- Java: Extract Text and Images from Word
- Install Spire.Doc for Java
- Extract Text from Word in Java
- Extract Images from Word in Java
- Apply for a Temporary License
- See Also
- Java/ Extract Text from a Word Document
- Extract Text from Markdown Files in Java
- Java API for Markdown Text Extraction#
- Extract Text from Markdown File in Java#
- Get a Free API License#
- Conclusion#
- See Also#
- How to extract content from a text document using Java
- Solution
- Input
- Output
- Extract Text from PDF using Java
- Java API to Extract Text from PDF — Free Download#
- Extract Text from PDF using Java#
- Extract Text from Specific Page in PDF#
- Extract Text from a Page Region in PDF#
- Conclusion#
- See Also#
Java: Extract Text and Images from Word
Text and images are crucial elements that can enrich the content of a Word document. When users need to manipulate text or images separately of the document, programmatically extracting them from a Word document provides an optimal solution. Extracting text guarantees greater convenience and efficiency when dealing with large documents compared to manually copying text. Additionally, image extraction enables users to perform further editing on the images of the document or effortlessly share them with others. In this article, we will demonstrate how to extract text and images from Word in Java by using Spire.Doc for Java library.
Install Spire.Doc for Java
First of all, you’re required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project’s pom.xml file.
com.e-iceblue e-iceblue https://repo.e-iceblue.com/nexus/content/groups/public/ e-iceblue spire.doc 11.7.0
Extract Text from Word in Java
Spire.Doc for Java supports extracting text from Word documents and saving it as a text file format, which allows users to view text content without device restrictions. Below are detailed steps for extracting text from a Word document.
- Create a Document object.
- Load a word document using Document.loadFromFile method.
- Get text from document as string using Document.getText() method.
- Call writeStringToTxt() method to write string to a specified text file.
import com.spire.doc.Document; import java.io.FileWriter; import java.io.IOException; public class ExtractText < public static void main(String[] args) throws IOException < //Create a Document object and load a Word document Document document = new Document(); document.loadFromFile("sample1.docx"); //Get text from document as string String text=document.getText(); //Write string to a .txt file writeStringToTxt(text," ExtractedText.txt"); >public static void writeStringToTxt(String content, String txtFileName) throws IOException< FileWriter fWriter= new FileWriter(txtFileName,true); try < fWriter.write(content); >catch(IOException ex)< ex.printStackTrace(); >finally < try< fWriter.flush(); fWriter.close(); >catch (IOException ex) < ex.printStackTrace(); >> > > 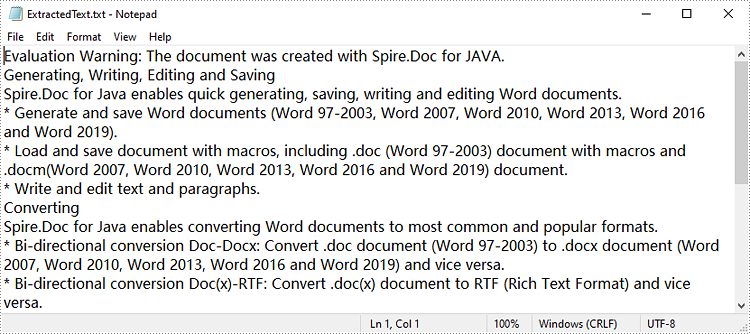
Extract Images from Word in Java
By extracting images, users are able to import image data into other applications for further processing without difficulty. Spire.Doc for Java allows users to extract images from Word documents and save them to the specified path. The following are detailed steps.
- Create a Document object.
- Load a Word document using Document.loadFromFile() method.
- Create a queue of composite objects.
- Add the root document element to the traversal queue using Queue.add(ICompositeObject e) method.
- Create a ArrayList object to store extracted images.
- Traverse the document tree and check for composite or picture objects by iterating over the children node of each node.
- Check if the child element is a composite object. If so, add it to the queue for further processing.
- Check if the child element is a picture object. If so, extract its image data and add it to the extracted image list.
- Save images to the specific folder using ImageIO.write(RenderedImage im, String formatName, File output) method.
import com.spire.doc.*; import com.spire.doc.documents.*; import com.spire.doc.fields.*; import com.spire.doc.interfaces.*; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.*; import java.util.*; public class ExtractImage < public static void main(String[] args) throws IOException < //Create a Document object and load a Word document Document document = new Document(); document.loadFromFile("sample2.docx"); //Create a queue and add the root document element to it Queuenodes = new LinkedList<>(); nodes.add(document); //Create a ArrayList object to store extracted images List images = new ArrayList<>(); //Traverse the document tree while (nodes.size() > 0) < ICompositeObject node = nodes.poll(); for (int i = 0; i < node.getChildObjects().getCount(); i++) < IDocumentObject child = node.getChildObjects().get(i); if (child instanceof ICompositeObject) < nodes.add((ICompositeObject) child); >else if (child.getDocumentObjectType() == DocumentObjectType.Picture) < DocPicture picture = (DocPicture) child; images.add(picture.getImage()); >> > //Save images to the specific folder for (int i = 0; i < images.size(); i++) < File file = new File(String.format("output/extractImage-%d.png", i)); ImageIO.write(images.get(i), "PNG", file); >> > 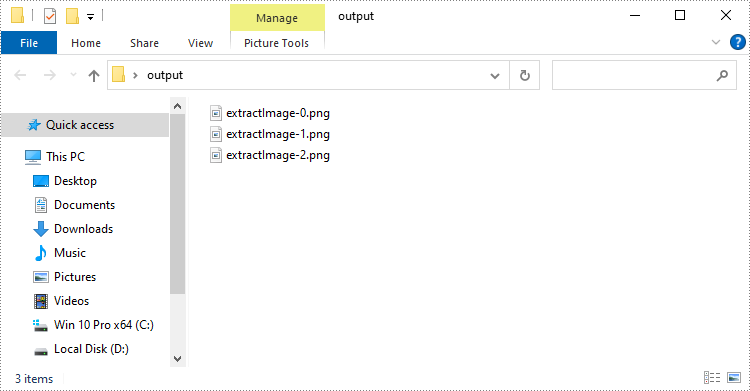
Apply for a Temporary License
If you’d like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
See Also
Java/ Extract Text from a Word Document
TXT is a common text format that can be used on many computers and mobile devices. The TXT document is known for its small size, and it makes the storage of text content more convenient. This article will demonstrate how to extract the text content in a Word document and save it as .txt format by using Free Spire.Doc for Java. Import JAR Dependency to Your Java Application
Method 1: Download the Free Spire.Doc for Java and unzip it. Then add the Spire.Doc.jar file to your Java application as dependency.
Method 2: You can also add the jar dependency to maven project by adding the following configurations to the pom.xml.
com.e-iceblue e-iceblue http://repo.e-iceblue.com/nexus/content/groups/public/ e-iceblue spire.doc.free 3.9.0 import com.spire.doc.Document; import java.io.FileWriter; import java.io.IOException; public class ExtractText public static void main(String[] args) throws IOException //Load Word document Document document = new Document(); document.loadFromFile("Island.docx"); //Get text from document as string String text=document.getText(); //Write string to a .txt file writeStringToTxt(text," Extracted.txt"); > public static void writeStringToTxt(String content, String txtFileName) throws IOException FileWriter fWriter= new FileWriter(txtFileName,true); try fWriter.write(content); >catch(IOException ex) ex.printStackTrace(); >finally try fWriter.flush(); fWriter.close(); > catch (IOException ex) ex.printStackTrace(); > > > > Extract Text from Markdown Files in Java
Developers often have requirements to extract text from various documents. We have already discussed extracting ZIP archives, counting words in documents, extracting images from eBooks, and a few other parsing ways. Today, in this article, you will learn how to parse and extract text from the Markdown files in Java.

Java API for Markdown Text Extraction#
GroupDocs provides Java API to parse documents and extract text from various document formats within the Java applications. The API supports parsing of many file formats like:
- Word-processing Documents: DOC, DOCX, …
- Spreadsheets: XLS, XLSX, …
- Presentations: PPT, PPTX, ….
- eBooks: EPUB, FB2, …
- Barcode images: JPG, PNG, …
- The complete list is mentioned in the documentation.
In this article, we will use its GroupDocs.Parser for Java to only extract text from the MD files using Java.
You may download the JAR file from the downloads section, or just get the repository and dependency configurations for the pom.xml of your maven-based Java applications.
groupdocs-artifacts-repository GroupDocs Artifacts Repository https://releases.groupdocs.com/java/repo/ com.groupdocs groupdocs-parser 22.6 Extract Text from Markdown File in Java#
The following are the steps to extract the whole text content from the markdown file in Java.
- Load the MD file using the Parser class.
- Extract the whole text into TextReader using the getText method.
- Use the text as you wish.
The following Java source code extracts the textual content of the MD file.
Get a Free API License#
You can get a free temporary license to use the API without the evaluation limitations.
Conclusion#
To sum up, the article explained the basic and quick way how to extract text from the markdown files in Java. This approach may have let you think to develop your text extraction and document parser application like the Online Document Parser developed by GroupDocs.
You can learn more about document parsing Java API using its documentation. The quick way to learn is to experience the examples that are available on GitHub. Contact us for any query via the forum.
See Also#
How to extract content from a text document using Java
How to extract content from a text document using java.
Solution
Following is the program to extract content from a text document using java.
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.ParseContext; import org.apache.tika.sax.BodyContentHandler; import org.apache.tika.parser.txt.TXTParser; import org.xml.sax.SAXException; public class ExtractContentFromTextDoc < public static void main(String[] args) throws Exception < //detecting the file type BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(new File( "C:/tika/textExample.txt")); ParseContext pcontext = new ParseContext(); //Text document parser TXTParser TexTParser = new TXTParser(); TexTParser.parse(inputstream, handler, metadata,pcontext); System.out.println("Contents of the document:" + handler.toString()); System.out.println("Metadata of the document:"); String[] metadataNames = metadata.names(); for(String name : metadataNames) < System.out.println(name + " : " + metadata.get(name)); >> > Input
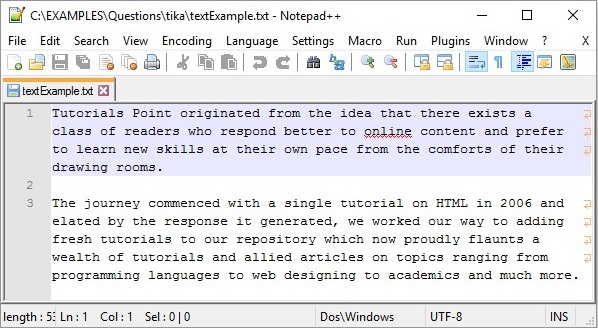
Output
Contents of the document: Tutorials Point originated from the idea that there exists a class of readers who respond better to online content and prefer to learn new skills at their own pace from the comforts of their drawing rooms. The journey commenced with a single tutorial on HTML in 2006 and elated by the response it generated, we worked our way to adding fresh tutorials to our repository which now proudly flaunts a wealth of tutorials and allied articles on topics ranging from programming languages to web designing to academics and much more. Metadata of the document: Content-Encoding : windows-1252 Content-Type : text/plain; charset = windows-1252
Extract Text from PDF using Java

In this post, you will learn how to extract text from PDF files seamlessly using Java. Text extraction could be useful in various scenarios such as text analysis, information retrieval, document parsing, and so on. Since PDF is one of the most widely used digital documents, the use cases of text extraction from PDF documents are more in number. So let’s begin and check how to perform PDF text extraction from within Java applications.
Java API to Extract Text from PDF — Free Download#
Aspose.PDF for Java is a well-known PDF file manipulation API that provides a wide range of features to create and process PDF files. The API contains a powerful text extractor that provides various ways of extracting text from PDF documents within a few lines of code. You can either download the API’s JAR or install it within your Maven-based applications using the following configurations.
AsposeJavaAPI Aspose Java API https://repository.aspose.com/repo/ Extract Text from PDF using Java#
The following are the steps to extract text from a PDF document using Aspose.PDF for Java.
- Use Document class to load the PDF file.
- Create an object of TextAbsorber class.
- Accept the TextAbsorber for all pages of the PDF using Document.getPages().accept(TextAbsorber) method.
- Use TextAbsorber.getText() method to fetch all the text from the PDF.
- Save the text into a TXT file (optional).
The following code sample shows how to extract text from PDF using Java.
Extract Text from Specific Page in PDF#
You can also extract text from a specific page of the PDF document using the following steps.
- Use Document class to load the PDF file.
- Create an instance of TextDevice class.
- Define additional options using TextExtractionOptions class.
- Set options using TextDevice.setExtractionOptions(TextExtractionOptions) method.
- Use TextDevice.Process(Page, String) to extract the text from the specified page.
The following code sample shows how to extract text from a specific page in PDF using Java.
Extract Text from a Page Region in PDF#
You can also extract text from a particular region of the page in PDF. For this, you can define a rectangle to cover the region from where you need to extract the text. The following are the steps to extract text from a page region.
- Use Document class to load the PDF file.
- Create an object of TextAbsorber class.
- Set limit to page bound and create a rectangle using TextAbsorber.getTextSearchOptions().setLimitToPageBounds(true) and TextAbsorber.getTextSearchOptions().setRectangle(new Rectangle(100, 200, 250, 350)) methods respectively.
- Accept the absorber for the particular page.
- Use TextAbsorber.getText() method to extract text.
The following code sample shows how to extract text from a particular page region in Java.
Conclusion#
In this article, you have learned how to extract text from PDF using Java. You have seen various ways of text extraction such as extracting text from a whole PDF, a specific page, or a specific page region. You can learn more about the Java PDF API using documentation.
See Also#
Info: Aspose recently developed a free online Text to GIF service that allows you to animate texts or generate GIFs from simple texts.