPDATE, DELETE на уровне JDBC и отправлять в БД. А так же при выполнении смешанных SQL выражений для более эффективного накопления на уровне JDBC необходимо добавить в конфигурационный файл такие свойства hibernate.order_inserts, hibernate.order_updates и установить их в true, Hibernate отсортирует операции перед созданием пакета SQL выражений. Необходимость сортировки SQL выражений для большей эффективности обусловлена тем, что на уровне JDBC Hibernate использует метод addBatch() интерфейса PreparedStatement , который не предусматривает возможности собирать в один пакет разные SQL операторы.
2.2. Примеры реализации пакетной обработки
Прежде чем перейти к примерам реализации обратим внимание на некоторые аспекты связанные с контекстом хранения. Как известно, контекст хранения служит кэшем хранимых экземпляров. При попытке загрузить тысячи экземпляров сущностей, Hibernate сделает копию каждого экземпляра в кэше контекста хранения, что может привести к исчерпанию памяти OutOfMemoryException. Есть 2 варианта предотвращения полного расходования памяти:
- Периодический вызов методов flush() и clear() для очистки контекста хранения. Пример:
try (Session session = HibernateUtil.getSessionFactory().getCurrentSession()) < Transaction transaction = session.getTransaction(); transaction.begin(); for (int i = 1; i > transaction.commit(); > try (StatelessSession session = HibernateUtil.getSessionFactory().openStatelessSession()) < Transaction transaction = session.getTransaction(); transaction.begin(); for (int i = 1; i transaction.commit(); > 2.3. Сбор статистики
Для того чтобы убедиться, что Hibernate действительно использует пакетную обработку, можно временно включить сбор статистики. Для этого необходимо в конфигурационном файле Hibernate.cfg.xml установить свойство «hibernate.generate_statistics» в true.
При пакетной вставке, удалении, обновлении статистика будет содержать информацию о затраченном времени и количестве выполненных пакетов.
Пример информации из статистики.
. 217323000 nanoseconds spent executing 200 JDBC batches; . Вывод
Пакетное выполнение SQL запросов – это один из известных способов повышения производительности на который стоит обратить внимание. Уменьшение количества сетевых подключений к БД и увеличение скорости выполнения запросов является существенным плюсом в пользу использования пакетной обработки.
Примеры кода можно посмотреть на GitHub.