jsoup: Java HTML Parser
jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of HTML5 DOM methods and CSS selectors.
jsoup implements the WHATWG HTML5 specification, and parses HTML to the same DOM as modern browsers do.
- scrape and parse HTML from a URL, file, or string
- find and extract data, using DOM traversal or CSS selectors
- manipulate the HTML elements, attributes, and text
- clean user-submitted content against a safelist, to prevent XSS attacks
- output tidy HTML
jsoup is designed to deal with all varieties of HTML found in the wild; from pristine and validating, to invalid tag-soup; jsoup will create a sensible parse tree.
Example
Fetch the Wikipedia homepage, parse it to a DOM, and select the headlines from the In the news section into a list of Elements (online sample, full source):
Document doc = Jsoup.connect("https://en.wikipedia.org/").get(); log(doc.title()); Elements newsHeadlines = doc.select("#mp-itn b a"); for (Element headline : newsHeadlines) Open source
jsoup is an open source project distributed under the liberal MIT license. The source code is available at GitHub.
Getting started
Development and support
If you have any questions on how to use jsoup, or have ideas for future development, please get in touch via one of the discussion methods.
If you find any issues, please file a bug after checking for duplicates.
The colophon talks about the history of and tools used to build jsoup.
Development of jsoup happens on GitHub. There you can see the latest changes, and get the source to build an unreleased version.
Status
jsoup is in general release.
Парсинг html библиотекой jsoup


Итак мы хотим получить конкретную информацию с сайта. Пошагово разберем как это сделать. Для начала нам нужно получить объект Document . Это представление нашей html страницы. В Jsoup есть несколько способов превратить сайт в объект Document . Подключиться к серверу
Document document = Jsoup.connect("https://hh.ru/").get(); Jsoup сам подключается к сайту. Данный способ самый простой, но он годится только для тестирования. Есть более удобные и гибкие http клиенты. Также имейте ввиду, каким бы http клиентом вы не пользовались, добавляйте в запрос заголовок User-Agent с значением например Chrome/81.0.4044.138 . По этому заголовку сервер определяет с какого устройстрва вы подключились. Без этого заголовка сервер считает вас ботом и может забанить. Из файла;
File file = new File("hh-test.html"); Document document = Jsoup.parse(file, "UTF-8", "hh.ru"); Это основной способ получения объекта Document . Последний аргумент «hh.ru» — базовый URI. Это нужно для создания абсолютных ссылок из относительных, которые присутствуют на сайте. Из строки
String html = " " + " " + " " + " Работа в Москве, поиск персонала и публикация вакансий - hh.ru " + " " + " " + " " + " " + " Работа найдется для каждого
" + " Поиск вакансий " + " " + " Вакансии дня " + " " + " Работа из дома " + " " + " " + " "; Document document = Jsoup.parse(html, "hh.ru"); Далее я буду демонстрировать библиотеку на этом html, который представляет упрощенный сайт. Получение тега Основная задача при парсинге — получить нужный тег. Делать мы это будем при помощи метода select . Обратите внимание, что он всегда возвращает список тегов. Если теги не найдены, то список будет пустым. В аргумент метода нужно передать css селектор, по которому ищутся теги. На селекторах я остановлюсь подробнее, потому что вся работа сводится к написанию правильного селектора. Обычно нам нужно составить его так, чтобы он возвращал один тег.
Elements h1 = document.select("h1"); System.out.println(h1); Работа найдется для каждого
Elements titleElem = document.select("head > title"); Elements divs = document.select("body > div"); Elements firstDiv = document.select("body > div:nth-child(1)"); Получить первый тег div вложенный в body . Получать тег по порядковому номеру плохой способ, потому что его положение на сайте может поменяться. Лучше определить тег по абсолютным параметрам. Такими параметрами являются атрибуты class и id
Elements contentElem = document.select("body > div.content"); Elements idElem = document.select("#123"); Elements divHeader = document.select("body > div.header.main :not(h1)"); Методы Elements Когда мы получили список Elements можно извлечь данные из него. Напомню, что обычно селектором ищется один тег, т.е. у Elements должен быть размер 1.
строковое представление тега Если вам нужно быстро получить селектор элемента — в браузере откройте панель разработчика (f12), нажмите правой кнопкой на элемент, «просмотреть код», нажмите правой кнопкой на тег, далее «Copy» «Copy selector». Такой селектор будет не оптимальным, но для быстрого результата вполне подходит. 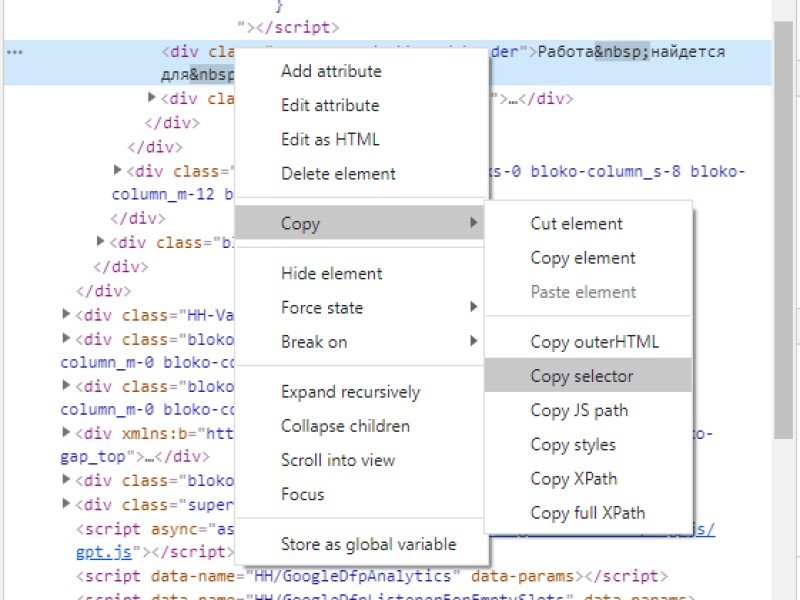
 Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне
Заключение Это основы работы с библиотекой Jsoup. Но этого вполне достаточно, чтобы парсить сайты. Для уверенной работы вам нужна только практика написания селекторов в реальных сайтах. P.s. Данная библиотека используется для решения большой задачи на 38 уровне
Лёгкий парсинг HTML с помощью jsoup

Возможно, когда-нибудь вам будет необходимо получить информацию с какого-либо сайта либо HTML-документа в своем приложении, и я без лишних слов скажу, что использование библиотеки jsoup существенно упростит вашу задачу. Как говорится на wiki, jsoup — это Java-библиотека с открытым исходным кодом, предназначенная для анализа, извлечения и управления данными, хранящимися в документах HTML.
Быстрый старт
Библиотеку можно скачать в виде jar файла и поместить в проект, а также подключить с помощью Maven/Gradle. Ссылку на официальный сайт я оставлю в конце статьи: там вы сможете найти актуальную версию библиотеки. В примере будем использовать подключение через Maven. Добавим зависимость:
Использование
Первым делом вам необходимо получить экземпляр класса Document из org.jsoup.nodes.Document с указанием на источник для разбора. Им может выступать как локальный файл, так и ссылка. Для примера, в данной статье мы будем использовать сайт yandex.ru и попытаемся получить их актуальную новостную ленту:
Document doc = Jsoup.connect("https://yandex.ru/") .userAgent("Chrome/4.0.249.0 Safari/532.5") .referrer("http://www.google.com") .get(); 
User Agent является идентификатором, который сообщается посещаемому сайту. На многих сайтах он является важнейшим критерием для антиспам фильтра. Referrer содержит URL источника запроса. Метод get() вызывает обрабатываемое исключение IOException, так что мы можем обернуть все в try/catch блок, либо просто перебросить его дальше с помощью throws . На данный момент мы получили исходный код данной страницы. При необходимости библиотека jsoup сама может восстановить поврежденные элементы. Теперь нам остается лишь сузить поиск до отдельного блока. Метод select() имеет большую выборку в использовании: он позволяет искать элементы по тегу, атрибутам, классу и другим параметрам. Почти все современные браузеры поддерживают возможность быстрого поиска исходного кода выбранного элемента. Нехитрыми манипуляциями, мы находим исходный код нужного нам элемента и получаем div блок с указанным классом, его мы и будем использовать для выборки. Воспользуемся классом Elements из org.jsoup.select.Elements, для выборки всех элементов из нашего выбранного блока.
Elements listNews = doc.select("div#tabnews_newsc.content-tabs__items.content-tabs__items_active_true"); 
Сейчас мы имеем что то вроде этого: Теперь нам остается лишь использовать небольшой цикл для пробора всех элементов:
for (Element element : listNews.select("a")) System.out.println(element.text()); 
Метод text() позволяет отбросить код разметки и оставляет лишь сочетание текста для всех входящих элементов. Результат выполнения будет таков: Нетрудно заметить, что реальное количество полученных строк не соответствует фактическому отображению на странице. В этом и заключаются подводные камни. Если посмотреть исходный код разметки, можно заметить, что последняя новость анимационно меняется с определенным интервалом времени. Часть таких «камней» решается дополнительной выборкой, ну и конечно тестами. Может оказаться так, что первые пять элементов будут содержать нужную нам информацию, а на шестом элементе будет лишь заскриптованная пустая строка. Бывает и такое, что блоки не будут обладать какими-либо идентификаторами, тогда есть возможностью прямо указать с помощью метода get(int index) на номер позиции рассматриваемого элемента.
System.out.println(listNews.select("a").get(2).text()); Заключение
В данном примере показана лишь малая часть того, на что способен jsoup. Не стоит отменять и тот факт, что сайты нередко обновляются, изменяя структуру кода разметки, так что при работе с парсингом нужно быть готовым адаптироваться к изменениям. Больше информации и актуальную версию вы можете получить на официальном сайте jsoup.org, более подробно почитать про классы и методы можно по ссылке o7planning.org. Оставлю ссылку на мой github, на момент написания статьи там находится несколько Telegram-ботов, которые используют Jsoup для получения и выдачи информации.