- Шпаргалка по регулярным выражениям
- Метасимволы
- Квантификаторы
- Символьные классы
- Группы (подмаски)
- Модификаторы (флаги)
- Похожие записи
- Using This RegEx Tool to Match HTML Tags
- What Is the Regular Expression (RegEX)
- What You Can Do with RegEX
- Common RegEx Use Cases
- Free RegEx Tool – Octoparse
- Case 2: Write RegEx to extract specific info (like email, websites, etc)
Шпаргалка по регулярным выражениям
Регулярное выражение представляет собой «строку-шаблон», написанную на формальном языке поиска, по которой производится поиск в целевом строковом представлении (контенте). «Строка-шаблон» состоит из строковых, цифровых и специальных символов, а также заключается между ограничителями шаблона ( /RegExp/ ). В роли ограничителей шаблона нельзя использовать буквы и цифры, чаще всего используются / , # и ~ .
В шпаргалке описываются регулярные выражения, работающие с библиотекой PCRE.
Метасимволы
Зарезервированные специальные символы. Для использования метасимвола, как обычного литерала, необходимо экранировать его, для этого нужно поставить \ непосредственно перед экронируемым метасимволом, например . — это совпадение с любым символом кроме пробельного, а \. — это совпадение только с точкой.
Позиционные:
- ^ — начало строки ( /^RegExp/ ), внутри символьного класса трактуется как литерал или знак отрицания (зависит от расположения в наборе).
- $ — конец строки ( /RegExp$/ ), внутри символьного класса трактуется как литерал.
- \A — начало текста ( /\ARegExp/ ), похож на ^ , но в мультистроковом режиме \A будет всегда обозначать начало всего текста, а ^ — начало каждой строки;
- \z — конец текста ( /RegExp\z/ ), похож на $ , но в мультистроковом режиме \z будет всегда обозначать конец всего текста, а $ — конец каждой строки;
- \Z — похож на \z , но если последним символом текста является перевод строки, то \Z будет занимать позицию, находящуюся перед последним переводом строки, а \z всегда будет на позиции в самом конце текста;
- \b — обозначает границу слова, для обращения к первой букве слова www «W» используется так ( \bw ), а к последней букве так ( w\b );
- \B — обратное от \b , для обращения к средней (второй) букве «w» слова www используется так ( \Bw\B );
- \G — останавливается на позиции окончания повторяющихся подряд символов, например: \Gw остановится на четвертой позиции после www , при поиске в строке www.example.com .
Группирующие:
- ( — открывает вложенное выражение;
- ) — закрывает вложенное выражение;
- | — логическое «или», может использоваться внутри ( (abc|def|ghi) ) и вне ( abc|def|ghi ) группы.
- \f — конец страницы;
- \n — новая строка;
- \r — возврат каретки;
- \t — табуляция;
- \v — вертикальная табуляция.
Квантификаторы (для поиска последовательностей):
- — точное количество вхождений;
- — диапазон вхождений от min до max ;
- ? — ноль или одно вхождение (эквивалентно );
- + — одно или более одно вхождения (эквивалентно );
- * — ноль, одно или более одно вхождения (эквивалентно ).
Объединяющие (для символьных классов):
- [ — открывает символьный класс;
- ] — закрывает символьный класс;
- — — задает диапазон символов в символьном классе ( 9 );
- ^ — если ^ располагается в самом начале, то это означает отрицание всех символов, входящих в состав данного символьного класса ( /[^0-9]/ ), на другой позиции трактуется как литерал;
- \d — целое число ( 1 );
- \D — любой символ кроме целочисленного ( [^0-9] );
- \s — любой пробельный символ ( [\f\n\r\t\v ] );
- \S — любой символ кроме пробельного ( [^\f\n\r\t\v ] );
- \w — целое число, буква и подчеркивание ( [a-zA-Z0-9_] );
- \W — любой символ кроме целого числа, буквы и подчеркивания ( [^a-zA-Z0-9_] ).
Квантификаторы
Располагаются следом за символьным классом, группой или одиночным символом, указывая количество их повторений, например .* обозначает любые символы в любом количестве.
По умолчанию квантификаторы являются «жадными», например если произвести поиск всех тегов в HTML-коде <.*>, то все теги будут трактоваться как один, так как после первого совпадения следующие теги будут соответствовать .* . Для решения задачи нужно или уточнить искомый результат <[^>]*> , или сделать квантификатор «ленивым», поставив ? после квантификатора <.*?>.
Существует еще один «сверхжадный» режим, его еще называют «ревнивым», он является самым быстродейственным и служит для поиска самого длинного варианта. Данный режим полезен для проверки существования подстроки в строке, а также для исключения из результатов поиска нежелаемых совпадений. Для включения «ревнивого» режима нужно поставить + после квантификатора.
Символьные классы
Наборы различных символов, помещенные в квадратные скобки. В некоторых случаях поведение метасимволов в символьных классах может изменяться по сравнению с их аналогами, находящимися на других позициях «строки-шаблона», например . внутри набора трактуется как литерал.
- [abc] — любой один символ из трех указанных: «a» или «b» или «c».
- [^abc] — любые символы кроме трех указанных: «a» или «b» или «c».
- [a-d] — символы в диапазоне от «a» до «d» (a, b, c, d).
- [^a-d] — любые символ кроме диапазона от «a» до «d» (a, b, c, d).
- 5 — целые числа от «0» до «9» (0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
- [^a-d1-4] — любые символы кроме диапазона букв от «a» до «d» (a, b, c, d) и цифр от «1» до «4» (1, 2, 3, 4).
Группы (подмаски)
Группировка добавляет функционал «обратных ссылок», которые дают возможность запоминать найденные группы символов под порядковыми номерами и обращаться к ним по этим номерам как по ссылкам. Для обращения к обратным ссылкам в «строке-шаблоне» используется обратный слэш и присвоенный номер группе ( \1 ), а для обращения в «строке-замене» — знак доллара ( $1 ). Для примера подставим закрывающий HTML-тег заголовка:
В некоторых случаях дополнительно к цифровым удобно использовать именованные группы ( (?P. ) или ( (?. ) ), например для обработки динамических HTTP-роутов:
Встречаются ситуации, когда необходимо сгруппировать символы, но саму группу не запоминать. Для этого нужно после открывающейся скобки поставить знак вопроса и двоеточие ( (. ) ).
Существует еще «атомарная группировка« ( (?>. ) ). Она похожа на «ревнивую« квантификацию, точно также при первом найденном совпадении останавливает поиск в группе и является самой быстрой из группировок.
Подмаска дает возможность применять условия типа if и if-else :
Также подмаску можно использовать для поиска конкретного фрагмента в целевой строке, по указанной подмаске будет производиться поиск, но при этом сама подмаска не будет включена в результат поиска.
| Формат | Название | Пример | Результат |
|---|---|---|---|
| (?=. ) | Позитивный просмотр вперёд | .*(?=\.com) | example .com example.org |
| (. ) | Негативный просмотр вперёд | .*(?!\.com) | example.com example .org |
| (? | Позитивный просмотр назад | (? <=example\.).* | example. com example. org |
| (? | Негативный просмотр назад | (? | example.com example.org |
Модификаторы (флаги)
Модифицируют поведение регулярного выражения, стоящий перед модификатором — инвертирует его поведение (не распространяется на U ). Флаги указываются после «строки-шаблона» в произвольном порядке ( /RegExp/ugi ).
- g — ищет все совпадения со «строкой-шаблоном» (по умолчанию поиск останавливается после первого совпадения).
- i — регистронезависимость («a» и «A» считаются эквивалентными).
- m — мультистроковость (по умолчанию целевая строка, в котором производится поиск, считается одной строкой).
- s — однострочность (контент считается одной строкой в отличие от режима по умолчанию, метасимвол . включает в себя пробельные символы).
- u — поддержка юникода («строка-шаблон» и целевая строка будут обрабатываться в кодировке UTF-8).
- U — инверсия жадности квантификаторов (по умолчанию квантификаторы становятся «ленивыми», вернуть им «жадность» можно, поставив после квантификатора ? ).
- x — все неэкранированные пробельные символы, которые находятся вне символьного класса, будут проигнорированы.
Похожие записи
Using This RegEx Tool to Match HTML Tags
If you’ve dealt with text-based data before, you may be no stranger to how a messy dataset can make your life miserable. The fact that most of the world’s data come in nonstructural form is an ugly truth to be known sooner or later. In this post, we will talk about what RegEx (regular expression) is, what you can do with RegEx, and some specific examples with a free RegEx tool.
What Is the Regular Expression (RegEX)
“A regular expression (sometimes called a rational expression) is a sequence of characters that define a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. “find and replace”-like operations. The concept arose in the 1950s when the American mathematician Stephen Kleene formalized the description of a regular language and came into common use with the Unix text-processing utility ed (a line editor for the Unix operating system), an editor, and grep (a command-line utility for searching plain-text data sets for lines matching a regular expression), a filter (a computer program or subroutine to process a stream, producing another stream).” This is an excerpt from Wikipedia used to define regular expression. As obscure as it sounds, the concept is actually quite easy to understand. Say that you want to find a certain movie on Netflix, you’d probably search with the title of the Movie or even part of the title. Netflix’s search engine would then go on to look for any movie with titles matching what you’ve input into the search box and show you a list of search results that matches your search keywords. Likewise, regular expressions are like the words you’ve used to search for the movie that you want to find. Essentially, regular expressions are text patterns that you can use to match elements or replace elements throughout strings of text. RegEx can be more powerful than you think because of how incredibly flexible it is for cleansing text-based data.
What You Can Do with RegEX
Common RegEx Use Cases
HTML is practically made up of strings, and what makes regular expression so powerful is, that a regular expression can match different strings. Admittedly, using regular expressions for parsing HTML can often lead to mistakes like missing closing tags, mismatching some tags, etc. Programmers are more likely to use other HTML parsers like PHPQuery, BeautifulSoup, html5lib-Python, etc. However, if you want to quickly match HTML tags, you can use this incredibly convenient tool to identify patterns in HTML documents. Every programmer or anyone who wants to extract web data is strongly recommended to learn about regular expressions for how this tool is able to greatly improve work efficiency and productivity.
Let’s look at a few examples of regular expressions to match HTML tags.

- Regular expression to match :
We can match a variety of HTML tags by using such a regular expression and therefore easily extract data in HTML documents.
You can also check this Regular Expressions Cheat Sheet to have a quick reference for RegEx.
Also, here are some popular online RegEx testing and debugging tools to help generate or verify the right expressions:
If you need to scrape and reformat web data at the same time, download Octoparse, it is a Free RegEx tool that’s ready to use. Just open the software and click on the “Tools” icon on the sidebar menu.
Free RegEx Tool – Octoparse
With Octoparse, the best web scraping tool, you can use RegEx to match out/replace characters in a field value to refine the extracted data directly.
Octoparse RegEx tool is a built-in tool that offers a handy way to generate Regular Expressions automatically by setting up various criteria. When knowing little about how to create a regular expression syntax, the RegEx tool would be especially helpful.
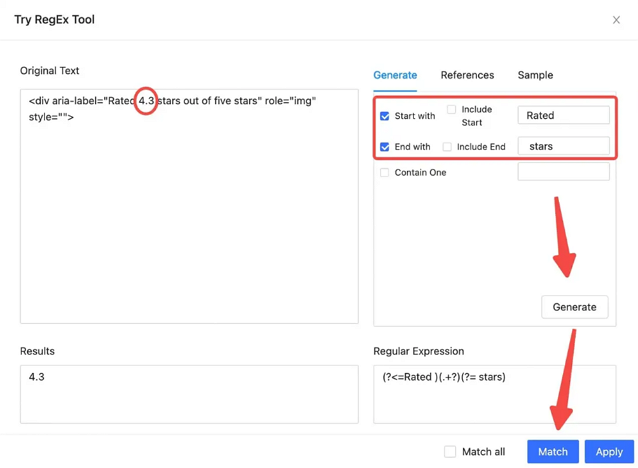
Case 2: Write RegEx to extract specific info (like email, websites, etc)
If you want to extract emails from the source code (especially for some URLs sharing different structures), you can use the RegEx below directly to match the email. You can test and debug your own regular expressions right away with the tool.