- Внутренняя работа HashMap в Java
- Хэширование
- Метод hashCode()
- Метод equals()
- Корзины (Buckets)
- Вычисление индекса в HashMap
- Изменения в Java 8
- Важный момент
- Hashmap java получить элемент
- Nested Class Summary
- Nested classes/interfaces inherited from class java.util.AbstractMap
- Nested classes/interfaces inherited from interface java.util.Map
- Constructor Summary
Внутренняя работа HashMap в Java
[примечание от автора перевода] Перевод был выполнен для собственных нужд, но если кому -то это окажется полезным, значит мир стал хоть немного, но лучше! Оригинальная статья — Internal Working of HashMap in Java
В этой статье мы увидим, как изнутри работают методы get и put в коллекции HashMap. Какие операции выполняются. Как происходит хеширование. Как значение извлекается по ключу. Как хранятся пары ключ-значение.
Как и в предыдущей статье, HashMap содержит массив Node и Node может представлять класс, содержащий следующие объекты:
Теперь мы увидим, как все это работает. Для начала мы рассмотрим процесс хеширования.
Хэширование
Хэширование -это процесс преобразования объекта в целочисленную форму, выполняется с помощью метода hashCode(). Очень важно правильно реализовать метод hashCode() для обеспечения лучшей производительности класса HashMap.
Здесь я использую свой собственный класс Key и таким образом могу переопределить метод hashCode() для демонстрации различных сценариев. Мой класс Key:
// специальный класс Key для переопределени методов hashCode() // и equals() class Key < String key; Key(String key) < this.key = key; >@Override public int hashCode() < return (int)key.charAt(0); >@Override public boolean equals(Object obj) < return key.equals((String)obj); >>Здесь переопределенный метод hashCode() возвращает ASCII код первого символа строки. Таким образом, если первые символы строки одинаковые, то и хэш коды будут одинаковыми. Не стоит использовать подобную логику в своих программах.
Этот код создан исключительно для демонстрации. Поскольку HashCode допускает ключ типа null, хэш код null всегда будет равен 0.
Метод hashCode()
Метод hashCode() используется для получения хэш кода объекта. Метод hashCode() класса Object возвращает ссылку памяти объекта в целочисленной форме (идентификационный хеш (identity hash code)). Сигнатура метода public native hashCode() . Это говорит о том, что метод реализован как нативный, поскольку в java нет какого -то метода позволяющего получить ссылку на объект. Допускается определять собственную реализацию метода hashCode(). В классе HashMap метод hashCode() используется для вычисления корзины (bucket) и следовательно вычисления индекса.
Метод equals()
Метод equals используется для проверки двух объектов на равенство. Метод реализованн в классе Object. Вы можете переопределить его в своем собственном классе. В классе HashMap метод equals() используется для проверки равенства ключей. В случае, если ключи равны, метод equals() возвращает true, иначе false.
Корзины (Buckets)
Bucket -это единственный элемент массива HashMap. Он используется для хранения узлов (Nodes). Два или более узла могут иметь один и тот -же bucket. В этом случае для связи узлов используется структура данных связанный список. Bucket -ы различаются по ёмкости (свойство capacity). Отношение между bucket и capacity выглядит следующим образом:
capacity = number of buckets * load factorОдин bucket может иметь более, чем один узел, это зависит от реализации метода hashCode(). Чем лучше реализованн ваш метод hashCode(), тем лучше будут использоваться ваши bucket -ы.
Вычисление индекса в HashMap
Хэш код ключа может быть достаточно большим для создания массива. Сгенерированный хэш код может быть в диапазоне целочисленного типа и если мы создадим массив такого размера, то легко получим исключение outOfMemoryException. Потому мы генерируем индекс для минимизации размера массива. По сути для вычисления индекса выполняется следующая операция:
где n равна числу bucket или значению длины массива. В нашем примере я рассматриваю n, как значение по умолчанию равное 16.
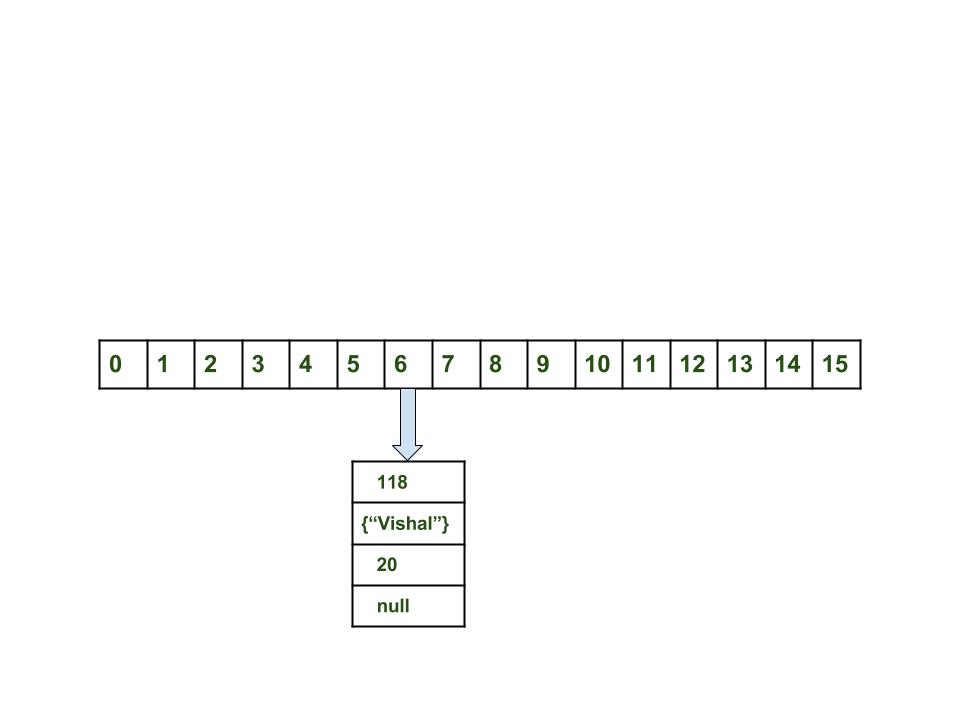
HashMap:
- Вычислить значение ключа . Оно будет сгенерированно, как 118.
- Вычислить индекс с помощью метода index , который будет равен 6.
- Создать объект node.
< int hash = 118 // не строка, а // объект класса Key Key key = Integer value = 20 Node next = null >Теперь HashMap выглядит примерно так:
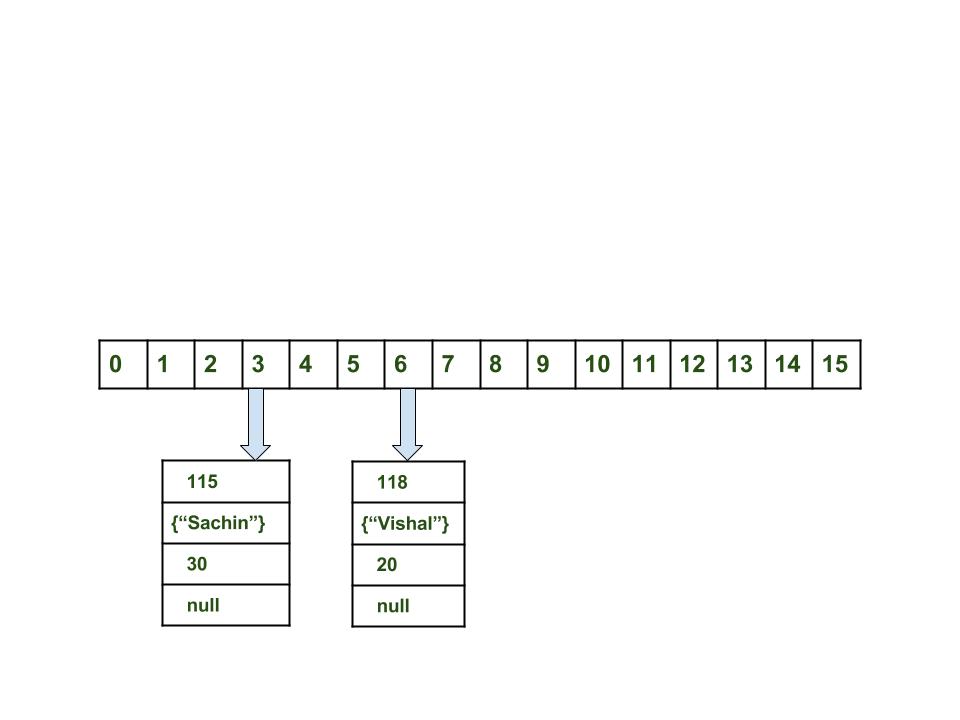
- Вычислить значение ключа . Оно будет сгенерированно, как 115.
- Вычислить индекс с помощью метода index , который будет равен 3.
- Создать объект node.
< int hash = 115 Key key = Integer value = 30 Node next = null >Теперь HashMap выглядит примерно так:
- Вычислить значение ключа . Оно будет сгенерированно, как 118.
- Вычислить индекс с помощью метода index , который будет равен 6.
- Создать объект node.
< int hash = 118 Key key = Integer value = 20 Node next = null >Теперь HashMap выглядит примерно так:
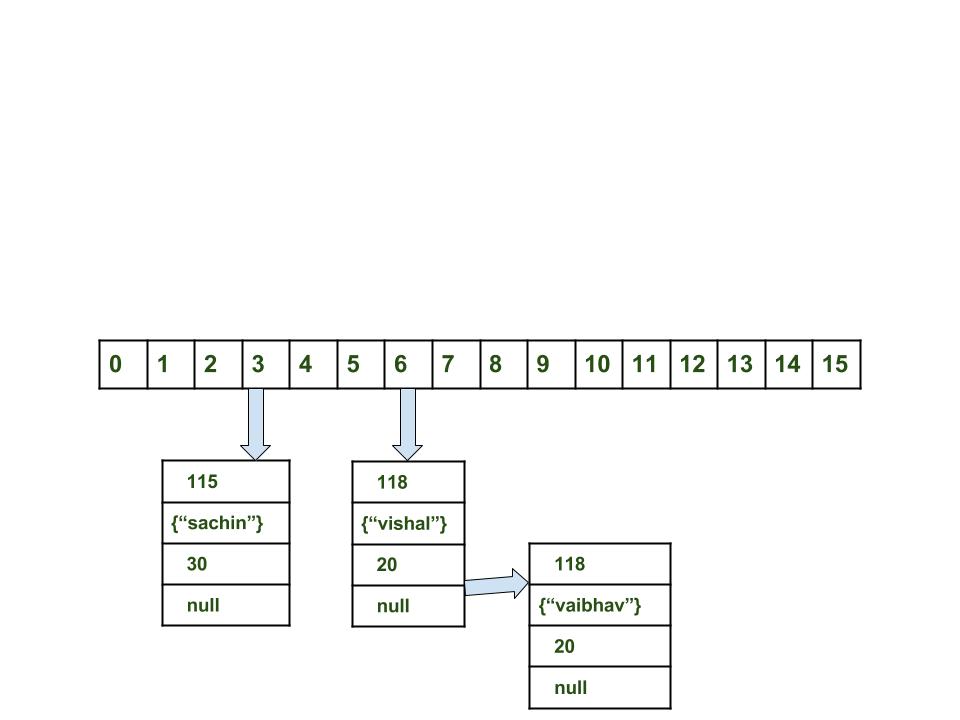
[примечание от автора перевода] Изображение взято из оригинальной статьи и изначально содержит ошибку. Ссылка на следующий объект в объекте vishal с индексом 6 не равна null, в ней содержится указатель на объект vaibhav.
- Вычислить хэш код объекта . Он был сгенерирован, как 115.
- Вычислить индекс с помощью метода index , который будет равен 3.
- Перейти по индексу 3 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
- В нашем случае элемент найден и возвращаемое значение равно 30.
- получаем значение по ключу vaibahv:
- Вычислить хэш код объекта . Он был сгенерирован, как 118.
- Вычислить индекс с помощью метода index , который будет равен 6.
- Перейти по индексу 6 и сравнить ключ первого элемента с имеющемся значением. Если они равны -вернуть значение, иначе выполнить проверку для следующего элемента, если он существует.
- В данном случае он не найден и следующий объект node не равен null.
- Если следующий объект node равен null, возвращаем null.
- Если следующий объект node не равен null, переходим к нему и повторяем первые три шага до тех пор, пока элемент не будет найден или следующий объект node не будет равен null.
// Java программа для иллюстрации // внутренней работы HashMap import java.util.HashMap; class Key < String key; Key(String key) < this.key = key; >@Override public int hashCode() < int hash = (int)key.charAt(0); System.out.println("hashCode for key: " + key + " = " + hash); return hash; >@Override public boolean equals(Object obj) < return key.equals(((Key)obj).key); >> // Driver class public class GFG < public static void main(String[] args) < HashMap map = new HashMap(); map.put(new Key("vishal"), 20); map.put(new Key("sachin"), 30); map.put(new Key("vaibhav"), 40); System.out.println(); System.out.println("Value for key sachin: " + map.get(new Key("sachin"))); System.out.println("Value for key vaibhav: " + map.get(new Key("vaibhav"))); >>hashCode for key: vishal = 118 hashCode for key: sachin = 115 hashCode for key: vaibhav = 118 hashCode for key: sachin = 115 Value for key sachin: 30 hashCode for key: vaibhav = 118 Value for key vaibhav: 40Изменения в Java 8
Как мы уже знаем в случае возникновения коллизий объект node сохраняется в структуре данных «связанный список» и метод equals() используется для сравнения ключей. Это сравнения для поиска верного ключа в связанном списке -линейная операция и в худшем случае сложность равнa O(n).
Для исправления этой проблемы в Java 8 после достижения определенного порога вместо связанных списков используются сбалансированные деревья. Это означает, что HashMap в начале сохраняет объекты в связанном списке, но после того, как колличество элементов в хэше достигает определенного порога происходит переход к сбалансированным деревьям. Что улучшает производительность в худшем случае с O(n) до O(log n).
Важный момент
- Сложность операций get() и put() практически константна до тех пор, пока не будет проведенно повторное хэширование.
- В случае коллизий, если индексы двух и более объектов node одинаковые, объекты node соединяются с помощью связанного списка, т.е. ссылка на второй объект node хранится в первом, на третий во втором и т.д.
- Если данный ключ уже существует в HashMap, значение перезаписывается.
- Хэш код null равен 0.
- Когда объект получается по ключу происходят переходы по связанному списку до тех пор, пока объект не будет найден или ссылка на следующий объект не будет равна null.
Hashmap java получить элемент
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time. This implementation provides constant-time performance for the basic operations (get and put), assuming the hash function disperses the elements properly among the buckets. Iteration over collection views requires time proportional to the «capacity» of the HashMap instance (the number of buckets) plus its size (the number of key-value mappings). Thus, it’s very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important. An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. The capacity is the number of buckets in the hash table, and the initial capacity is simply the capacity at the time the hash table is created. The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets. As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur. If many mappings are to be stored in a HashMap instance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table. Note that using many keys with the same hashCode() is a sure way to slow down performance of any hash table. To ameliorate impact, when keys are Comparable , this class may use comparison order among keys to help break ties. Note that this implementation is not synchronized. If multiple threads access a hash map concurrently, and at least one of the threads modifies the map structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more mappings; merely changing the value associated with a key that an instance already contains is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the map. If no such object exists, the map should be «wrapped» using the Collections.synchronizedMap method. This is best done at creation time, to prevent accidental unsynchronized access to the map:
Map m = Collections.synchronizedMap(new HashMap(. ));
The iterators returned by all of this class’s «collection view methods» are fail-fast: if the map is structurally modified at any time after the iterator is created, in any way except through the iterator’s own remove method, the iterator will throw a ConcurrentModificationException . Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future. Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw ConcurrentModificationException on a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs. This class is a member of the Java Collections Framework.
Nested Class Summary
Nested classes/interfaces inherited from class java.util.AbstractMap
Nested classes/interfaces inherited from interface java.util.Map
Constructor Summary
Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75).