Java Regex – захват групп
Захват групп – это способ рассматривать несколько символов как единое целое. Они создаются путем помещения символов, которые будут сгруппированы, в набор скобок. Например, регулярное выражение (собака) создает одну группу, содержащую буквы «d», «o» и «g».
Захватывающие группы нумеруются путем подсчета открывающих скобок слева направо. В выражении ((A) (B (C))), например, есть четыре такие группы –
Чтобы узнать, сколько групп присутствует в выражении, вызовите метод groupCount для объекта соответствия. Метод groupCount возвращает int, показывающий количество групп захвата, присутствующих в шаблоне сопоставителя.
Существует также специальная группа, группа 0, которая всегда представляет все выражение. Эта группа не включена в общее количество, сообщенное groupCount.
пример
В следующем примере показано, как найти строку цифр из заданной буквенно-цифровой строки:
import java.util.regex.Matcher; import java.util.regex.Pattern; public class RegexMatches public static void main( String args[] ) // String to be scanned to find the pattern. String line = "This order was placed for QT3000! OK?"; String pattern = "(.*)(\\d+)(.*)"; // Create a Pattern object Pattern r = Pattern.compile(pattern); // Now create matcher object. Matcher m = r.matcher(line); if (m.find( )) System.out.println("Found value: " + m.group(0) ); System.out.println("Found value: " + m.group(1) ); System.out.println("Found value: " + m.group(2) ); > else System.out.println("NO MATCH"); > > >
Это даст следующий результат –
Capturing Groups
In the previous section, we saw how quantifiers attach to one character, character class, or capturing group at a time. But until now, we have not discussed the notion of capturing groups in any detail.
Capturing groups are a way to treat multiple characters as a single unit. They are created by placing the characters to be grouped inside a set of parentheses. For example, the regular expression (dog) creates a single group containing the letters «d» «o» and «g» . The portion of the input string that matches the capturing group will be saved in memory for later recall via backreferences (as discussed below in the section, Backreferences).
Numbering
As described in the Pattern API, capturing groups are numbered by counting their opening parentheses from left to right. In the expression ((A)(B(C))) , for example, there are four such groups:
To find out how many groups are present in the expression, call the groupCount method on a matcher object. The groupCount method returns an int showing the number of capturing groups present in the matcher’s pattern. In this example, groupCount would return the number 4 , showing that the pattern contains 4 capturing groups.
There is also a special group, group 0, which always represents the entire expression. This group is not included in the total reported by groupCount . Groups beginning with (? are pure, non-capturing groups that do not capture text and do not count towards the group total. (You’ll see examples of non-capturing groups later in the section Methods of the Pattern Class.)
It’s important to understand how groups are numbered because some Matcher methods accept an int specifying a particular group number as a parameter:
- public int start(int group) : Returns the start index of the subsequence captured by the given group during the previous match operation.
- public int end (int group) : Returns the index of the last character, plus one, of the subsequence captured by the given group during the previous match operation.
- public String group (int group) : Returns the input subsequence captured by the given group during the previous match operation.
Backreferences
The section of the input string matching the capturing group(s) is saved in memory for later recall via backreference. A backreference is specified in the regular expression as a backslash ( \ ) followed by a digit indicating the number of the group to be recalled. For example, the expression (\d\d) defines one capturing group matching two digits in a row, which can be recalled later in the expression via the backreference \1 .
To match any 2 digits, followed by the exact same two digits, you would use (\d\d)\1 as the regular expression:
Enter your regex: (\d\d)\1 Enter input string to search: 1212 I found the text "1212" starting at index 0 and ending at index 4.
If you change the last two digits the match will fail:
Enter your regex: (\d\d)\1 Enter input string to search: 1234 No match found.
For nested capturing groups, backreferencing works in exactly the same way: Specify a backslash followed by the number of the group to be recalled.
Регулярные выражения в Java, часть 4


Предлагаем вашему вниманию перевод краткого руководства по регулярным выражениям в языке Java, написанного Джеффом Фрисеном (Jeff Friesen) для сайта javaworld. Для простоты чтения мы разделили статью на несколько частей. Регулярные выражения в Java, часть 1 Регулярные выражения в Java, часть 2 Регулярные выражения в Java, часть 3
Методы для работы с захватываемыми группами
- Метод int groupCount() возвращает число захватываемых групп в шаблоне сопоставителя. Это количество не учитывает специальную захватываемую группу номер 0, соответствующую шаблону в целом.
- Метод String group() возвращает символы предыдущего найденного совпадения. Чтобы сообщить об успешном поиске по пустой строке, этот метод возвращает пустую строку. Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод String group(int group) напоминает предыдущий метод, за исключением того, что возвращает символы предыдущего найденного совпадения, захваченные группой, номер которой задается параметром group . Обратите внимание, что group(0) эквивалентно group() . Если в шаблоне нет захватываемой группы с заданным номером, метод генерирует исключение IndexOutOfBoundsException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод String group(String name) возвращает символы предыдущего найденного совпадения, захваченные группой name. Если захватываемой группы name в шаблоне нет, генерируется исключение IllegalArgumentException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
Pattern p = Pattern.compile("(.(.(.)))"); Matcher m = p.matcher("abc"); m.find(); System.out.println(m.groupCount()); for (int i = 0; i 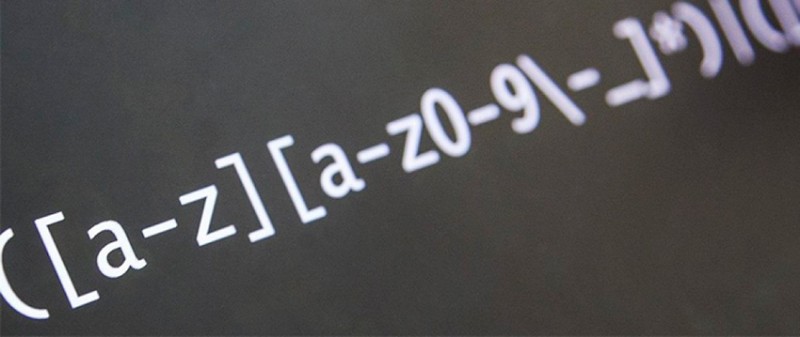
Методы для определения позиций совпадений
- Метод int start() возвращает начальную позицию предыдущего найденного совпадения. Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод int start(int group) напоминает предыдущий метод, но возвращает начальную позицию предыдущего найденного совпадения для группы, номер которой задается параметром group . Если в шаблоне нет захватываемой группы с заданным номером, метод генерирует исключение IndexOutOfBoundsException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод int start(String name) напоминает предыдущий метод, но возвращает начальную позицию предыдущего найденного совпадения для группы с названием name . Если захватываемой группы name в шаблоне нет, генерируется исключение IllegalArgumentException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод int end() возвращает позицию последнего из символов предыдущего найденного совпадения плюс 1. Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод int end(int group) напоминает предыдущий метод, но возвращает конечную позицию предыдущего найденного совпадения для группы, номер которой задается параметром group . Если в шаблоне нет захватываемой группы с заданным номером, метод генерирует исключение IndexOutOfBoundsException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
- Метод int end(String name) напоминает предыдущий метод, но возвращает конечную позицию предыдущего найденного совпадения для группы с названием name . Если захватываемой группы name в шаблоне нет, генерируется исключение IllegalArgumentException . Если сопоставитель еще не выполнял поиска или предыдущая операция поиска завершилась неудачей, генерируется исключение IllegalStateException .
Pattern p = Pattern.compile("(.(.(.)))"); Matcher m = p.matcher("abcabcabc"); while (m.find()) Найдено bc начинается с позиции 1 и заканчивается на позиции 2 Найдено bc начинается с позиции 4 и заканчивается на позиции 5 Найдено bc начинается с позиции 7 и заканчивается на позиции 8 Методы класса PatternSyntaxException
- Метод String getDescription() возвращает описание синтаксической ошибки.
- Метод int getIndex() возвращает или позицию, на которой произошла ошибка, или -1, если позиция неизвестна.
- Метод String getPattern() возвращает ошибочное регулярное выражение.
regex = (?itree input = Treehouse Неправильное регулярное выражение: Unknown inline modifier near index 3 (?itree ^ Описание: Unknown inline modifier Позиция: 3 Неправильный шаблон: (?itree Создание полезных приложений с регулярными выражениями при помощи API Regex

Регулярные выражения позволяют создавать приложения для обработки текста, обладающие большими возможностями. В этом разделе мы покажем вам два удобных приложения, которые, надеемся, побудят вас далее исследовать классы и методы API Regex. Во втором приложении вы познакомитесь с Lexan: библиотекой многоразового кода для выполнения лексического анализа.
Регулярные выражения и документация
Документирование – одна из обязательных задач при разработке профессионально выполненного программного обеспечения. К счастью, регулярные выражения могут помочь вам со многими аспектами создания документации. Код в листинге 1 извлекает строки, содержащие однострочные и многострочные комментарии в стиле языка C, из исходного файла и записывает их в другой файл. Чтобы код работал, комментарии должны быть расположены в одной строке. Листинг 1. Извлечение комментариев
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.regex.PatternSyntaxException; public class ExtCmnt < public static void main(String[] args) < if (args.length != 2) < System.err.println("Способ применения: java ExtCmnt infile outfile"); return; >Pattern p; try < // Следующий шаблон определяет многострочные комментарии, // располагающиеся в одной строке (например, /* одна строка */) // и однострочные комментарии (например, // какая-то строка). // Комментарий может располагаться в любом месте строки. p = Pattern.compile(".*/\\*.*\\*/|.*//.*$"); >catch (PatternSyntaxException pse) < System.err.printf("Синтаксическая ошибка в регулярном выражении: %s%n", pse.getMessage()); System.err.printf("Описание ошибки: %s%n", pse.getDescription()); System.err.printf("Позиция ошибки: %s%n", pse.getIndex()); System.err.printf("Ошибочный шаблон: %s%n", pse.getPattern()); return; >try (FileReader fr = new FileReader(args[0]); BufferedReader br = new BufferedReader(fr); FileWriter fw = new FileWriter(args[1]); BufferedWriter bw = new BufferedWriter(fw)) < Matcher m = p.matcher(""); String line; while ((line = br.readLine()) != null) < m.reset(line); if (m.matches()) /* Должна соответствовать вся строка */ < bw.write(line); bw.newLine(); >> > catch (IOException ioe) < System.err.println(ioe.getMessage()); return; >> > Метод main() из листинга 1 сначала проверяет правильность синтаксиса командной строки, после чего компилирует предназначенное для обнаружения одно- и многострочных комментариев регулярное выражение в объект класса Pattern . Если не возникает исключения PatternSyntaxException , метод main() открывает исходный файл, создает целевой файл, получает сопоставитель для сопоставления каждой прочитанной строки с шаблоном, после чего читает исходный файл построчно. Для каждой строки выполняется сопоставление её с шаблоном комментария. В случае успеха, метод main() записывает строку (с последующим символом новой строки) в целевой файл (мы рассмотрим логику файлового ввода/вывода в будущем учебном пособии Java 101). Скомпилируйте листинг 1 следующим образом: javac ExtCmnt.java Выполните приложение с файлом ExtCmnt.java в качестве входного: java ExtCmnt ExtCmnt.java out Вы должны получить в файле out следующие результаты:
// Следующий шаблон определяет многострочные комментарии, // располагающиеся в одной строке (например, /* одна строка */) // и однострочные комментарии (например, // какая-то строка). // Комментарий может располагаться в любом месте строки. p = Pattern.compile(".*/\\*.*\\*/|.*//.*$"); if (m.matches()) /* Должна соответствовать вся строка */ В строке шаблона .*/\\*.*\\*/|.*//.*$ , метасимвол вертикальной черты | играет роль логического оператора ИЛИ, указывающего на необходимость сопоставителю использовать левый операнд из конструкции данного регулярного выражения для поиска соответствия в тексте сопоставителя. Если соответствий нет, сопоставитель использует правый операнд из конструкции данного регулярного выражения для еще одной попытки поиска (метасимволы скобок в захватываемой группе тоже формируют логический оператор). Регулярные выражения в Java, часть 5