- Saved searches
- Use saved searches to filter your results more quickly
- License
- ClickHouse/clickhouse-connect
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- A Python client working example for connecting to ClickHouse Cloud Service
- Steps
- Introduction
- Requirements
- Setup
- ClickHouse installation
- Python environment
- Integration
- SQLAlchemy setup
- DDL
- Create a new database
- Create a new table
- ORM model definition
- DDL
- INSERT
- SELECT
- Conclusions
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
Python driver/sqlalchemy/superset connectors
License
ClickHouse/clickhouse-connect
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
A high performance core database driver for connecting ClickHouse to Python, Pandas, and Superset
- Pandas DataFrames
- Numpy Arrays
- PyArrow Tables
- Superset Connector
- SQLAlchemy 1.3 and 1.4 (limited feature set)
ClickHouse Connect currently uses the ClickHouse HTTP interface for maximum compatibility.
pip install clickhouse-connect ClickHouse Connect requires Python 3.7 or higher.
ClickHouse Connect is fully integrated with Apache Superset. Previous versions of ClickHouse Connect utilized a dynamically loaded Superset Engine Spec, but as of Superset v2.1.0 the engine spec was incorporated into the main Apache Superset project and removed from clickhouse-connect in v0.6.0. If you have issues connecting to earlier versions of Superset, please use clickhouse-connect v0.5.25.
When creating a Superset Data Source, either use the provided connection dialog, or a SqlAlchemy DSN in the form clickhousedb://:@: .
ClickHouse Connect incorporates a minimal SQLAlchemy implementation (without any ORM features) for compatibility with Superset. It has only been tested against SQLAlchemy versions 1.3.x and 1.4.x, and is unlikely to work with more complex SQLAlchemy applications.
The documentation for ClickHouse Connect has moved to ClickHouse Docs
A Python client working example for connecting to ClickHouse Cloud Service
This is a step by step example on how to start using Python with ClickHouse Cloud service.
Keep in mind that Python versions and libraries dependencies are constantly evolving. Make also sure to use the latest supported versions of both the driver and Python environment when trying this.
At the time of writing this article, we’re using the clickhouse-connect driver version 0.5.23 and python 3.11.2 respectively.
Steps
$ mkdir ch-python $ cd ch-python import clickhouse_connect import sys import json CLICKHOUSE_CLOUD_HOSTNAME = 'HOSTNAME.clickhouse.cloud' CLICKHOUSE_CLOUD_USER = 'default' CLICKHOUSE_CLOUD_PASSWORD = 'YOUR_SECRET_PASSWORD' client = clickhouse_connect.get_client( host=CLICKHOUSE_CLOUD_HOSTNAME, port=8443, username=CLICKHOUSE_CLOUD_USER, password=CLICKHOUSE_CLOUD_PASSWORD) print("connected to " + CLICKHOUSE_CLOUD_HOSTNAME + "\n") client.command( 'CREATE TABLE IF NOT EXISTS new_table (key UInt32, value String, metric Float64) ENGINE MergeTree ORDER BY key') print("table new_table created or exists already!\n") row1 = [1000, 'String Value 1000', 5.233] row2 = [2000, 'String Value 2000', -107.04] data = [row1, row2] client.insert('new_table', data, column_names=['key', 'value', 'metric']) print("written 2 rows to table new_table\n") QUERY = "SELECT max(key), avg(metric) FROM new_table" result = client.query(QUERY) sys.stdout.write("query: ["+QUERY + "] returns:\n\n") print(result.result_rows) chpython$ python -m venv venv chpython$ source venv/bin/activate Once loaded, your terminal prompt should be prefixed with (venv), install dependencies:
(venv) ➜ chpython$ pip install -r requirements.txt Collecting certifi Using cached certifi-2023.5.7-py3-none-any.whl (156 kB) Collecting urllib3>=1.26 Using cached urllib3-2.0.2-py3-none-any.whl (123 kB) Collecting pytz Using cached pytz-2023.3-py2.py3-none-any.whl (502 kB) Collecting zstandard Using cached zstandard-0.21.0-cp311-cp311-macosx_11_0_arm64.whl (364 kB) Collecting lz4 Using cached lz4-4.3.2-cp311-cp311-macosx_11_0_arm64.whl (212 kB) Installing collected packages: pytz, zstandard, urllib3, lz4, certifi, clickhouse-connect Successfully installed certifi-2023.5.7 clickhouse-connect-0.5.23 lz4-4.3.2 pytz-2023.3 urllib3-2.0.2 zstandard-0.21.0 (venv) chpython$ venv/bin/python main.py connected to HOSTNAME.clickhouse.cloud table new_table created or exists already! written 2 rows to table new_table query: [SELECT max(key), avg(metric) FROM new_table] returns: [(2000, -50.9035)] If using an older Python version (e.g. 3.9.6 ) you might be getting an ImportError related to urllib3 library. In that case either upgrade your Python environment to a newer version or pin the urllib3 version to 1.26.15 in your requirements.txt file.
Introduction

ClickHouse is one of the fastest opensource databases in the market and it claims to be faster than Spark. At WhiteBox we’ve tested this hypothesis with a +2 billion rows table and we can assure you it is! Our tests performed 3x faster for a complex aggregation with several filters.
Regarding this tutorial, all code and steps in this post has been tested in May 2021 and Ubuntu 20.04 OS, so please don’t be evil and don’t complain if the code does not work in September 2025 😅.
Requirements
The requirements for this integration are the following:
ClickHouse server: It can be installed quite easily following the official documentation. Current version (21.4.5.46).
Python libraries:
- SQLAlchemy: It can be installed using pip install SQLAlchemy==1.3.24.
- clickhouse-sqlalchemy: It can be installed using pip install clickhouse-sqlalchemy==0.1.6. There is another library “sqlalchemy-clickhouse”, but it does not support most of SQLAlchemy magic.
Setup
ClickHouse installation
This tutorial can be tested against any ClickHouse database. However, in order to get a local ClickHouse database to test the integration, it can be easily installed following the steps below:
sudo apt-get install apt-transport-https ca-certificates dirmngr
sudo apt-key adv —keyserver hkp://keyserver.ubuntu.com:80 —recv E0C56BD4
echo «deb https://repo.clickhouse.tech/deb/stable/ main/» | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y clickhouse-server clickhouse-client
sudo service clickhouse-server start
Running command “clickhouse-client” on the shell ensure you that your ClickHouse installation is properly working. Besides, it can help you debug the SQLAlchemy DDL.
Python environment
These are the Python libraries that are required to run the all the code in this tutorial:
Integration
SQLAlchemy setup
The following lines of code perform the SQLAlchemy standard connection:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine(conn_str)
session = sessionmaker(bind=engine)()
DDL
Create a new database
engine.execute(DDL(f’CREATE DATABASE IF NOT EXISTS ‘))
It is possible to test the current databases in ClickHouse from the command line connection using the command “SHOW DATABASES”. The following output should display on screen:
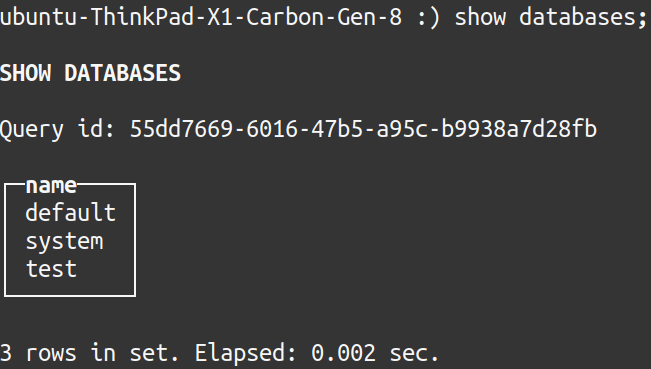
Create a new table
The following steps show how to create a MergeTree engine table in ClickHouse using the SQLAlchemy ORM model.
ORM model definition
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Date
from clickhouse_sqlalchemy import engines
class NewTable(Base):
__tablename__ = ‘new_table’
__table_args__ = (
engines.MergeTree(order_by=[‘id’]),
,
)
id = Column(Integer, primary_key=True)
var1 = Column(String)
var2 = Column(Date)
DDL
A new table should appear in the new database:
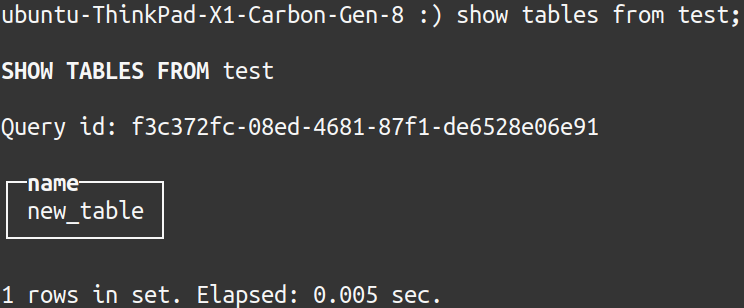
INSERT
for i in range(1000):
row = NewTable(id=i, var1=f’test_str_’, var2=date(2021, 5, 3))
session.add(row)session.commit()
SELECT
Conclusions
Should ClickHouse replace traditional databases like Postgres, MySQL, Oracle? Definitively no. These databases have a lot of features that ClickHouse doesn’t currently have nor it is intended to have in the future (primary key basic concepts, unique columns…). It can be considered an analytics database but not a fully functioning transactional one.
However, ClickHouse speed is so amazing that it should be definitively the GOTO when there is a huge amount of tabular data.