Как построить эмпирический cdf в matplotlib в Python?
Как я могу построить эмпирическую CDF массива чисел в matplotlib в Python? Я ищу cdf аналог функции «hist» pylab. Я могу думать об одном:
from scipy.stats import cumfreq a = array([. ]) # my array of numbers num_bins = 20 b = cumfreq(a, num_bins) plt.plot(b) 16 ответы
Похоже, это (почти) именно то, что вы хотите. Две вещи: Сначала результаты представляют собой кортеж из четырех элементов. Третий — это размер мусорных ведер. Вторая — начальная точка самого маленького бункера. Первый — это количество точек в каждой ячейке или под ней. (Последнее — это количество точек, выходящих за пределы, но, поскольку вы не установили ни одного, все точки будут объединены.) Во-вторых, вы захотите изменить масштаб результатов, чтобы окончательное значение было 1, чтобы следовать обычным соглашениям CDF, но в остальном это правильно. Вот что он делает под капотом:
def cumfreq(a, numbins=10, defaultreallimits=None): # docstring omitted h,l,b,e = histogram(a,numbins,defaultreallimits) cumhist = np.cumsum(h*1, axis=0) return cumhist,l,b,e Он выполняет гистограмму, а затем производит кумулятивную сумму подсчетов в каждой ячейке. Таким образом, i-е значение результата — это количество значений массива, меньшее или равное максимуму i-го интервала. Итак, окончательное значение — это просто размер исходного массива. Наконец, чтобы построить его, вам нужно будет использовать начальное значение корзины и размер ячейки, чтобы определить, какие значения по оси X вам понадобятся. Другим вариантом является использование numpy.histogram который может выполнять нормализацию и возвращать края бункера. Вам нужно будет самостоятельно подсчитать совокупную сумму полученных результатов.
a = array([. ]) # your array of numbers num_bins = 20 counts, bin_edges = numpy.histogram(a, bins=num_bins, normed=True) cdf = numpy.cumsum(counts) pylab.plot(bin_edges[1:], cdf) Просто небольшое примечание: этот код на самом деле не дает вам Empirical CDF (пошаговая функция, увеличивающаяся на 1 / n в каждой из n точек данных). Вместо этого этот код дает оценку CDF на основе оценки PDF на основе гистограммы. Этой оценкой на основе гистограммы можно манипулировать / искажать путем тщательного / неправильного выбора интервалов, поэтому она не так хорошо характеризует истинный CDF, как фактический ECDF. — David B.
Мне также не нравится то обстоятельство, что это налагает биннинг; см. короткий ответ Дэйва, который просто использует numpy.sort для построения CDF без биннинга. — hans_meine
plt.plot(np.sort(a), np.linspace(0, 1, len(a), endpoint=False)) # a is the data array x = np.sort(a) y = np.arange(len(x))/float(len(x)) plt.plot(x, y) Что работает для меня, даже если есть >O(1e6) значения данных. Если вам действительно нужно уменьшить образец, я бы установил
x = np.sort(a)[::down_sampling_step] Редактировать чтобы ответить на комментарий / отредактировать, почему я использую endpoint=False или y как определено выше. Ниже приведены некоторые технические детали. Эмпирический CDF обычно формально определяется как
чтобы точно соответствовать этому формальному определению, вам нужно будет использовать y = np.arange(1,len(x)+1)/float(len(x)) чтобы мы получили y = [1/N, 2/N . 1] . Эта оценка представляет собой несмещенную оценку, которая сходится к истинному CDF в пределах бесконечных выборок. Википедия исх.. Я обычно использую y = [0, 1/N, 2/N . (N-1)/N] так как (а) легче кодировать / более идоматичнее, (б), но формально все еще оправдано, так как всегда можно обменять CDF(x) 1-CDF(x) в доказательстве сходимости, и (c) работает с (простым) методом понижающей дискретизации, описанным выше. В некоторых частных случаях полезно определить
который занимает промежуточное положение между этими двумя соглашениями. Что, по сути, гласит: «существует 1/(2N) шанс получить значение меньше самого низкого, которое я видел в своей выборке, и 1/(2N) шанс получить значение больше, чем самый большой, который я видел до сих пор. Обратите внимание, что выбор этого соглашения взаимодействует с where параметр, используемый в plt.step , если кажется более полезным отобразить CDF как круговую постоянную функцию. Чтобы точно соответствовать формальному определению, упомянутому выше, необходимо использовать where=pre предложенный y=[0,1/N. 1-1/N] конвенция, или where=post с y=[1/N, 2/N . 1] условности, но не наоборот. Однако для больших выборок и разумных распределений соглашение, приведенное в основной части ответа, легко написать, оно представляет собой беспристрастную оценку истинного CDF и работает с методологией понижающей дискретизации.
Как в python можно реализовать эмпирическую функцию распределения?
Здравствуйте, мне бы хотелось узнать как можно реализовать в python отрисовку эмперической функции вида:
с выборкой:
[-1.97, -0.736, -0.152, -0.049, -0.044, -0.029, 0.089, 0.306, 0.349, 0.413,
0.48, 0.518, 0.666, 0.691, 0.748, 0.834, 0.865, 0.866, 0.929, 0.974,
1.024, 1.096, 1.138, 1.197, 1.221, 1.258, 1.296, 0.426, 1.461, 1.537,
1.589, 1.679, 1.783, 1.833, 1.9, 1.922, 1.938, 1.954, 1.965, 1.976,
2.039, 2.047, 2.076, 2.261, 2.295, 2.453, 2.569, 2.604, 2.963, 3.031]
Пробовал в matplotlab и tkinter но дальше ступенчатой не ушел, заранее спасибо за помощь!
Простой 3 комментария

plt.hist(lst, histtype='step', cumulative=True, bins=len(lst))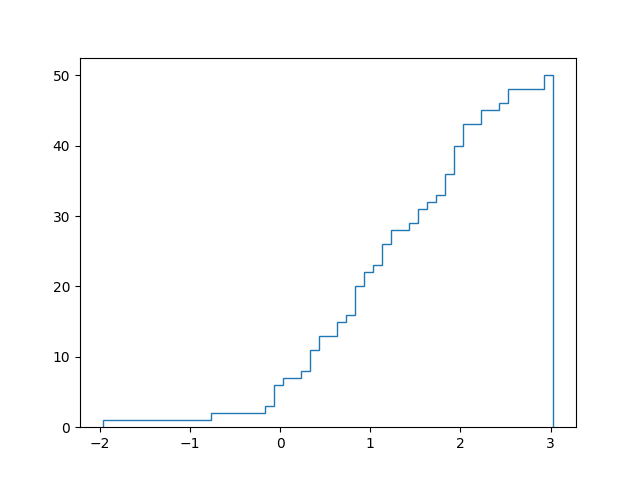
результат:
bin_dt, bin_gr = np.histogram(lst, bins=len(lst)) Y = bin_dt.cumsum() for i in range(len(Y)): plt.plot([bin_gr[i], bin_gr[i+1]],[Y[i], Y[i]],color='green')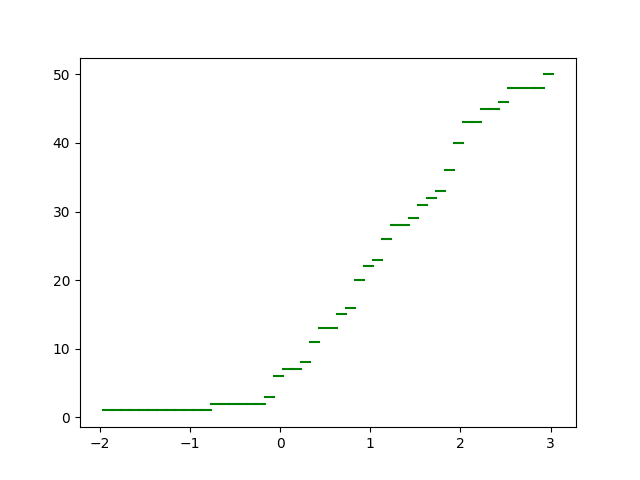
Результат:
import seaborn as sns sns.kdeplot(lst, cumulative=True)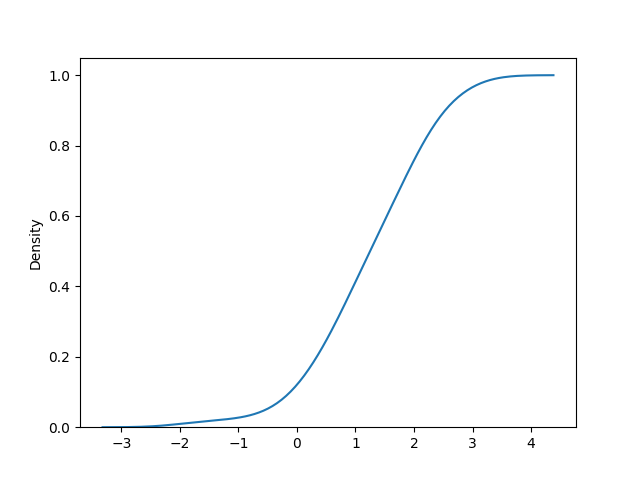
Результат:
Здравствуйте, спасибо за ваш ответ. Там расстояния разные, так как точки некоторые в выборке повторяются, а такого быть по идее не должно, у меня тоже был подобный результат как вы привели во втором примере, меня интересует как можно проблему с разными расстояниями решить чтобы диапазон был от 0 до 1 как в примере который я указывал в вопросе.
DemonDED,
Какие «разные расстояния»? Между чем и чем? Более того, какие «повторяющиеся точки» в вашей выборке? Покажите их в вашем примере?
Во-вторых. Вы запросили построение эмпирической функции распределения. Она и построена. Для построения эмпирической функции по оси Х откладываются значения ваших данных (это — из определения функции распределения). Откуда там на вашем рисунке может взяться 1,2,3. 10, если ваши данные находятся в диапазоне от -1.97 до +3.3?
В-третьих. По определению эмпирическая функция распределения в случае дискретных значений строиться так: для каждой точки х вашей выборки, откладываемой по оси Х, значением Y есть вероятность того, что наугад взятый элементов вашей выборке окажется меньшим, чем значение х. (ну, или если совсем «по-простому», доля элементов выборки менших х). Для того, что бы из моих рисунков 1 и 2 действительно получить eCDF, надо значения по оси Y разделить на количество элементов в выборке. На форму самого графика это не повлияет никак, а значения по оси Y просто окажутся пронормированы от 0 до 1. Я это не сделал, но надеюсь для вас дополнить соответствующим образом скрипты сложности не представит.
Ну и в-четвертых. Я построил то что вы просили — эмпирическую функцию распределения. Построил строго по определению. Из вашего комментария к моему вопросу можно заключить, что на самом деле вы хотели построить что-то другое но почему-то решили назвать это «эмпирической функцией распределения». Но что именно — ведомо только вам одному. Поэтому, если нужна дальнейшая помощь, сформулируйте четко и однозначно, желательно в общепринятой терминологии и не используя термины не по назначению, что-же за такой дивный график у вас должен получиться и что именно на нем должно быть отображено.
dmshar, расстояния изменяются по оси ОУ, как верно было подмечено, на которой у нас отмечена вероятность «достать конкретный элемент выборки».
под расстояниями подразумевается разность, между вероятностью предписанной на графике элементу Х(к) и Х(к-1) (в скобочках индексы).
так как выборка — это набор одинаково распределенных и независимых величин, то вероятность вытащить любой элемент будет равна вероятности вытащить любой другой элемент.
в предоставленной выборке значения не повторяются — то есть, попасть в любое значение точно так же имеет вероятность равную попасть в любое другое значение => эти расстояния должны быть равны
при этом, каждая вероятность отмеченная на графике эфр = Р(Хi то есть если слева от t у нас 7 элементов выборки (коих всего 50, допустим), то значение на оси ОУ в этой точке будет равно 7/50
соответственно, рассматривая это в каждой точке, мы получим, что все «расстояния» должн быть равны 1/50 по ОУ
Как построить эмпирический Cdf в Matplotlib в Python?
Как я могу построить эмпирический CDF массива чисел в matplotlib в Python? Я ищу cdf-аналог функции «hist» pylab. Одна вещь, о которой я могу думать, — это:
from scipy.stats import cumfreq a = array([. ]) # my array of numbers num_bins = 20 b = cumfreq(a, num_bins) plt.plot(b) 14 ответов
Это похоже на то, что вы хотите. Две вещи: Во-первых, результаты представляют собой набор из четырех элементов. Третий размер бункеров. Вторая — начальная точка самого маленького бункера. Первое — это количество точек в каждом или ниже каждого бункера. (Последнее — количество точек вне пределов, но поскольку вы не задали никаких параметров, все точки будут закодированы.) Во-вторых, вы захотите перемасштабировать результаты, чтобы окончательное значение равно 1, чтобы следовать обычным соглашениям CDF, но в остальном это правильно. Вот что он делает под капотом:
def cumfreq(a, numbins=10, defaultreallimits=None): # docstring omitted h,l,b,e = histogram(a,numbins,defaultreallimits) cumhist = np.cumsum(h*1, axis=0) return cumhist,l,b,e Выполняет гистограммирование, затем производит суммарную сумму отсчетов в каждом бункере. Таким образом, i-е значение результата — это количество значений массива, меньшее или равное максимальному значению i-го бина. Итак, конечное значение — это только размер исходного массива. Наконец, чтобы построить его, вам нужно будет использовать начальное значение bin и размер бункера, чтобы определить, какие значения оси x вам понадобятся. Другой вариант — использовать numpy.histogram , который может выполнять нормализацию и возвращает края бункера. Вам нужно будет сделать кумулятивную сумму полученных результатов.
a = array([. ]) # your array of numbers num_bins = 20 counts, bin_edges = numpy.histogram(a, bins=num_bins, normed=True) cdf = numpy.cumsum(counts) pylab.plot(bin_edges[1:], cdf) Просто небольшое замечание: этот код на самом деле не дает вам эмпирический CDF (пошаговая функция, увеличивающаяся на 1 / n в каждой из n точек данных). Вместо этого этот код дает оценку CDF на основе оценки PDF на основе гистограммы. Этой оценкой на основе гистограммы можно манипулировать / смещать путем тщательного / неправильного выбора корзин, поэтому она не так хороша для характеристики истинного CDF, как фактическая ECDF.
Мне также не нравится, что это накладывает биннинг; см. короткий ответ Дейва, который просто использует numpy.sort для построения CDF без биннинга.
Вы можете использовать функцию ECDF из scikits.statsmodels библиотека:
import numpy as np import scikits.statsmodels as sm import matplotlib.pyplot as plt sample = np.random.uniform(0, 1, 50) ecdf = sm.tools.ECDF(sample) x = np.linspace(min(sample), max(sample)) y = ecdf(x) plt.step(x, y) С версией 0.4 scicits.statsmodels было переименовано в statsmodels . ECDF теперь находится в модуле distributions (в то время как statsmodels.tools.tools.ECDF обесценивается).
import numpy as np import statsmodels.api as sm # recommended import according to the docs import matplotlib.pyplot as plt sample = np.random.uniform(0, 1, 50) ecdf = sm.distributions.ECDF(sample) x = np.linspace(min(sample), max(sample)) y = ecdf(x) plt.step(x, y) plt.show()