- Основные принципы настройки Garbage Collection с нуля
- Количественные характеристики оценки эффективности GC
- Основные принципы настройки GC
- Определение размера необходимой памяти
- Настройка допустимого времени отклика
- Итог
- GC easy – Universal Java GC Log Analyser
- WHAT IS GARBAGE COLLECTION LOG? HOW TO ENABLE & ANALYZE?
- Enabling GC logs
- How to analyze GC logs?
Основные принципы настройки Garbage Collection с нуля
В данной статье я бы не хотел заострять внимание на принципе работы сборщика мусора — об этом прекрасно и наглядно описано здесь: habrahabr.ru/post/112676. Хочется больше перейти к практическим основам и количественным характеристикам по настройке Garbage Collection в JVM — и попытаться понять насколько это может быть эффективным.
Количественные характеристики оценки эффективности GC
Рассмотрим следующие показатели:
- Пропускная способность Мера, определяющая способность приложения работать в пиковой нагрузке не зависимо от пауз во время сборки и размера необходимой памяти
- Время отклика Мера GC, определяющая способность приложения справляться с числом остановок и флуктуаций работы GC
- Размер используемой памяти Размер памяти, который необходим для эффективной работы GC
Как правило, перечисленные характеристики являются компромиссными и улучшение одной из них ведёт к затратам по остальным. Для большинства приложений важны все три характеристики, но зачастую одна или две имеют большее значение для приложения — это и будет отправной точкой в настройке.
Основные принципы настройки GC
- Необходимо стремиться к тому, чтобы максимальное количество объектов очищалось при работе малого GC(minor grabage collection). Этот принцип позволяет уменьшить число и частоту работы полного сборщика мусора(full garbage collection) — чья работа является основной причиной больших задержек в приложении
- Чем больше памяти выделено приложению, тем лучше работает сборка мусора и тем лучше достигаются количественные характеристики по пропускной способности и времени отклика
- Эффективно настроить можно только 2 из 3 количественных характеристик — пропускная способность, время отклика, размер выделенной памяти — под эффективным значением размера необходимой памяти понимается её минимизация
Рассмотрим пример простого приложения(которое, к примеру, может эмулировать работу вэб-приложения, в ходе которого идёт обращение к БД и накопление возвращаемого результат), в котором в несколько потоков идёт обращение к методу makeObjects(), в ходе которого в цикле непрерывно формируется объект, занимающий определённый объём в куче, затем с ним происходят какие-либо вычисления — делается задержка, ссылка на объект при этом не утекает из метода и по его завершению GC может понять, что данный объект подлежит очистке.
package ru.skuptsov; import java.util.ArrayList; import java.util.List; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class MemoryConsumer implements Runnable < private static final int OBJECT_SIZE = 1024 * 1024; private static final int OBJECTS_NUMBER = 8; private static final int ADD_PROCESS_TIME = 1000; private static final int NUMBER_OF_REQUEST_THREADS = 50; private static final long EXPERIMENT_TIME = 30000; private static volatile boolean stop = false; public static void main(String[] args) throws InterruptedException < start(); Thread.sleep(EXPERIMENT_TIME); stop(); >private static void start() < ExecutorService execService = Executors.newCachedThreadPool(); for (int i = 0; i < NUMBER_OF_REQUEST_THREADS; i++) execService.execute(new MemoryConsumer()); >private static void stop() < stop = true; >@Override public void run() < while (true && !stop) < makeObjects(); >> private void makeObjects() < ListobjectList = new ArrayList(); for (int i = 0; i < OBJECTS_NUMBER; i++) < objectList.add(new byte[OBJECT_SIZE]); >try < Thread.sleep(ADD_PROCESS_TIME); >catch (InterruptedException e) < e.printStackTrace(); >> > Эксперимент длится некоторое время, далее для оценки эффективности будем использовать общее время задержки, вызванное сборщиком мусора. Задержка необходима для того, чтобы после финальной маркировки объектов на удаление не появилась ссылка на очищаемый объект. О том, что существует jvm, которая может помечать и очищать объекты не вызывая «stop-the-world» паузу и как функционируют различные типы GC — подробно описано здесь habrahabr.ru/post/148322 — мы не рассматриваем такой вариант.
Запускать эксперимент мы будем на:
C:\>java -XX:+PrintCommandLineFlags -version -XX:MaxHeapSize=4290607104 -XX:ParallelGCThreads=8 -XX:+PrintCommandLineFlags -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC java version "1.6.0_16" Java(TM) SE Runtime Environment (build 1.6.0_16-b01) Java HotSpot(TM) 64-Bit Server VM (build 14.2-b01, mixed mode) Для которого по умолчанию включен режим — server и UseParallelGC(многопоточная работа фазы малой сборки мусора)
Для оценки общей величины паузы сборщика мусора можно запускать в режиме:
java -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -verbose:gc -Xloggc:gc.log ru.skuptsov.MemoryConsumer 0.167: [Full GC [PSYoungGen: 21792K->13324K(152896K)] [PSOldGen: 341095K->349363K(349568K)] 362888K->362687K(502464K) [PSPermGen: 2581K->2581K(21248K)], 0.0079385 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] Где real=0.01 secs — реальное время, затраченное на сборку.
А можно воспользоваться утилитой VisualVm, с установленным плагином VisualGC, в котором наглядно можно наблюдать распределение памяти по различным областям GC(Eden, Survivor1, Survivor2, Old) и видеть статистику по запуску и длительности сборки мусора.
Определение размера необходимой памяти
Для начала мы должны запустить приложение с возможно большим размером памяти, чем это это реально необходимо приложению. Если мы не знаем изначально, сколько будет занимать наше приложение в памяти — можно запустить приложение без указания -Xmx и -Xms и HotSpot VM сама выберет размер памяти. Если при старте приложения мы получим OutOfMemory(Java heap space или PermGen space), то мы можем итеративно увеличивать размер доступной памяти(-Xmx или -XX:PermSize) до тех пор пока ошибки не уйдут.
Следующим шагом будет вычисление размера долго-живущих живых данных — это размер old и permanent областей кучи после фазы полной сборки мусора. Этот размер — примерный объём памяти, необходимый для функционирования приложения, для его получения можно посмотреть на размер областей после серии полной сборки. Как правило размер необходимой памяти для приложения -Xms и -Xmx в 3-4 раза больше, чем объём живых данных. Так, для лога, указанного выше — величина old области после фазы полной сборки мусора — 349363K. Тогда предлагаемое значение -Xmx и -Xms ~ 1400 Мб. -XX:PermSize and -XX:MaxPermSize — в 1.5 раз больше, чем PermGenSize после фазы полной сборки мусора — 13324K ~ 20 Мб. Размер young generation принимаю равным 1-1.5 размера объёма живых данных ~ 525 Мб. Тогда получаем строку запуска jvm с такими параметрами:
java -Xms1400m -Xmx1400m -Xmn525m -XX:PermSize=20m ru.skuptsov.MemoryConsumer В VisualVm получаем такую картину:
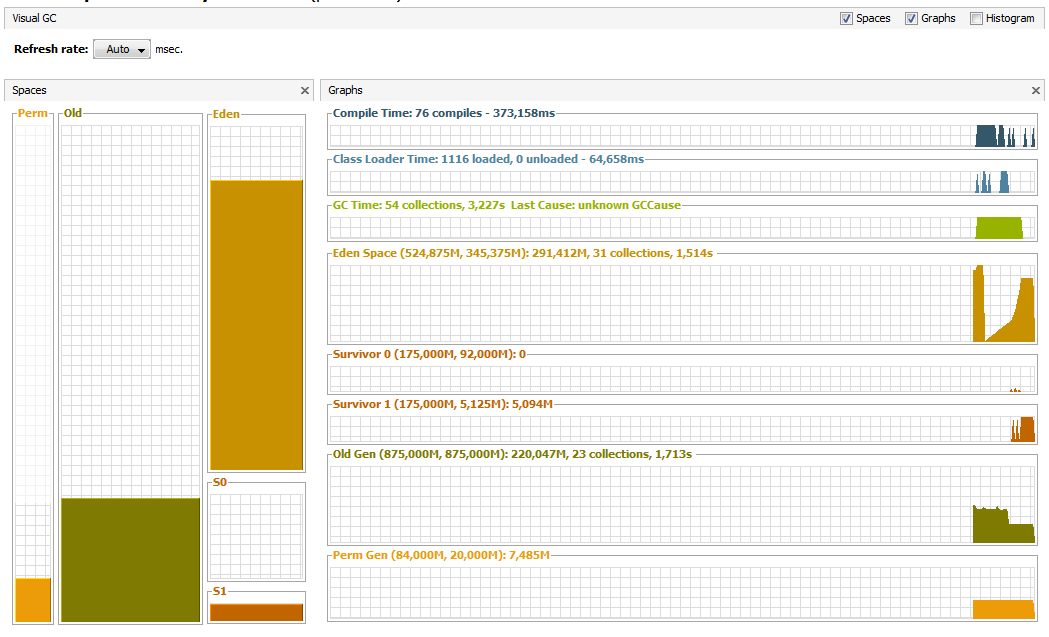
Всего за 30 сек эксперимента было произведено 54 сборки — 31 малых и 23 полных — с общим временем остановки 3,227c. Данная величина задержки может не удовлетворять необходимым требованиям — посмотрим, сможем ли мы улучшить ситуацию без изменения кода приложения.
Настройка допустимого времени отклика
- Измерение длительности малой сборки мусора
- Измерение частоты малой сборки мусора
- Измерение длительности худшего случая полной сборки мусора
- Измерение частоты худшего случая полной сборки мусора
Корректировка размера young и old generation
Время, необходимое для осуществления фазы малой сборки мусора, напрямую зависит от числа объектов в young generation, чем меньше его размер — тем меньше длительность, но при этом возрастает частота, т.к. область начинает чаще заполняться. Попробуем уменьшить время каждой малой сборки, уменьшив размер young generation, сохранив при этом размер old generation. Примерно можно оценить, что каждую секунду мы должны очищать в young generation 50потоков*8объектов*1Мб~ 400Мб. Запустим с параметрами:
java -Xms1275m -Xmx1275m -Xmn400m -XX:PermSize=20m ru.skuptsov.MemoryConsumer В VisualVm получаем такую картину:

На общее время работы малой сборки мусора мы повлиять не смогли — 1,533с — увеличилась частота малых сборок, но общее время ухудшилось — 3,661 из-за того, что увеличилась скорость заполнения old generation и увеличилась частота вызова полной сборки мусора. Чтобы побороть это — попробуем увеличить размер old generation — запустим jvm с параметрами:
java -Xms1400m -Xmx1400m -Xmn400m -XX:PermSize=20m ru.skuptsov.MemoryConsumer 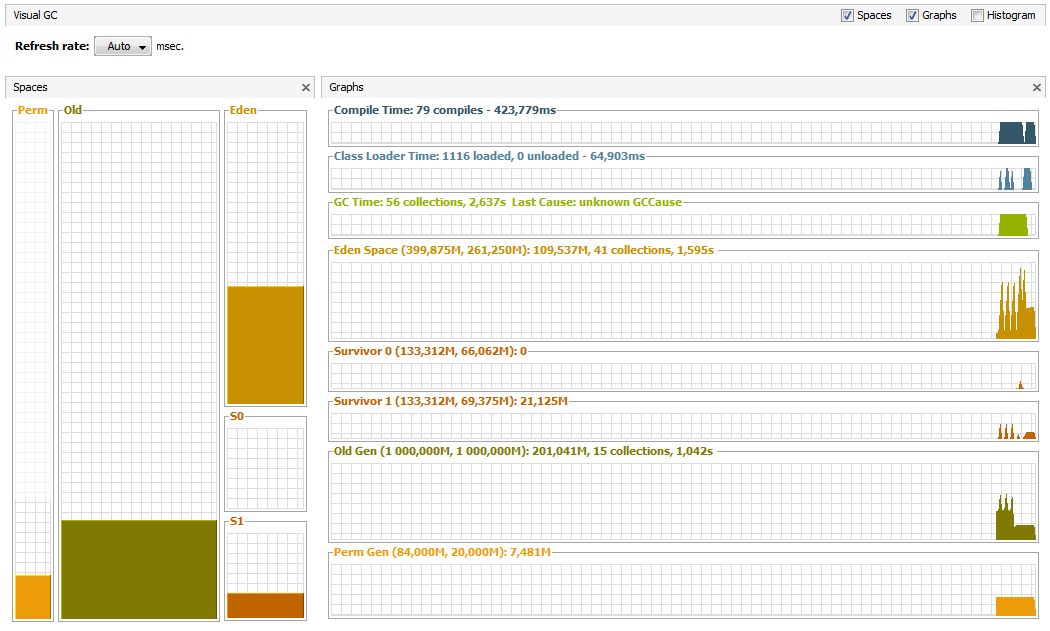
Общая пауза теперь улучшилась и составляет 2,637 с а общее значение необходимой для приложения памяти при этом уменьшилось — таким образом итеративно можно найти правильный баланс между old и young generation для распределения времени жизни объектов в конкретном приложении.
Если время задержки по-прежнему нас не устраивает — можно перейти к concurrent garbage collector, включив опцию -XX:+UseConcMarkSweepGC — алгоритм, который будет пытаться выполнять основную работу по маркировке объектов на удаление в отдельном потоке параллельно потокам приложения.
Настройка Concurrent garbage collector
ConcMarkSweep GC требует более внимательной настройки, — одной из основных целей является уменьшение количества stop-the-world пауз при отсутствии достаточного места в old generation для расположения объектов — т.к. эта фаза занимает в среднем больше времени, чем фаза полной сборки мусора при throughput GC. Как результат — может увеличиться длительность худшего случая сборки мусора, необходимо избегать частых переполнений old generation. Как правило, — при переходе на ConcMarkSweep GC рекомендуют увеличить размер old generation на 20-30% — запустим jvm с параметрами:
java -Xms1680m -Xmx1680m -Xmn400m -XX:+UseConcMarkSweepGC -XX:PermSize=20m ru.skuptsov.MemoryConsumer 
Общая пауза сократилась до 1,923 с.
Корректировка размера survivor
Снизу под графиком вы видите распределение объёма памяти приложения по числу переходов между стадиями Eden, Survivor1 и Survivor2 перед тем как они попадут в Old Generation. Дело в том, что один из способов уменьшения числа переполнений old generation в ConcMarkSweep GC — предотвратить прямое перетекание объектов из young generation напрямую в old — минуя survivor области.
Для слежения за распределением объектов по этапам можно запустить jvm с параметром -XX:+PrintTenuringDistribution.
В gc.log можем наблюдать:
Desired survivor size 20971520 bytes, new threshold 1 (max 4) - age 1: 40900584 bytes, 40900584 total Общее размер survivor объектов — 40900584, CMS по умолчанию использует 50% барьер заполненности области survivor. Таким образом получаем размер области ~ 80 Мб. При запуске jvm он задаётся параметром -XX:SurvivorRatio, который определяется из формулы:
survivor space size = -Xmn/(-XX:SurvivorRatio= + 2) java -Xms1680m -Xmx1680m -Xmn400m -XX:SurvivorRatio=3 -XX:+UseConcMarkSweepGC -XX:PermSize=20m ru.skuptsov.MemoryConsumer java -Xms1760m -Xmx1760m -Xmn480m -XX:SurvivorRatio=5 -XX:+UseConcMarkSweepGC -XX:PermSize=20m ru.skuptsov.MemoryConsumer 
Распределение стало лучше, но общее время сильно не изменилось в силу специфики приложения, дело в том, что после частых малых сборок мусора размер выживших объектов всегда больше, чем доступный размер областей survivor, поэтому в нашем случае мы можем пожертвовать правильным распределением в угоду размера eden space:
java -Xms1760m -Xmx1760m -Xmn480m -XX:SurvivorRatio=100 -XX:+UseConcMarkSweepGC -XX:PermSize=20m ru.skuptsov.MemoryConsumer 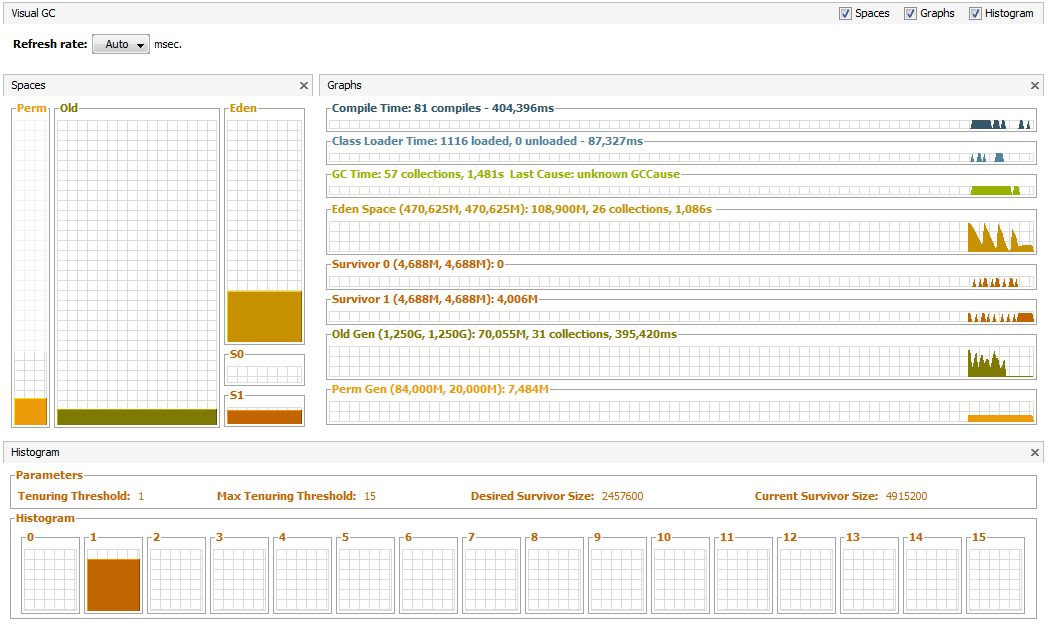
Итог
В результате мы сумели сократить размер общей паузы с 3,227 с до 1,481 с на 30 с эксперимента, немного увеличив при этом общее потребление памяти. Много это или мало — зависит от конкретной специфики, в частности, учитывая тенденцию к уменьшению стоимости физической памяти и принцип максимизации используемой памяти — всё равно важно найти баланс между различными областями GC и процесс этот, скорее, творческий, чем научный.
GC easy – Universal Java GC Log Analyser

WHAT IS GARBAGE COLLECTION LOG? HOW TO ENABLE & ANALYZE?

Enabling GC logging provides great benefits such as: reducing overall application response time, troubleshooting memory problems, forecast outages, and doing effective capacity planning… Contrary to common thinking, enabling GC logging doesn’t add any noticeable overhead to your application. Thus, we strongly recommend you enable GC logging on all your production servers.
Enabling GC logs
GC Logging can be enabled by passing below-mentioned JVM arguments during application startup
Until Java 8:
If your application is running on Java 8 or below version, pass below JVM arguments:
-XX:+PrintGCDetails -Xloggc: Example: -XX:+PrintGCDetails -Xloggc:/opt/tmp/myapp-gc.log
From Java 9:
If your application is running on Java 9 or above version, pass below JVM arguments:
-Xlog:gc*:file= Example: -Xlog:gc*:file=/opt/tmp/myapp-gc.log
How to analyze GC logs?
Here is a sample GC log generated when above system properties were passed:
GC log has rich information, however, understanding GC log is not easy. There isn’t sufficient documentation to explain GC log format. On top of it, GC log format is not standardized. It varies by JVM vendor (Oracle, IBM, HP, Azul, …), Java version (1.4, 5, 6, 7, 8, 9), GC algorithm (Serial, Parallel, CMS, G1, Shenandoah), GC system properties that you pass (-XX:+PrintGC, -XX:+PrintGCDetails, -XX:+PrintGCDateStamps, -XX:+PrintHeapAtGC …). Based on this permutation and combination, there are easily 60+ different GC log formats.
Thus, to analyze GC logs, it’s highly recommended to use GC log analysis tools such as GCeasy , HPJmeter . These tools parse GC logs and generate great graphical visualizations of data, reports Key Performance Indicators and several other useful metrics.
Here is a sample GC log analysis report generated by the GCeasy tool.