- Return HTML content as a string, given URL. Javascript Function
- 6 Answers 6
- You can’t do this in the general case
- How to convert an HTML document to a text document
- Copy and paste web page text in a text document
- Save HTML web page as a text document (losing HTML code)
- Internet Explorer
- Google Chrome
- Mozilla Firefox
- Convert HTML file to a text file (preserving HTML code and text)
- Internet Explorer
- Google Chrome
- Mozilla Firefox
- Related information
- Get HTML source code as a string
- 6 Answers 6
- get web page text via javascript [closed]
- 4 Answers 4
Return HTML content as a string, given URL. Javascript Function
I want to write a javascript function that returns HTML content as string given URL to the function. I found a similar answer on Stackoverflow. I am trying to use this answer to solve my problem. However, it seems as though document.write() isn’t writing anything. When I load the page, I get a a blank screen.
Chrome 77.0.3865.90, getting warning (index):40 [Deprecation] Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end user’s experience. For more help, check https://xhr.spec.whatwg.org/.
6 Answers 6
you need to return when the readystate==4 e.g.
function httpGet(theUrl) < if (window.XMLHttpRequest) else xmlhttp.onreadystatechange=function() < if (xmlhttp.readyState==4 && xmlhttp.status==200) < return xmlhttp.responseText; >> xmlhttp.open("GET", theUrl, false ); xmlhttp.send(); > xmlhttp.open(«GET», theUrl, false ) is not supported on the main thread. See stackoverflow.com/q/14220321
The only one i have found for Cross-site, is this function:
after you get the response just do call this function to append data to your body element
function createDiv(responsetext)
@satya code modified as below
function httpGet(theUrl) < if (window.XMLHttpRequest) else xmlhttp.onreadystatechange=function() < if (xmlhttp.readyState==4 && xmlhttp.status==200) < createDiv(xmlhttp.responseText); >> xmlhttp.open("GET", theUrl, false); xmlhttp.send(); > You can’t do this in the general case
. because of the Same Origin Policy that browsers use to restrict access to Site B from code running on Site A. When you try (with XMLHttpRequest or fetch etc.), you’ll get an error saying something along the lines of:
No ‘Access-Control-Allow-Origin’ header is present on the requested resource
More in this question’s answers and the SOP link above. But basically: It’s not about preventing people seeing Site B’s content, it’s about not being able to do so from a context (a browser) that may have stored authentication information for the current user that would reveal their private information if you could read Site B’s content from that user’s browser.
A very small number of websites may serve their content using Cross Origin Resource Sharing headers (the aforementioned Access-Control-Allow-Origin and others) to allow any site to read their content, but that’s very unusual.
If you want to retrieve the content of the vast majority of sites, you’ll have to use code running in a non-browser context to do it (for instance, code running on a server somewhere). Over the years there have been many sites that allowed you to query them with a URL and return you the content of that URL queried by their server (and so not subject to the SOP, because the current user’s browser-based authentication information for the other site isn’t used), but they tend to spring up and then go away again as there’s not really a good revenue model to support the bandwidth requirements. After all, why pay someone else for that when you can just run your own server for cheap (or even free) and do it yourself.
How to convert an HTML document to a text document


A web page is made up of plain text and HTML (hypertext markup language) programming code that is used to load pictures and basic formatting of text (e.g., bold, italics, and color). To preserve the spacing and formatting on a web page, it is often saved with a .HTM or .HTML file extension. However, there may be a need to save the text on the web page as a text document or file. Below are several methods for converting, or saving, an HTML web page as a text document.
Copy and paste web page text in a text document
To save the text on a web page as a text document, follow the steps below.
- Access the web page containing the text you want to save as a text document.
- Highlight the text on the web page that you want to save in a text document.
- Copy the highlighted text.
- Open a text-based application, like Notepad.
- In the text application, paste the text you copied.
- Save the file, creating the text document.
Save HTML web page as a text document (losing HTML code)
To save the text, and any formatting of the text, as a text document, follow the steps below.
Microsoft Word must be installed on your computer to utilize the steps below.
- Access the web page you want to save as a text document.
- Save the web page as a web page file (.HTM or .HTML file extension). See the details below on how to save the file in Internet Explorer, Google Chrome, and Mozilla Firefox.
Internet Explorer
- Press the Alt to make the File/Edit/View menu visible. Click the File menu and select Save as.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.

Google Chrome
- Right-click the web page and select the Save as option.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.
Mozilla Firefox
- Right-click the web page and select the Save Page As option.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.
In Firefox, instead of selecting the Webpage, complete Save as type option, you can select the Text Files option to save the web page directly to a text document.
- Open the Microsoft Word application.
- Click the File tab, then click the Open option.
- Next to the File name field, in the file type drop-down list, select the All Web Pages option.
- Browse to find the web page file you saved from above. Select the file and click the Open button.
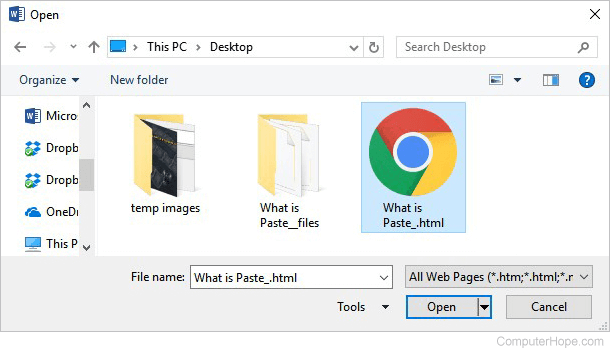
- Click the File tab again, then click the Save as option.
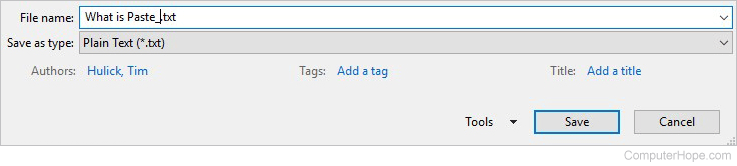
- In the Save as type drop-down list, select the Plain Text (*.txt) option. Additionally, you may need to change the file extension in the File name field to be txt, if it does not automatically change.
- Click the Save button to save as a text document.
Convert HTML file to a text file (preserving HTML code and text)
To save a web page as a text document, and preserve the HTML code that provides formatting of the text, follow the steps below.
While the resulting file is a text file, it contains HTML programming code with the text.
- Access the web page you want to save as a text document.
- Save the web page as a web page file (.HTM or .HTML file extension). See the details below on how to save the file in Internet Explorer, Google Chrome, and Mozilla Firefox.
Internet Explorer
- Press the Alt to make the File/Edit/View menu visible. Click the File menu and select Save as.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.
Google Chrome
- Right-click the web page and select the Save as option.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.
Mozilla Firefox
- Right-click the web page and select the Save Page As option.
- Select the location where you want to save the web page file and make sure the Webpage, complete option is selected in the Save as type drop-down list.
- Click the Save button.
In Firefox, do not select the Text Files Save as type option, as it only saves the text on the web page and does not preserve the HTML code.
- Right-click the saved web page file and select the Open with option.
- In the Open with menu that appears, select the Choose another app option.
- Find and select the Notepad program in the list of applications, then click the OK button.
- Once Notepad is open with the HTML code, click File, then Save as, choose the location where you want to save the file, then click the Save button to save as a text document.
Related information
Get HTML source code as a string
I want the source code of an HTML page ( 1.html ) to be used in another page ( 2.html ). Furthermore, I want to perform operations on it in 2.html . Is there a way to do this? EDIT: 1.html is a separate public webpage and I do not have access to make changes to its source code. I have to do whatever I need only by using 2.html .
Do you want to get the whole content of 1.html page from 2.html using jQuery? You could make an AJAX request and get it if I understood right what you want to do.
@Pekka: Simple operations like extracting some innerHTML from 1.html and displaying it into 2.html Aldo ‘xeon’: its a cross domain request, so AJAX does not work.
6 Answers 6
To get the DOM converted to a string:
document.getElementsByTagName('html')[0].innerHTML Question: what do you mean by «use it»? Do you need to include 1.html inside 2.html? Or do you just need to process it?
.innerHTML doesn’t actually return the source code, it generates html to correspond to the current DOM tree. Subtle difference, but still.
a source code is the unprocessed html that the website developer wrote. innerHTML would give the DOM converted into a string. A DOMed html would have been fixed for html errors (with varying degree) and javascript changes would be refledted in it.
reflected. Also, check the OP’s comment to his own post: he needs elements from that page to display them again somewhere else. The correct DOM here suits him best. Asking for the «source code» of a page isn’t really feasible unless you have direct access to the original, unprocessed, unfiltered by the server, file. I hope he’s fine now, 2 years after.
get web page text via javascript [closed]
It’s difficult to tell what is being asked here. This question is ambiguous, vague, incomplete, overly broad, or rhetorical and cannot be reasonably answered in its current form. For help clarifying this question so that it can be reopened, visit the help center.
4 Answers 4
You could do it with Range s / TextRange s. This has the advantage of only getting the visible text on the page (unlike, for example, the textContent property of elements in non-IE browsers, which will also get you the contents of and possibly other elements). The following will work in all mainstream browsers although I can’t make any guarantees about the consistency of line breaks between different browsers.
UPDATE November 2012
I don’t think this is a good idea these days. While Selection is now specified, its toString() method is not, and for some time (including when Microsoft were implementing it for IE 9) it was specified to behave like textContent . For this particular method, browser consistency has got worse rather than better since 2009.
function getBodyText(win) < var doc = win.document, body = doc.body, selection, range, bodyText; if (body.createTextRange) < return body.createTextRange().text; >else if (win.getSelection) < selection = win.getSelection(); range = doc.createRange(); range.selectNodeContents(body); selection.addRange(range); bodyText = selection.toString(); selection.removeAllRanges(); return bodyText; >> alert( getBodyText(window) );